277 lines
56 KiB
Markdown
277 lines
56 KiB
Markdown
|
|
---
|
|||
|
|
title: Dolphin Attack 论文翻译
|
|||
|
|
date: 2021-01-08 11:58:55
|
|||
|
|
tags:
|
|||
|
|
- 硬件攻击
|
|||
|
|
- 传感器
|
|||
|
|
- 语音助手
|
|||
|
|
---
|
|||
|
|
|
|||
|
|
# 海豚音攻击
|
|||
|
|
|
|||
|
|
https://acmccs.github.io/papers/p103-zhangAemb.pdf
|
|||
|
|
https://github.com/USSLab/DolphinAttack
|
|||
|
|
https://zhuanlan.zhihu.com/p/29306026
|
|||
|
|
|
|||
|
|
|
|||
|
|
## Abstract
|
|||
|
|
|
|||
|
|
诸如Siri或Google Now之类的语音识别(SR)系统已经成为一种越来越流行的人机交互方法,并将各种系统转变为语音可控系统(VCS)。先前对VCS进行攻击的工作表明,人们无法理解的隐藏语音命令可以控制系统。隐藏的语音命令尽管是“隐藏的”,但还是可以听到的。在这项工作中,我们设计了一个完全听不见的攻击DolphinAttack,它可以调制超声载波上的语音命令(例如f> 20 kHz),以实现听不清。通过利用麦克风电路的非线性特性,语音识别系统可以成功地解调,恢复调制的低频音频命令,并对其进行更重要的解释。我们在流行的语音识别系统上验证了DolphinAttack,包括Siri,Google Now,三星S Voice,华为HiVoice,Cortana和Alexa。通过注入一系列听不见的语音命令,我们展示了一些概念验证攻击,包括激活Siri以在iPhone上发起FaceTime通话,激活Google Now以将手机切换为飞行模式,甚至操纵导航系统在奥迪汽车上。我们提出了硬件和软件防御解决方案。我们验证通过使用支持向量机(SVM)对音频进行分类来检测DolphinAttack是可行的,并建议重新设计语音可控系统,以应对听不见的语音命令攻击。
|
|||
|
|
|
|||
|
|
关键字:语音可控系统,语音识别,MEMS麦克风,安全分析,防御
|
|||
|
|
|
|||
|
|
## 0x01 Introduction
|
|||
|
|
|
|||
|
|
语音识别(SR)技术允许机器或程序识别口语单词并将其转换为机器可读格式。 由于它的可访问性,效率以及最近在识别精度方面的进步,它已成为越来越流行的人机交互机制。 结果,语音识别系统已将各种各样的系统变成语音可控系统(VCS):Apple Siri [5]和Google Now [21]允许用户通过语音发起电话呼叫; Alexa [4]已使用户能够指示Amazon Echo订购外卖,安排Uber骑行等。随着研究人员将大量精力投入到改善SR系统的性能上,人们对语音识别和语音的了解程度却鲜为人知。 可控系统在故意和偷偷摸摸的攻击下表现良好。
|
|||
|
|
先前的工作[10、61]已经表明,SR系统可以理解人类难以理解的混淆语音命令,因此可以控制系统而不会被检测到。 这些语音命令虽然是“隐藏的”,但仍然可以听见并且仍然很明显。 本文旨在研究难以检测到的攻击的可行性,并且本文受到以下关键问题的驱动:语音命令是否可以被人听不见,而仍然可以被设备听见,并且可以被语音识别系统理解? 注入一系列听不见的语音命令是否会导致语音可控系统出现未注意到的安全漏洞? 为了回答这些问题,我们设计了DolphinAttack,这是一种通过利用超声通道(即f> 20 kHz)和基础音频硬件的漏洞在VCS处注入听不见的语音命令的方法。
|
|||
|
|
由于以下疑问,听不见的语音命令似乎不可行。
|
|||
|
|
(a)设备如何听到听不到的声音?人类声音和听力的上限频率为20 kHz。因此,大多数具有音频功能的设备(例如电话)采用低于44 kHz的音频采样率,并应用低通滤波器来消除高于20 kHz的信号[32]。先前的工作[61]认为不可能接收20 kHz以上的声音。
|
|||
|
|
(b)SR系统如何理解听不见的声音?即使超声被硬件接收并正确采样,SR系统也不会识别与人的音调特征不匹配的信号,因此无法解释命令。
|
|||
|
|
(c)听不见的声音如何导致VCS发生未注意到的安全漏洞?控制VCS的第一步是激活它们。许多VCS(例如,智能手机和智能家居设备)实现了始终在线功能,该功能可通过依赖于说话者的唤醒词来激活它们,即,此类系统利用语音识别来认证用户。随机语音命令不会通过语音识别。
|
|||
|
|
我们解决了所有这些问题,并且我们证明了DolphinAttack语音命令虽然完全听不见,因此对于人类来说是听不见的,但是它们可以被设备的音频硬件接收,并且可以被语音识别系统正确理解。我们在主要的语音识别系统上验证了DolphinAttack,包括Siri,Google Now,三星S Voice [43],华为HiVoice [65],Cortana [37]和Alexa。
|
|||
|
|
无法听见的语音命令质疑通用设计假设,即对手最多只能尝试以语音方式操纵VCS,并且可以被警报用户检测到。 此外,我们通过询问以下内容来表征这种假设的安全后果:一系列听不见的语音命令可以在多大程度上危害VCS的安全性。 为了说明这一点,我们展示了DolphinAttack可以完全通过一系列听不见的语音命令来实现以下偷偷摸摸的攻击:
|
|||
|
|
(1)访问恶意网站。 该设备可以打开一个恶意网站,该网站可以发起按下载驱动器攻击或利用具有0天漏洞的设备。
|
|||
|
|
(2)间谍。 攻击者可以使受害设备发起视频/电话呼叫,因此可以访问设备周围的图像/声音。
|
|||
|
|
(3)注入虚假信息。 攻击者可以指示受害设备发送虚假的文本消息和电子邮件,发布虚假的在线帖子,向日历中添加虚假的事件等。
|
|||
|
|
(4)拒绝服务。 对手可能会注入命令以开启飞行模式,从而断开所有无线通信。
|
|||
|
|
(5)隐藏攻击。 屏幕显示和语音反馈可能会暴露攻击。 对手可以通过调暗屏幕和降低音量来降低失败率。
|
|||
|
|
我们已经在16种VCS型号上测试了这些攻击,包括Apple iPhone,Google Nexus,Amazon Echo和汽车。 每次攻击至少在一个SR系统上成功。 我们认为该列表到目前为止还不够全面。 尽管如此,它还是一个预警,可以重新考虑在语音可控系统中应支持哪些功能和人类交互级别。
|
|||
|
|
总而言之,我们的贡献如下:
|
|||
|
|
•我们展示了DolphinAttack,它可以利用无法听见的声音和音频电路的特性,在最先进的语音识别系统中注入隐蔽的语音命令。 我们在16个常见的语音可控系统平台上的7种流行语音识别系统(例如Siri,Google Now,Alexa)上验证了DolphinAttack。
|
|||
|
|
•我们证明了对手可以注入一系列听不见的语音命令来激活始终在线的系统并实现各种恶意攻击。 经过测试的攻击包括在iPhone上启动Facetime,在Amazon Echo上播放音乐以及操纵奥迪汽车中的导航系统。
|
|||
|
|
•我们建议同时使用基于硬件和基于软件的防御策略来减轻攻击,并提供增强语音可控系统安全性的建议。
|
|||
|
|
|
|||
|
|
## 0x02 背景和威胁模型
|
|||
|
|
|
|||
|
|
在本节中,我们介绍流行的语音可控系统,并以MEMS麦克风为重点讨论它们的体系结构。
|
|||
|
|

|
|||
|
|
### 2.1 语音可控系统VCS
|
|||
|
|
|
|||
|
|
一个典型的语音可控系统由三个主要子系统组成:语音捕获,语音识别和命令执行,如图1所示。语音捕获子系统记录环境语音,这些环境语音在被传递到 语音识别子系统之前被放大,过滤和数字化。然后,首先对原始捕获的数字信号进行预处理,以去除超出声音范围的频率,并丢弃包含声音太弱而无法识别的信号段。 接下来,处理后的信号进入语音识别系统。
|
|||
|
|
通常,语音识别系统在两个阶段工作:激活和识别。在激活阶段,系统无法接受任意语音输入,但会等待激活。要激活系统,用户必须说出预定义的唤醒词或按特殊键。例如,Amazon echo将“ Alexa”作为激活唤醒词。按住主屏幕按钮约一秒钟可以激活Apple Siri,如果启用了“ Allow Hey Siri”功能,则可以通过“ Hey Siri”激活。要识别唤醒词,麦克风会继续录制环境声音,直到发出声音为止。然后,系统将使用与说话者无关或与说话者无关的语音识别算法来识别语音。例如,只要声音清晰且响亮,Amazon Echo就会采用与说话者无关的算法,并接受任何人说的“ Alexa”。相比之下,Apple Siri取决于扬声器。 Siri需要接受用户培训,并且仅接受同一个人的“ Hey Siri”。激活后,SR系统将进入识别阶段,通常将使用与说话者无关的算法将语音转换为文本,即本例中的命令。
|
|||
|
|
请注意,与说话者相关的SR通常在本地执行,与说话者无关的SR通过云服务执行[28]。 要使用云服务,已处理的信号将发送到服务器,服务器将提取特征(通常为Mel频率倒谱系数[10、27、62])并通过机器学习算法(例如,隐马尔可夫模型或神经网络)识别命令 网络)。 最后,命令被发回。
|
|||
|
|
给定已识别的命令,命令执行系统将启动相应的应用程序或执行操作。 可接受的命令和相应的动作取决于系统,并且是预先定义的。 流行的语音可控系统包括智能手机,可穿戴设备,智能家居设备和汽车。 智能手机允许用户通过语音命令执行广泛的操作,例如拨打电话号码,发送短信,打开网页,将手机设置为飞行模式等。现代汽车接受一系列精心设计的语音命令来激活 并控制一些车载功能,例如GPS,娱乐系统,环境控制和手机。 例如,如果识别出“呼叫1234567890”,则汽车或智能手机可能会开始拨打电话号码1234567890
|
|||
|
|
关于语音可控系统的许多安全性研究都集中于攻击语音识别算法[10]或命令执行环境(例如恶意软件)。 本文针对语音捕获子系统,将在下一部分中对其进行详细介绍。
|
|||
|
|
|
|||
|
|
### 2.2 麦克风
|
|||
|
|
|
|||
|
|
语音捕获子系统记录可听见的声音,并且主要是麦克风,其是将空气传播的声波(即声音)转换为电信号的换能器。最古老和最受欢迎的麦克风之一是电容式麦克风,它通过容量变化将声波转换为电信号。驻极体电容式麦克风(ECM)和微机电系统(MEMS)[2、3、29、52、53]版本都可以在市场上购买。由于微型封装尺寸和低功耗,MEMS麦克风主导了语音可控设备,包括智能手机,可穿戴设备。因此,本文主要关注MEMS麦克风,并将简要报告有关ECM的结果。不过,MEMS和ECM的工作原理相似。如图2(b)所示,MEMS麦克风包含薄膜(可移动板)和互补的带孔背板(固定板)[54]。在存在声波的情况下,由声波引起的气压穿过背板上的孔并到达隔膜,该隔膜是一种薄的固体结构,可响应气压的变化而弯曲[64]。这种机械变形导致电容变化。由于电容器上保持几乎恒定的电荷,因此电容变化将产生交流信号。这样,气压被转换成电信号以进行进一步处理。类似地,如图2(a)所示,ECM麦克风利用由柔性膜和固定板形成的电容来记录声波。
|
|||
|
|

|
|||
|
|
语音捕获子系统中的麦克风,低通滤波器(LPF)和ADC旨在捕获可听声音,所有这些功能都旨在抑制超出可听声音频率范围(即20 Hz至20 kHz)的信号。 根据数据表,麦克风的灵敏度频谱在20 Hz至20 kHz之间,理想情况下,应过滤任何其他频率范围内的信号。 即使麦克风记录了高于20 kHz的信号,LPF也应将其删除。 最后,ADC的采样率通常为44.1 kHz,根据奈奎斯特采样定理,数字化信号的频率被限制在22 kHz以下。
|
|||
|
|
|
|||
|
|
### 2.3威胁模型
|
|||
|
|
|
|||
|
|
攻击者的目标是在用户不知情的情况下将语音命令注入到语音可控系统中,并执行未经身份验证的操作。我们假设对手无法直接访问目标设备,拥有自己的传输声音信号的设备,并且无法要求所有者执行任何任务。
|
|||
|
|
|
|||
|
|
* 没有目标设备访问权限。我们假设对手可以针对她选择的任何语音可控系统,但她无法直接访问目标设备。她无法实际触摸它们,更改设备设置或安装恶意软件。但是,我们假设她完全了解目标设备的特性。可以通过首先获取设备模型,然后在发起攻击之前分析相同模型的设备来获得此类知识。
|
|||
|
|
* 没有所有者交互。我们假设目标设备可能在所有者附近,但可能没有在使用中并且不引起注意(例如,在桌子的另一侧,屏幕遮盖的地方或放在口袋中)。此外,设备可能无人看管,这可能在所有者暂时不在时(例如,将Amazon Echo留在房间中)发生。或者,设备可能被盗,对手可能会尝试各种可能的方法来解锁屏幕。但是,对手不能要求所有者执行任何操作,例如按下按钮或解锁屏幕。
|
|||
|
|
* 听不见。由于对手的目标是在不被检测到的情况下注入语音命令,因此她将使用人类听不到的声音,即超声波(f> 20 kHz)。请注意,我们没有使用高频声音(18 kHz <f <20 kHz),因为它们仍然可以被孩子听到。
|
|||
|
|
* 攻击装备。我们假设对手既可以获取用于发射超声波的扬声器,也可以获取用于播放声音的商品设备。攻击者在目标设备附近。例如,她可能会在受害人的桌子或家附近秘密地留下一个可远程控制的扬声器。或者,她可能在受害者走动时携带便携式扬声器。
|
|||
|
|
|
|||
|
|
## 0x03 可行性分析
|
|||
|
|
|
|||
|
|
DolphinAttack的基本思想是(a)在空中传输之前在超声载波上调制低频语音信号(即基带),以及(b)在接收器处用语音捕获硬件对调制后的语音信号进行解调。由于我们无法控制语音捕获硬件,因此我们必须以一种可以使用语音捕获硬件将其解调为基带信号的方式来调制信号。假设麦克风模块始终利用LPF抑制不想要的高频信号,则解调应在LPF之前完成。
|
|||
|
|
由于语音捕获硬件的信号路径从麦克风,一个或多个放大器LPF到ADC开始,因此解调的潜在组件是麦克风和放大器。我们研究了完成DolphinAttack的原理。尽管诸如放大器之类的电子组件被设计为线性的,但实际上它们表现出非线性。利用这种非线性特性,电子元件能够创建新的频率[25]。尽管已经报道并利用了放大器模块的非线性,但包括ECM麦克风和MEMS麦克风在内的麦克风是否具有这种特性仍是未知的。
|
|||
|
|
为了进行研究,我们首先在理论上对麦克风模块的非线性建模,然后显示非线性对实际麦克风模块的影响。
|
|||
|
|
|
|||
|
|
### 3.1非线性效应建模
|
|||
|
|
|
|||
|
|
麦克风将机械声波转换为电信号。 从本质上讲,麦克风可以粗略地视为在输入/输出信号传输特性中具有平方律非线性的组件[1、13]。 众所周知,放大器具有非线性特性,可以产生低频范围内的解调信号[20]。 在本文中,我们研究了麦克风的非线性,可以将其建模如下。 假设输入信号为sin(t),输出信号sout(t)为:
|
|||
|
|
|
|||
|
|
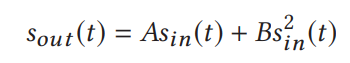
|
|||
|
|
其中A是输入信号的增益,B是二次项s2 in的增益。线性分量采用频率为f的正弦输入信号,并输出具有相同频率f的正弦信号。 相比之下,电气设备的非线性会产生谐波和叉积2。尽管通常将它们视为不希望的失真[31],但具有非线性的设备能够生成新的频率,并且通过精心设计的输入信号,它们可以将信号下变频为 以及恢复基带信号。
|
|||
|
|
假设所需的语音控制信号为m(t),我们选择中心频率为fc的载波上的调制信号为
|
|||
|
|
|
|||
|
|
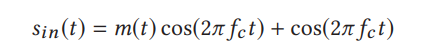
|
|||
|
|
即,使用幅度调制。 不失一般性,设m(t)为简单基调,即m(t)= cos(2πfmt)。 应用等式后。 (2)至 (1)并进行傅立叶变换,我们可以确认输出信号包含预期的频率分量fm以及sin的基本频率分量(即fc-fm,fc + fm和fc),谐波和其他交叉 乘积(即fm,2(fc-fm),2(fc + fm),2fc,2fc + fm和2fc-fm)。 经过LPF后,所有高频成分将被删除,而fm频率成分将保留下来,从而完成了下变频,如图3所示。
|
|||
|
|
|
|||
|
|
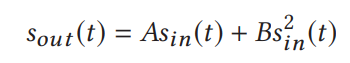
|
|||
|
|
|
|||
|
|
### 3.2 非线性效应评估
|
|||
|
|
|
|||
|
|
考虑到麦克风模块非线性效应的理论计算及其对调制后输入信号的影响,在本节中,我们将验证对真实麦克风的非线性效应。我们测试两种类型的麦克风:ECM和MEMS麦克风。
|
|||
|
|
|
|||
|
|
3.2.1 实验设置
|
|||
|
|
实验设置如图5所示。我们使用iPhone SE智能手机生成2 kHz语音控制信号,即基带信号。然后将基带信号输入到矢量信号发生器[57],该信号发生器将基带信号调制到载波上。经功率放大器放大后,调制信号由高质量的全频带超声扬声器Vifa传输[9]。请注意,我们选择的载波范围为9 kHz至20 kHz,因为信号发生器无法生成低于9 kHz频率的信号。
|
|||
|
|
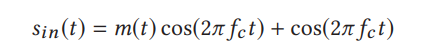在接收器端,我们测试了从耳机中提取的ECM麦克风和ADMP401 MEMS麦克风[16]。如图5所示,ADMP401麦克风模块包含一个前置放大器。为了了解麦克风的特性,我们测量了麦克风而不是前置放大器输出的信号。
|
|||
|
|
|
|||
|
|
3.2.2 结果
|
|||
|
|
我们使用两种信号来研究非线性:单音和多音语音。
|
|||
|
|
单音: 图4显示了当我们使用20 kHz载波时的结果,这证实了麦克风的非线性有助于解调基带信号。前两个图显示了来自扬声器的原始信号的时域和频域,从而很好地显示了载波频率(20 kHz)和上边带以及下边带(20±2 kHz)。第二行中的两个图显示了来自MEMS麦克风的输出信号,下面两个图显示了来自ECM麦克风的输出信号。即使信号被衰减,尤其是对于ECM麦克风,两个麦克风在频域中的基带(2 kHz)仍能证实解调成功。请注意,频域图包含多个高频谐波,这些谐波将被LPF过滤,并且不会影响语音识别。
|
|||
|
|
|
|||
|
|

|
|||
|
|
声音: 尽管我们可以成功地解调出信号音,但语音是各种频率下无数音调的混合,并且未知解调后的语音信号是否仍与原始信号相似。因此,我们计算了三个“ Hey”声音片段中的Mel频率倒谱系数(MFCC),这是声音使用最广泛的功能之一:(a)由文本语音转换(TTS)引擎生成的原始语音,(b)三星Galaxy S6 Edge以iPhone 6 plus录制的语音播放了原始TTS语音,以及(c)三星S6 Edge以TTS语音调制的语音由全频带超声扬声器调制和播放Vifa [9]。如图6所示,这三种情况的MFCC都是相似的。为了量化相似度,我们计算了原始和记录之间的梅尔倒谱失真(MCD),情况(b)为3.1,情况(c)为7.6。 MCD量化两个MFCC之间的失真,数值越小越好。通常,如果两个语音的MCD值小于8 [23],则认为它们可以被语音识别系统接受,因此结果鼓励我们对DolphinAttack针对语音可控系统进行进一步的研究。
|
|||
|
|
|
|||
|
|

|
|||
|
|
|
|||
|
|
## 4 攻击设计
|
|||
|
|
|
|||
|
|
DolphinAttack利用听不见的语音注入来静默控制VCS。由于攻击者几乎无法控制VCS,因此成功进行攻击的关键是在攻击发送方生成听不见的语音命令。特别是,DolphinAttack必须为VCS的激活和识别阶段生成语音命令的基带信号,对基带信号进行调制,以便可以在VCS上对其进行有效解调,并设计一种可以在任何地方启动DolphinAttack的便携式发射机。 DolphinAttack的基本构建模块如图7所示,我们将在以下小节中讨论这些细节。在不失一般性的前提下,我们通过使用Siri作为案例研究来讨论设计细节,并且该技术可以轻松地应用于其他SR系统(例如Google Now,HiVoice)。
|
|||
|
|
|
|||
|
|
### 4.1语音命令生成
|
|||
|
|
|
|||
|
|
Siri的工作分为两个阶段:激活和识别。它在接受语音命令之前需要激活,因此我们生成两种类型的语音命令:激活命令和常规控制命令。为了控制VCS,DolphinAttack必须在注入常规控制命令之前生成激活命令。
|
|||
|
|
|
|||
|
|
4.1.1 激活命令生成。
|
|||
|
|
成功的激活命令必须满足两个要求:(a)包含唤醒词“ Hey Siri”,以及(b)调成接受Siri训练的用户的特定语音。创建具有这两个要求的激活命令具有挑战性,除非攻击者在附近并设法创建清晰的记录时用户碰巧说“ Hey Siri”。实际上,攻击者最多可以偶然记录任意单词。如果可能的话,使用现有的语音合成技术[38]和从录音中提取的特征来生成特定语音的“嘿Siri”是极其不同的,因为目前尚不清楚Siri使用哪些特征集进行语音识别。因此,我们设计了两种方法来分别针对两种情况生成激活命令:(a)攻击者找不到Siri的所有者(例如,攻击者获得了被盗的智能手机),以及(b)攻击者可以获得一些录音主人的声音。
|
|||
|
|
(1)基于TTS的蛮力。 TTS技术的最新进展使将文本转换为语音变得容易。 因此,即使攻击者没有机会从用户那里获得任何语音记录,攻击者也可以通过TTS(文本到语音)系统生成一组包含唤醒词的激活命令。 观察到的启发是,具有相似声调的两个用户可以激活另一个人的Siri。 因此,只要集合中的激活命令之一具有与所有者足够接近的声音,就足以激活Siri。 在DolphinAttack中,我们借助现有的TTS系统(如表1所示)准备了一组具有各种音调和音色的激活命令,其中包括Selvy Speech,Baidu,Google等。总共,我们获得了90种类型的TTS 声音。 我们选择Google TTS语音来训练Siri,其余的用于攻击
|
|||
|
|
|
|||
|
|

|
|||
|
|
(2)级联综合。当攻击者可以录制来自Siri所有者的几个单词但不是必需的“嘿Siri”时,我们建议通过从可用录制中的其他单词中搜索相关的音素来合成所需的语音命令。英文大约有44个音素,而唤醒字“嘿Siri”使用6个音素(即HH,EY,S,IH,R,IY)。许多单词的发音与“ Hey”或“ Si”或“ ri”相同,可以将它们拼接在一起。例如,我们可以将“ he”和“ cake”连接起来以获得“ Hey”。同样,“ Siri”可以是“城市”和“携带”的组合。如图8所示,我们首先在记录的句子中搜索单个或组合的音素,然后如果找到匹配项,则提取感兴趣的片段。最后,将匹配的音素组合在一起。为了评估该方案的可行性,我们进行了以下实验。我们使用Google TTS生成用于训练SR系统的“ Hey Siri”,并生成两组候选语音以合成“ Hey Siri”:1.“ he”,“ cake”,“ city”,“ carry”; 2.“he is a boy”, “eat a cake”, “in the city”, “read after me”。合成激活命令后,我们使用如图5所示的相同实验设置在iPhone 4S上对其进行测试。两个合成的“ Hey Siri”都可以成功激活Siri。
|
|||
|
|
|
|||
|
|

|
|||
|
|
|
|||
|
|
4.1.2 通用控制命令生成。
|
|||
|
|
常规控制命令可以是启动应用程序(例如,“拨打911”,“打开www.google.com”)或配置设备(例如,“开启飞行模式”)的任何命令。与激活命令不同,SR系统不会验证控制命令的身份。因此,攻击者可以选择任何控制命令的文本,并利用TTS系统生成命令。
|
|||
|
|
|
|||
|
|
4.1.3 评估。
|
|||
|
|
我们测试激活和控制命令。在不失一般性的前提下,我们通过利用Tab中总结的TTS系统生成激活和控制命令。 1.特别是,我们从这些TTS系统的网站上下载了两个语音命令:“ Hey Siri”和“ call 1234567890”。对于激活,我们使用Google TTS系统中的“ Hey Siri”来训练Siri,其余的用于测试。我们通过iPhone 6 Plus和台式设备播放语音命令(如图5所示),并在iPhone 4S上进行测试。选项卡中汇总了这两个命令的激活和识别结果。结果表明,SR系统可以识别来自任何TTS系统的控制命令。在89种类型的激活命令中,有35种可以激活Siri,成功率为39%。
|
|||
|
|
|
|||
|
|
|
|||
|
|
### 4.2 语音命令调制
|
|||
|
|
|
|||
|
|
生成语音命令的基带信号后,我们需要在超声载波上对其进行调制,以使它们听不到。 为了利用麦克风的非线性,DolphinAttack必须利用幅度调制(AM)。
|
|||
|
|
|
|||
|
|
4.2.1 AM调制参数。
|
|||
|
|
在AM中,载波的幅度与基带信号成比例地变化,并且幅度调制产生一个信号,其功率集中在载波频率和两个相邻的边带上,如图9所示。 描述如何在DolphinAttack中选择AM参数。
|
|||
|
|
(1)深度:调制深度m定义为m = M / A,其中A是载波幅度,M是调制幅度,即,M是幅度从其未调制值起的峰值变化。 例如,如果m = 0.5,则载波幅度在其未调制电平之上(或之下)变化50%。 调制深度与麦克风非线性效应的利用直接相关,我们的实验表明,调制深度与硬件有关(在第5节中有详细介绍)。
|
|||
|
|
(2)载波频率。载波频率的选择取决于几个因素:超声波的频率范围,基带信号的带宽,低通滤波器的截止频率以及VCS上麦克风的频率响应以及频率攻击者的回应。调制信号的最低频率应大于20 kHz,以确保听不见。假设语音命令的频率范围为w,则载波频率fc必须满足fc-w> 20 kHz的条件。例如,假设基带的带宽为6 kHz,则载波频率必须大于26 kHz,以确保最低频率大于20 kHz。人们可能会考虑使用20 kHz以下的载波,因为这些频率对于大多数人来说是听不到的,除了小孩。但是,这样的载波(例如,<20kHz)将无效。这是因为,当载波频率和下边带低于低通滤波器的截止频率时,它们将不会被滤波。因此,恢复的语音不同于原始信号,并且语音识别系统将无法识别命令。 类似于许多电子设备,麦克风是频率选择性的,例如,各种频率下的增益会变化。为了提高效率,载波频率应是扬声器和VCS麦克风上增益最高的乘积。为了发现最佳载波频率,我们测量扬声器和麦克风的频率响应,即,在相同的激励下,我们测量各种频率下的输出幅度。图10显示了Samsung Galaxy S6 Edge 3上的ADMP 401 MEMS麦克风和扬声器的频率响应。麦克风和扬声器的增益不一定随频率的增加而降低,因此有效载波频率可能不会单调。
|
|||
|
|
(3)语音选择。 各种声音映射到各种基带频率范围。 例如,女性语音通常具有比男性语音更宽的频带,这导致在可听频率范围内频率泄漏的可能性更大,即,调制信号的最低频率可以小于20kHz。 因此,如果可能,应选择带宽较小的语音以创建基带语音信号
|
|||
|
|

|
|||
|
|
|
|||
|
|

|
|||
|
|
|
|||
|
|
### 4.3 语音命令发送器
|
|||
|
|
|
|||
|
|
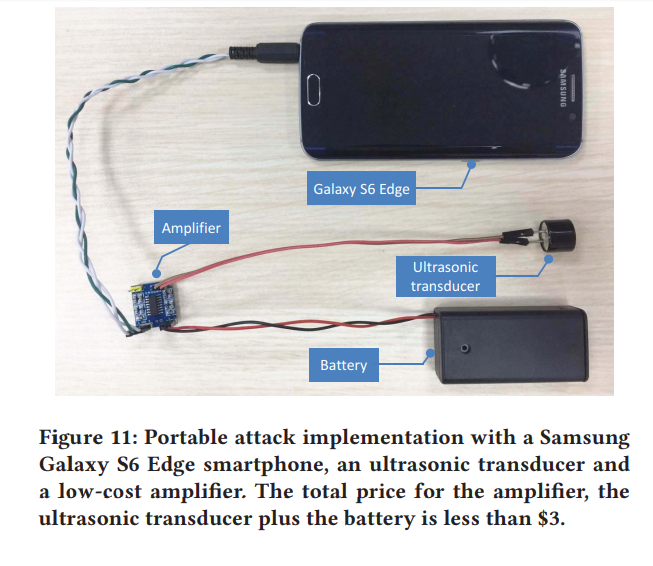
我们设计了两个发射器:(a)由专用信号发生器驱动的强大发射器(如图5所示),以及(b)由智能手机驱动的便携式发射器(如图11所示)。 我们利用第一个来验证和量化DolphinAttack可以完成各种听不见的语音命令的程度,而我们使用第二个来验证步行攻击的可行性。 这两个发射机均由三个组件组成:信号源,调制器和扬声器。 信号源产生原始语音命令的基带信号,并输出到调制器,该调制器以幅度调制(AM)的形式将语音信号调制到频率为fc的载波上。 最后,扬声器将调制后的信号转换成声波,并请注意扬声器的采样率必须大于2(fc + w),以避免信号混叠。
|
|||
|
|
|
|||
|
|
|
|||
|
|
4.3.1 具有信号发生器的强大变送器
|
|||
|
|
我们将智能手机用作信号源,并将图5中描述的矢量信号发生器用作调制器。请注意,信号发生器的采样范围为300 MHz,远大于超声频率,并且可以使用预定义的参数调制信号。功能强大的发射器的扬声器是名为Vifa [9]的宽带动态超声扬声器。
|
|||
|
|
|
|||
|
|
4.3.2 带有智能手机的便携式变送器
|
|||
|
|
便携式发射器利用智能手机来发射调制信号。因为我们发现许多设备的最佳载波频率都大于24 kHz,如表3所示。 大多数智能手机无法完成任务。大多数智能手机最多支持48 kHz采样率,并且只能发送载波频率最高为24 kHz的调制窄带信号。为了构建适用于各种VCS的便携式发射器,我们购买了三星Galaxy S6 Edge,它支持高达192 kHz的采样率。不幸的是,三星Galaxy S6的车载扬声器会衰减频率大于20 kHz的信号。为了减轻这个问题,我们使用窄带超声换能器[56]作为扬声器,并在超声换能器之前添加了一个放大器,如图11所示。这样,有效的攻击范围得以扩展。
|
|||
|
|

|
|||
|
|
|
|||
|
|
## 5 VCS的可行性实验
|
|||
|
|
|
|||
|
|
我们在16种流行的语音可控系统和7种语音识别系统上通过实验验证了DolphinAttack,并寻求以下三个问题的答案:(a)攻击是否会针对各种操作系统和硬件平台上的不同语音识别系统起作用? (b)不同的软件和硬件如何影响攻击的性能? (c)成功实施攻击的关键参数是什么? 本部分详细介绍了实验设计,设置和结果。
|
|||
|
|
|
|||
|
|
### 5.1 系统选择
|
|||
|
|
|
|||
|
|
我们检查了针对各种先进的语音识别系统和现成的VCS的DolphinAttack攻击,这些攻击已在Tab 3.中列出。 该列表并非旨在详尽无遗,而是提供了一组具有代表性的VCS,可以尽我们最大的努力进行实验。
|
|||
|
|
我们选择目标系统的方法是双重的-软件和硬件。首先,我们选择可公开使用的主要语音识别系统,例如Siri,Google Now,Alexa,Cortana等。与普通软件不同,SR系统(尤其是专有系统)高度依赖硬件和操作系统。例如,只能在Apple产品上找到和使用Siri。 Alexa仅限于Amazon设备; Cortana仅在Windows计算机上运行。尽管如此,我们还是选择了与SR系统兼容的硬件并进行了实验。为了探究硬件对攻击性能的影响,我们检查了运行同一SR系统的不同硬件模型(例如,各代iPhone上的Siri)受到的攻击。
|
|||
|
|
总而言之,我们选择在活跃用户的消费市场上流行的VCS和SR系统,并涵盖各种应用领域和使用场景。在标签页中。参见Tab 3.,我们总结了用于实验的所选VCS,可以将其分为三类-个人设备(可穿戴设备,智能手机,平板电脑,计算机),智能家居设备和车辆。
|
|||
|
|
|
|||
|
|
### 5.2 实验设置
|
|||
|
|
|
|||
|
|
我们使用相同的实验设置和设备测试对所选语音可控系统和语音识别系统的攻击,并在注入具有三个目标的不可听的语音命令时报告其行为:
|
|||
|
|
|
|||
|
|
* 检查攻击的可行性。
|
|||
|
|
* 量化参数以调整成功的攻击。
|
|||
|
|
* 测量攻击性能。
|
|||
|
|
|
|||
|
|
|
|||
|
|
设备: 除非另有说明,否则所有实验均使用默认的实验设备:如图5所示的功能强大的发射器,其中包括智能手机作为信号源,信号发生器作为调制器以及名为Vifa的宽带动态超声扬声器[9]。 作为扬声器播放听不见的语音命令。 由于功能强大的发射器能够以多种载波(从9 kHz到50 kHz)发射信号,因此我们将其用于可行性研究。 相比之下,便携式发射机使用窄带扬声器,其传输频率受到可用的窄带扬声器的限制。 在我们的情况下,我们的便携式发射机可以以23 kHz,25 kHz,33 kHz,40 kHz和48 kHz的频率发送信号。
|
|||
|
|
|
|||
|
|
设定:除非受到设备尺寸的限制,否则我们会将选定的设备放在台式攻击设备前面,并且桌子上的距离各不相同,并且设备麦克风朝向扬声器。将设备和扬声器都升高到相同的高度(即在桌子上方10厘米),以避免机械耦合。除带有汽车的测试外,所有实验均在我们的实验室中进行,平均背景噪声为55 dB SPL(声压级),并且我们确认在测试频段(20 kHz – 50 kHz)中没有干扰声。我们通过功能强大的发射器播放听不见的语音命令,并在设备屏幕或设备声学响应中观察结果。通常,设备上安装了多个麦克风以拾取来自各个方向的声音。通常所有麦克风都用于语音识别。在我们的实验中,我们专门测试了显示最佳解调效果的设备。
|
|||
|
|
|
|||
|
|
语音命令: 针对两种类型的攻击(激活和识别)准备了两种语音命令。 对于那些支持语音激活的系统,我们尝试使用听不见的唤醒单词命令激活它们。 要检查语音识别系统是否可以正确识别听不见的语音命令,我们选择了一些可以理解的英语命令,如Tab 2中所示。 由于所有设备均不支持任何命令,因此我们准备了一组命令来覆盖所有设备。 对于每个命令,我们尝试两种音频来源:来自TTS引擎的合成声音,以及作者所说的真实人类声音。
|
|||
|
|
|
|||
|
|

|
|||
|
|
声压级:尽管为攻击而产生的声音是人类无法听到的,但是我们仍然使用自由场测量麦克风[50]以分贝为单位测量声压级(SPL)。 在距Vifa [9]扬声器10 cm处测量的超声接收声压级为125 dB。
|
|||
|
|
|
|||
|
|
攻击:在识别攻击中,SR系统是事先手动激活的。 在激活攻击中,不允许与设备进行物理交互。 仅当从SR系统识别的文本与攻击命令完全匹配时,才认为攻击成功,并且仅记录距离。
|
|||
|
|
|
|||
|
|
调制参数: 我们认为调制参数可能会影响攻击性能。 我们考虑幅度调制中的两个因素:载波频率fc和调制深度。 为了量化其影响,我们使用Google TTS引擎作为基带音频源,将设备放置在距宽带超声扬声器Vifa [9] 10 cm处,并测量三个值:(a)fc range-载波范围 成功进行识别攻击且100%准确的频率。 (b)素数fc -解调后展现最高基带4幅度的fc。 (c)AM深度—成功进行识别攻击且100%准确时,在原始fc处的调制深度。
|
|||
|
|
|
|||
|
|
### 5.3 可行性结果
|
|||
|
|
|
|||
|
|
Tab. 3总结实验结果。 从Tab. 3所示,我们可以得出结论,DolphinAttack可与几乎所有经过检查的SR系统和设备一起使用。 特别是,SR系统可以在所有经过测试的硬件上正确解释听不到的语音命令,并且在需要激活的所有VCS上都可以成功激活。 但是,结果确实表明,设备和系统需要各种参数才能实现相同的攻击效果。 我们讨论以下结果:
|
|||
|
|
**硬件依赖性:**DolphinAttack的基本原理是在数字化组件之前注入听不见的语音命令。 因此,DolphinAttack的可行性在很大程度上取决于音频硬件,而不是语音识别系统。 例如,运行Siri的同一制造商的各种设备在攻击成功率,最大攻击距离和调制参数方面显示出很大的差异。 这是因为各种型号采用不同的硬件(例如,麦克风,放大器,滤波器),这导致输入到相同SR系统的数字化音频发生变化。 我们在两个相同设备(iPhone SE)上的实验显示出相似的攻击参数和结果。 因此,攻击者事先研究硬件以获得令人满意的攻击结果是可行的。
|
|||
|
|
**SR系统依赖性:**我们发现,各种SR系统可能会以不同方式处理相同的音频。 我们在运行iPhone SE的Google Chrome中测试了语音搜索。 表3中的结果表明,Google Chrome的fc范围与Siri实验中的fc范围重叠,这表明我们的攻击取决于硬件。 但是,fc,AM深度和识别距离的差异是由SR系统引起的
|
|||
|
|
**识别与激活:**根据攻击距离,各种设备和SR系统对识别和激活攻击的反应可能不同。 对于某些设备(8个设备),可以比识别攻击更大的距离实现激活攻击,而对于其他设备(6个设备),成功激活攻击的有效范围要比识别攻击小。 此外,我们观察到,对于许多设备而言,在控制命令之前附加激活命令(例如“ Hey Siri”)可能会增加正确识别的可能性,这可能是因为SR系统专门对激活命令进行了训练,使之成为可能。 在常开模式下识别。
|
|||
|
|
**命令很重要:** 语音命令的长度和内容会影响成功率和最大攻击距离。 在实验中,我们严格要求要求正确识别命令中的每个单词,尽管某些命令可能不需要这样做。 例如,“呼叫/ FaceTime 1234567890”和“打开dolphinattack.com”比“打开飞机模式”或“今天的天气如何”更难被识别。 在前一种情况下,必须正确识别执行字“ call”,“ open”和内容(数字,url)。 但是,对于后一种情况,仅识别诸如“飞机”和“天气”之类的关键字就足以执行原始命令。 如果攻击命令简短且对于SR系统通用,则可以提高攻击性能。
|
|||
|
|
**载波频率:** fc是影响攻击成功率的主要因素,并且在各个设备之间也显示出很大的差异。对于某些设备,成功进行识别攻击的fc范围可以宽至20-42 kHz(例如iPhone 4s),也可以窄至几个单个频率点(例如iPhone 5s)。我们将这种多样性归因于这些麦克风的频率响应和频率选择性的差异以及音频处理电路的非线性。例如,Nexus 7的fc范围是从24到39 kHz,这可以从两个方面进行解释。 fc不高于39 kHz,因为Vifa扬声器在39 kHz以上的频率响应较低,而Nexus 7麦克风之一也较低。因此,结合起来,高于39 kHz的载波不再足够有效以注入听不见的语音命令。由于麦克风频率响应的非线性,fc不能小于24 kHz。我们观察到,当基带谐波的幅度大于基带之一时,无法听到的语音命令对于SR系统变得不可接受。例如,在给定400 Hz音调的基带的情况下,我们测量Nexus 7上的解调信号(即400 Hz基带),并观察800 Hz(2次谐波),1200 Hz(3次谐波)甚至更高的谐波,这可能是由于音频处理电路的非线性所致。如图12所示,当fc小于23 kHz时,第二和第三谐波要强于第一谐波,这会使基带信号失真并使SR系统难以识别。导致最佳攻击性能的Prime fc是既显示高基带信号又显示低谐波的频率。在Nexus 7上,Prime fc为24.1 kHz
|
|||
|
|

|
|||
|
|
**调制深度:** 调制深度会影响解调后的基带信号的幅度及其谐波,如图13所示。随着调制深度从0%逐渐增加到100%,解调后的信号会变得更强,进而提高SNR和攻击成功率, 除少数例外(例如,当谐波使基带信号失真的程度大于AM深度较低的情况时)。 我们在Tab 3 中报告了对每台设备成功进行识别攻击的最小深度。
|
|||
|
|
攻击距离: 攻击距离从2厘米到最大175厘米不等,并且跨设备差异很大。 值得注意的是,我们在Amazon Echo上两次攻击都可以达到的最大距离为165厘米。 我们认为,可以使用可以产生更高压力水平的声音并表现出更好的声音指向性的设备来增加距离,或者使用更短和更易于识别的命令来增加距离。
|
|||
|
|
**努力与挑战:**在进行上述实验时,我们面临挑战。 除了获取设备以外,由于缺少音频测量反馈界面,因此测量每个参数非常耗时且费力。 例如,为测量Prime fc,我们使用不同平台上的音频频谱分析软件在各种设备上分析解调结果:iOS [30],macOS [34],Android [41]和Windows [35]。 对于不支持安装频谱软件的设备(例如Apple Watch和Amazon Echo),我们利用呼叫和命令日志回放功能,并在另一台中继设备上测量音频。
|
|||
|
|
|
|||
|
|
### 5.4 小结
|
|||
|
|
|
|||
|
|
我们将实验总结如下。 (1)我们验证了跨越16种不同设备和7种语音识别系统的识别和激活攻击,并在几乎所有设备上均获得了成功。 (2)我们测量了所有设备的攻击性能,其中一些设备足以应付日常情况下的实际攻击。 例如,我们可以在距离iPhone 2s和Amazon Echo约2米的地方启动DolphinAttack。 (3)我们测量,检查并讨论了与攻击性能有关的参数,包括SR系统,设备硬件,语音命令,fc,AM深度等。
|
|||
|
|
|
|||
|
|
## 6 影响定量
|
|||
|
|
|
|||
|
|
在本节中,我们将使用功能强大的发射器(即,图5中所示的台式机设置),根据语言,背景噪声,声压级和攻击距离评估DolphinAttack的性能。 此外,我们评估了使用便携式设备进行的漫游攻击的有效性。
|
|||
|
|
|
|||
|
|
### 6.1 语言的影响
|
|||
|
|
|
|||
|
|
为了检查DolphinAttack在语言方面的有效性,我们选择了五种语言中的三个语音命令。语音命令包括激活命令(“ Hey Siri”)和两个控制命令(“ Call 1234567890”和“ Turn onplane mode”),代表针对SR系统的三种攻击:激活SR系统,启动对用户的监视,和拒绝服务攻击。每个语音命令分别以英语,中文,德语,法语和西班牙语进行测试。我们针对与运行iOS 10.3.1的iPhone 6 Plus配对的Apple Watch推出DolphinAttack。对于每种语言的每种语音命令,我们将其重复10次并计算平均成功率。距离设置为20 cm,测得的背景噪声为55 dB。我们利用25 kHz载波频率和100%AM深度。图14示出了给定语言的三个语音命令的识别结果。我们可以看到,各种语言和语音命令的识别率几乎相同。特别地,英语和西班牙语中所有语音命令的识别率均为100%,并且三种语音命令在所有语言中的平均识别率分别为100%,96%和98%。此外,用于激活的识别率(即,“嘿Siri”)高于控制命令“呼叫1234567890”和“打开飞机模式”之一。这是因为激活命令的长度比控制命令的长度短。无论如何,结果表明我们的方法对于各种语言和语音命令都是有效的。
|
|||
|
|
|
|||
|
|

|
|||
|
|
|
|||
|
|
### 6.2 背景噪声的影响
|
|||
|
|
|
|||
|
|
众所周知,语音识别对背景噪声敏感,建议在安静的环境中使用。因此,我们在以下三种情况下检查了通过DolphinAttack发出的听不见的语音命令注入:在办公室,咖啡馆,在街上。为确保实验可重复,我们通过以选定的SPL播放背景声音来模拟这三种情况,并评估它们对识别率的影响。我们选择Apple Watch作为攻击目标,并通过迷你声级计测量背景噪音。从表4可以看出,激活命令的识别率在所有三个场景中均超过90%,而控制命令(“飞机飞行模式”)的识别率则随着环境噪声水平的提高而降低。这是因为激活命令比控制命令短。随着控制命令的单词数增加,由于无法识别任何单词可能导致命令识别失败,因此识别率迅速下降。
|
|||
|
|
|
|||
|
|

|
|||
|
|
|
|||
|
|
### 6.3 声压级的影响
|
|||
|
|
|
|||
|
|
对于可听和不可听的声音,较高的SPL会导致录制的语音质量更高,从而识别率也更高。这是因为对于给定的噪声水平,较高的SPL始终意味着较大的信噪比(SNR)。为了探索SPL对DolphinAttack的影响,我们在Apple Watch和Galaxy S6 Edge智能手机上测试了控制命令(“ Call 1234567890”)。在所有实验中,将扬声器放置在距目标设备10厘米的位置,并将迷你声级计放置在扬声器旁边以测量环境噪声。我们用两种粒度来量化SPL的影响:句子识别率和单词识别率。句子识别率计算成功识别的命令的百分比。只有正确识别了命令中的每个单词,才认为命令已被识别。单词识别率是正确解释的单词的百分比。例如,如果命令“ call 1234567890”被识别为“ call 1234567”,则单词识别率为63.6%(7/11)。图15(a)(b)显示了SPL对两种识别率的影响。毫不奇怪,给定相同的SPL,单词识别率始终大于句子识别率,直到两者都达到100%。对于Apple Watch,一旦SPL大于106.2 dB,两种识别率都将变为100%。相比之下,Galaxy S6 Edge达到100%识别率的最低SPL为113.96 dB,高于Apple Watch的最低声压级。这是因为在解调听不见的语音命令方面,Apple Watch胜过Galaxy S6 Edge。
|
|||
|
|

|
|||
|
|
### 6.4 攻击距离的影响
|
|||
|
|
|
|||
|
|
在本节中,将使用激活命令(“ Hey Siri”或“ Hi Galaxy”)和控制命令(“ Call 1234567890”)来测试各种距离下的识别率。 我们评估了Apple Watch和Galaxy S6 Edge上两个命令的识别率,并在图16中进行了描述。通常,激活命令的识别率高于控制命令的识别率,因为激活 该命令包含的单词数少于控制命令。 可以在100厘米远的地方以100%的成功率激活Apple Watch,从25厘米处以100%的成功率激活Galaxy S6 Edge。 我们认为,这两种设备之间的差异是因为Apple Watch戴在手腕上,并且可以接受比智能手机更长的语音命令。
|
|||
|
|
|
|||
|
|
### 6.5 便携式设备攻击评估
|
|||
|
|
|
|||
|
|
在本节中,我们评估便携式设备攻击的有效性。设定。我们将运行Android 6.0.1的Galaxy S6 Edge智能手机用作攻击设备,将Apple Watch作为受害者设备,并将其与iPhone 6 Plus配对使用。攻击声音命令是“打开飞行模式”。我们将fc分别设置为{20、21、22、23、24} kHz。 AM深度为100%,采样率为192 kHz。基带信号的最大频率为3 kHz。结果,如表5所示,我们成功地在Apple Watch上以23 kHz载波频率“开启了飞行模式”。请注意,20 kHz和21 kHz也成功。但是,频率泄漏低于20 kHz,听起来像,可以听到。单词和句子的识别率是100%。随着fc的增加,由于扬声器的频率选择性,Apple Watch无法识别语音命令。为了扩展攻击距离,我们利用低功率音频放大器(3瓦)模块来驱动超声换能器,如图11所示。使用放大器模块,有效攻击的最大距离增加到27厘米。请注意,使用专业设备和功能更强大的放大器可以进一步扩大攻击距离。攻击者可以使用受害者的设备发起远程攻击。例如,对手可以上传音频或视频剪辑,其中语音命令嵌入在网站中,例如YouTube。当受害者的设备播放音频或视频时,可能会无意识地触发周围的语音可控系统,例如Google Home Assistant,Alexa和手机。
|
|||
|
|
|
|||
|
|

|
|||
|
|
|
|||
|
|
## 7 防御
|
|||
|
|
|
|||
|
|
在本节中,我们将从硬件和软件角度讨论针对上述攻击的防御策略。
|
|||
|
|
|
|||
|
|
### 7.1 基于硬件的防御
|
|||
|
|
|
|||
|
|
我们提出了两种基于硬件的防御策略:麦克风增强和基带消除。
|
|||
|
|
|
|||
|
|
* 麦克风增强:语音命令听不到的根本原因是,麦克风可以感应到高于20 kHz的频率的声音,而理想的麦克风则不能。默认情况下,当今移动设备上的大多数MEMS麦克风都允许20 kHz以上的信号[2、3、29、52、53]。因此,应增强麦克风并设计其抑制任何频率在超声范围内的声音信号。例如,iPhone 6 Plus的麦克风可以很好地抵抗听不见的语音命令。
|
|||
|
|
* 语音命令取消听不见。在使用传统麦克风的情况下,我们可以在LPF之前添加一个模块,以检测调制后的语音命令并使用调制后的语音命令取消基带。特别是,我们可以检测到具有AM调制特性的超声频率范围内的信号,并对信号进行解调以获得基带。例如,在存在不可听见的语音命令注入的情况下,除了已解调的基带信号m(t)之外,记录的模拟语音信号还应包括原始调制信号:v(t)= Am(t)cos(2πfc t)+ cos(2πfc t),其中A是输入信号m(t)的增益。通过下变频v(t)以获得Am(t)并调整幅度,我们可以减去基带信号。请注意,这样的命令取消过程不会影响麦克风的正常操作,因为捕获的可听语音信号与超声范围内的噪声之间将不存在相关性。
|
|||
|
|
|
|||
|
|
### 7.2 基于软件的防御
|
|||
|
|
|
|||
|
|
基于软件的防御研究调制语音命令的独特功能,这些功能与真正的语音命令不同。如图17所示,恢复的(解调的)攻击信号在500到1000Hz的高频范围内显示出与原始信号和记录信号的差异。原始信号由Google TTS引擎产生,调制的载波频率为25 kHz。因此,我们可以通过分析500至1000 Hz频率范围内的信号来检测DolphinAttack。特别是,基于机器学习的分类器将对其进行检测。为了验证检测DolphinAttack的可行性,我们利用支持的矢量机(SVM)作为分类器,并从音频中提取了时域和频域中的15个特征。我们生成了12种语音命令(即“ Hey Siri”):NeoSpeech TTS引擎提供了8种语音,Selvy TTS引擎提供了4种语音。对于每种类型,我们获得了两个样本:一个被记录,另一个被恢复。总共有24个样本。为了训练SVM分类器,我们使用5个录制的音频作为正样本,并使用5个恢复的音频作为负样本。其余14个样本用于测试。分类器可以以100%真实肯定率(7/7)和100%真实否定率(7/7)区分恢复的音频和录制的音频。使用简单SVM分类器的结果表明可以使用基于软件的防御策略来检测DolphinAttack。
|
|||
|
|

|
|||
|
|
|
|||
|
|
## 8 相关工作
|
|||
|
|
|
|||
|
|
* 语音可控系统的安全性。越来越多的研究工作投入于研究语音可控系统的安全性[10、18、28、38、61]。 Kasmi等。 [28]通过在耳机电缆上施加有意的电磁干扰,对现代智能手机引入了语音命令注入攻击,而在本文中,我们通过利用超声波上的麦克风非线性来注入语音命令。 Mukhopadhyay等。 [38]展示了对最先进的自动说话人验证算法的语音模仿攻击。他们根据受害者的样本建立了受害者声音的模型。 [18]设计了一种权限绕过来自零许可Android应用程序通过电话扬声器的攻击。隐藏的语音命令和Cocaine noodles[10,61]使用可听和扭曲的音频命令来攻击语音识别系统。在这些攻击下,受害者有时可以观察到混淆的语音命令。 DolphinAttack受这些攻击的动机,但是完全听不见且听不到,我们展示了可以使用便携式设备启动DolphinAttack
|
|||
|
|
* 配备传感器的设备的安全性。配备有各种传感器的商业设备(例如,智能手机,可穿戴设备和平板电脑)正在逐渐普及。随着无处不在的移动设备的增长趋势,安全性成为人们关注的焦点。许多研究人员[14、15、46、60]专注于研究对智能设备上的传感器的可能攻击。其中,传感器欺骗(即,将恶意信号注入受害者传感器)引起了广泛关注,并被认为是对配备传感器的设备的最严重威胁之一。 Shin等。将传感器欺骗攻击[46]分为三类:常规信道攻击(重放攻击)[19、26、66],传输信道攻击和侧信道攻击[11、14、15、47、49]。 Dean等。 [14,15]证明,当声频分量接近陀螺仪传感质量的共振频率时,MEMS陀螺仪容易受到大功率高频声噪声的影响。利用机载传感器,Gu等。 [24]设计了一种使用振动马达和加速度计的加密密钥生成机制。我们的工作重点是麦克风,可以将其视为一种传感器。
|
|||
|
|
* 通过传感器泄露隐私。 Michalevsky等。 [36]利用MEMS陀螺仪来测量声学信号,从而揭示扬声器信息。 Schlegel等。 [44]设计了一种木马程序,可以从智能手机的音频传感器中提取高价值数据。 Owusu等。 [40]利用加速度计的读数作为副通道,在智能手机触摸屏键盘上提取输入文本的整个序列,而无需特殊的特权。 Aviv等。 [6]证明了加速度传感器可以揭示用户的点击和基于手势的输入。 Dey等。 [17]研究了如何利用车载加速度计的缺陷对智能手机进行指纹识别,并且指纹可以用作识别智能手机所有者的标识符。西蒙等。 [48]利用摄像机和麦克风来推断在智能手机的仅数字软键盘上输入的PIN。 Li等。文献[33]可以根据照片中的阴影和相机的传感器读数,通过估计太阳位置来验证照片的捕获时间和位置。 Sun等。 [55]提出了一个视频辅助按键推论框架,以从平板电脑动作的秘密视频记录中推断出平板电脑用户的输入。 Backes等。 [7]显示,可以根据打印机的声音恢复处理英语的点阵打印机正在打印的内容。同样,我们研究了如何利用麦克风漏洞来破坏安全和隐私。罗伊等。 [42]提出了BackDoor,它在超声频带上的两个扬声器和麦克风之间建立了一个声音(但听不见)通信通道。特别是,BackDoor利用两个超声波扬声器传输两个频率。通过麦克风的非线性振膜和功率放大器后,这两个信号在可听频率范围内产生一个“阴影”,可以携带数据。但是,“阴影”是单一音调,而不是由丰富音调集组成的语音命令。相比之下,我们表明可以使用一个扬声器向SR系统注入听不见的命令,从而引起各种安全和隐私问题。
|
|||
|
|
|
|||
|
|
## 海豚攻击”的局限性分析
|
|||
|
|
|
|||
|
|
上面谈到了“海豚攻击”实现的基本原理。但是经过我们的分析,这种“漏洞”虽然理论上存在风险,但是实现代价较大,且整体可行性较低,大家不必过于恐惧。下面我们再来分析一下它能实现的效果的局限性:
|
|||
|
|
|
|||
|
|
局限性1: 测试设备发射要求高,不易隐藏作案。
|
|||
|
|
首先,该系统需要一个大功率且大尺寸的信号发生器来生成高质量的超声信号;同时,目前的普通麦克风对20KHz以上的信号频响衰减非常大,这就要求超声信号的发射功率有相当大的发射功率。
|
|||
|
|
这篇文章中使用的超声发射器可以支持到300MHz的频率范围,超声播放的声压级达到了125dBL,这种情况下普通的简化装置的放大器和喇叭是实现不了的。
|
|||
|
|
|
|||
|
|
局限性2: 攻击距离很短,智能家居产品不受影响。
|
|||
|
|
同样是由于目前普通麦克风对20KHz以上的信号频响衰减非常大,在声压级是125dBL的播放的超声信号下(这个音量已经需要非常专业播放设备了),实验的最远冲击距离只有1.75m,对于大部分设备超过0.5m就没有响应了,再加上超声信号没有穿墙能力,因此对于放在家中的智能硬件设备是没有任何影响的。对于携带到公共场所的手机和可穿戴设备则有一定的“风险”。
|
|||
|
|
|
|||
|
|
局限性3: 攻击语音质量很低,效果和单个硬件相关。
|
|||
|
|
如前面我们的分析,由于解调后的信号毕竟是经过低通滤波器,导致各频带都是有不同程度衰减的,且大部分ADC都有抗混叠滤波,因此最终设备端解调进来的Baseband信号失真很严重,信噪比也不会很高。
|
|||
|
|
攻击效果也跟硬件本身相关,比如麦克风型号、低通滤波器的实现方式和效果、ADC抗混叠效果和采样频率都是相关的。想要达到好的效果必须根据实际的硬件来调节载波频率,信号强度等参数,这对于公共场所游走作案,且不知道被攻击者使用的什么设备的情况下是比较难以实现的。
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
## 9 结论
|
|||
|
|
|
|||
|
|
在本文中,我们提出了DolphinAttack,这是对SR系统的听不见的攻击。 DolphinAttack利用AM(振幅调制)技术来调制超声载波上的可听语音命令,从而使人无法感知命令信号。攻击者可以使用DolphinAttack攻击主要的SR系统,包括Siri,Google Now,Alexa等。为避免实际滥用DolphinAttack,我们从硬件和软件两个方面提出了两种防御解决方案。
|