diff --git a/2000/01/01/hello-world/index.html b/2000/01/01/hello-world/index.html
index 3b43e601..18ce78df 100644
--- a/2000/01/01/hello-world/index.html
+++ b/2000/01/01/hello-world/index.html
@@ -651,7 +651,7 @@
48k
+ 48.3k
diff --git a/2018/11/16/BIBA访问控制模型实现(python)/index.html b/2018/11/16/BIBA访问控制模型实现(python)/index.html
index 0a42db18..fba321e2 100644
--- a/2018/11/16/BIBA访问控制模型实现(python)/index.html
+++ b/2018/11/16/BIBA访问控制模型实现(python)/index.html
@@ -839,7 +839,7 @@
48k
+ 48.3k
diff --git a/2018/12/15/miio-control/index.html b/2018/12/15/miio-control/index.html
index 5cc21a4a..008ee618 100644
--- a/2018/12/15/miio-control/index.html
+++ b/2018/12/15/miio-control/index.html
@@ -741,7 +741,7 @@
48k
+ 48.3k
diff --git a/2018/12/23/基于规则引擎发现IOT设备/index.html b/2018/12/23/基于规则引擎发现IOT设备/index.html
index 729216ed..796db563 100644
--- a/2018/12/23/基于规则引擎发现IOT设备/index.html
+++ b/2018/12/23/基于规则引擎发现IOT设备/index.html
@@ -741,7 +741,7 @@
48k
+ 48.3k
diff --git a/2018/12/25/TCPDUMP拒绝服务攻击漏洞/index.html b/2018/12/25/TCPDUMP拒绝服务攻击漏洞/index.html
index 883002a8..731b3f60 100644
--- a/2018/12/25/TCPDUMP拒绝服务攻击漏洞/index.html
+++ b/2018/12/25/TCPDUMP拒绝服务攻击漏洞/index.html
@@ -746,7 +746,7 @@
48k
+ 48.3k
diff --git a/2019/01/16/wifi半双工侧信道攻击学习笔记/index.html b/2019/01/16/wifi半双工侧信道攻击学习笔记/index.html
index 4733526b..53f2966d 100644
--- a/2019/01/16/wifi半双工侧信道攻击学习笔记/index.html
+++ b/2019/01/16/wifi半双工侧信道攻击学习笔记/index.html
@@ -869,7 +869,7 @@ Server -------wire----------|
48k
+ 48.3k
diff --git a/2019/02/22/qq数据库的加密解密/index.html b/2019/02/22/qq数据库的加密解密/index.html
index 74ad3560..969c3a3e 100644
--- a/2019/02/22/qq数据库的加密解密/index.html
+++ b/2019/02/22/qq数据库的加密解密/index.html
@@ -718,7 +718,7 @@
48k
+ 48.3k
diff --git a/2019/03/16/小米固件工具mkxqimage/index.html b/2019/03/16/小米固件工具mkxqimage/index.html
index 4094f9c0..76051dd7 100644
--- a/2019/03/16/小米固件工具mkxqimage/index.html
+++ b/2019/03/16/小米固件工具mkxqimage/index.html
@@ -725,7 +725,7 @@
48k
+ 48.3k
diff --git a/2019/03/23/auto-send-WX/index.html b/2019/03/23/auto-send-WX/index.html
index 9f971f82..270c5eec 100644
--- a/2019/03/23/auto-send-WX/index.html
+++ b/2019/03/23/auto-send-WX/index.html
@@ -735,7 +735,7 @@
48k
+ 48.3k
diff --git a/2019/03/25/Samba-CVE/index.html b/2019/03/25/Samba-CVE/index.html
index a74150e1..f3ce1a86 100644
--- a/2019/03/25/Samba-CVE/index.html
+++ b/2019/03/25/Samba-CVE/index.html
@@ -760,7 +760,7 @@
48k
+ 48.3k
diff --git a/2019/03/28/逆向工程实验/index.html b/2019/03/28/逆向工程实验/index.html
index daf15785..4c044332 100644
--- a/2019/03/28/逆向工程实验/index.html
+++ b/2019/03/28/逆向工程实验/index.html
@@ -863,7 +863,7 @@
48k
+ 48.3k
diff --git a/2019/04/15/Caving-db-storage/index.html b/2019/04/15/Caving-db-storage/index.html
index f71d0726..a608dacc 100644
--- a/2019/04/15/Caving-db-storage/index.html
+++ b/2019/04/15/Caving-db-storage/index.html
@@ -784,7 +784,7 @@
48k
+ 48.3k
diff --git a/2019/04/21/XIAOMI-UPnP/index.html b/2019/04/21/XIAOMI-UPnP/index.html
index a1762979..a8bb0f5a 100644
--- a/2019/04/21/XIAOMI-UPnP/index.html
+++ b/2019/04/21/XIAOMI-UPnP/index.html
@@ -907,7 +907,7 @@
48k
+ 48.3k
diff --git a/2019/05/13/PE-file/index.html b/2019/05/13/PE-file/index.html
index 970bcc5c..56989b9a 100644
--- a/2019/05/13/PE-file/index.html
+++ b/2019/05/13/PE-file/index.html
@@ -827,7 +827,7 @@
48k
+ 48.3k
diff --git a/2019/05/14/pack-and-unpack/index.html b/2019/05/14/pack-and-unpack/index.html
index b7b04f2b..efdcdae5 100644
--- a/2019/05/14/pack-and-unpack/index.html
+++ b/2019/05/14/pack-and-unpack/index.html
@@ -749,7 +749,7 @@
48k
+ 48.3k
diff --git a/2019/07/01/AFL-first-learn/index.html b/2019/07/01/AFL-first-learn/index.html
index a0ce843b..c5bc0115 100644
--- a/2019/07/01/AFL-first-learn/index.html
+++ b/2019/07/01/AFL-first-learn/index.html
@@ -87,13 +87,10 @@
- 11.4k 字
+ 11.7k 字
@@ -424,7 +421,7 @@
- 42 分钟
+ 44 分钟
@@ -478,282 +475,47 @@
1)用make编译AFL。如果构建失败,请参阅docs / INSTALL以获取提示。1 CC = / path / to / afl-gcc CXX = / path / to / afl-g ++ ./configure --disable shared make clean all
-如果程序构建失败,请联系 afl-users@googlegroups.com 。./afl-fuzz -i testcase_dir -o findings_dir -- \ /path/to/tested/program [... program's cmdline ...]
-一些参考文档
-
-docs/README - AFL的一般介绍,docs/perf_tips.txt - 关于如何快速模糊的简单提示,docs/status_screen.txt - UI中显示的花絮的解释,docs/parallel_fuzzing.txt - 关于在多个核上运行AFL的建议Generated test cases for common image formats - 生成图像文件测试用例的demoTechnical “whitepaper” for afl-fuzz - 技术白皮书
-
-适用环境
-AFL的变体和衍生物允许您模糊Python,Go,Rust,OCaml,GCJ Java,内核系统调用,甚至整个虚拟机。 还有一个密切启发的进程模糊器,它在LLVM中运行,并且是一个在Windows上运行的分支。 最后,AFL是OSS-Fuzz 背后的模糊引擎之一。
-哦 - 如果你安装了gnuplot,你可以使用afl-plot来获得漂亮的进度图。
-
-非常复杂 。它是一种插桩器(instrumentation)引导的遗传模糊器,能够在各种非平凡的目标中合成复杂的文件语义 ,减少了对专用的语法识别工具的需求。它还带有一个独特的崩溃浏览器 ,一个测试用例最小化器 ,一个故障触发分配器 和一个语法分析器 - 使评估崩溃错误的影响变得简单。智能 。它围绕一系列经过精心研究 ,高增益的测试用例预处理和模糊测试策略而构建,在其他模糊测试框架中很少采用与之相当的严格性。结果,它发现了真正的漏洞 。它很快 。由于其低级编译时间或仅二进制检测和其他优化 ,该工具提供了针对常见现实世界目标的近原生或优于原生的模糊测试速度。新增的持久模式 允许在最少的代码修改的帮助下,对许多程序进行异常快速的模糊测试。可以链接到其他工具 。模糊器可以生成优质,紧凑的测试语料库,可以作为更专业,更慢或劳动密集型流程和测试框架的种子。它还能够与任何其他软件进行即时语料库同步。
-
-Written and maintained by Michal Zalewski lcamtuf@google.com
- Copyright 2013, 2014, 2015, 2016 Google Inc. All rights reserved.
- For new versions and additional information, check out:http://lcamtuf.coredump.cx/afl/
- To compare notes with other users or get notified about major new features,afl-users+subscribe@googlegroups.com .
- See QuickStartGuide.txt if you don’t have time to read this file.
-
-1)具有导向性的模糊测试的挑战 Fuzzing是用于识别真实软件中的安全问题的最强大且经过验证的策略之一;它负责安全关键软件中迄今为止发现的绝大多数远程代码执行和权限提升漏洞。
-2)afl-fuzz方法 American Fuzzy Lop是一种暴力模糊测试,配有极其简单但坚如磐石的引导遗传算法。它使用修改后的边缘覆盖形式,轻松地获取程序控制流程的细微局部变化。
+1)用make编译AFL。如果构建失败,请参阅docs / INSTALL以获取提示。文件或标准输入 1 3)使用afl-gcc编译要模糊的程序/库。一种常见的方法是:
+$ CC = /path/to/afl-gcc CXX =/path/to/afl-g++ ./configure –disable-shared1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 如果程序构建失败,请联系 <afl-users@googlegroups.com>。 4)获取一个对程序有意义的小而有效的输入文件。在模糊详细语法(SQL,HTTP等)时,也要创建字典,如```dictionaries/README.dictionaries```中所述。 5)如果程序从stdin读取,则运行`afl-fuzz`,如下所示: `./afl-fuzz -i testcase_dir -o findings_dir -- /path/to/tested/program [... program's cmdline ...] ` 如果程序从文件中获取输入,则可以在程序的命令行中输入@@; AFL会为您放置一个自动生成的文件名。 **一些参考文档** >[docs/README](http://lcamtuf.coredump.cx/afl/README.txt) - AFL的一般介绍, >[docs/perf_tips.txt](https://github.com/mirrorer/afl/blob/master/docs/perf_tips.txt) - 关于如何快速模糊的简单提示, >[docs/status_screen.txt](http://lcamtuf.coredump.cx/afl/status_screen.txt) - UI中显示的花絮的解释, >[docs/parallel_fuzzing.txt](https://github.com/mirrorer/afl/blob/master/docs/parallel_fuzzing.txt) - 关于在多个核上运行AFL的建议 >[Generated test cases for common image formats](http://lcamtuf.coredump.cx/afl/demo/) - 生成图像文件测试用例的demo >[Technical "whitepaper" for afl-fuzz](http://lcamtuf.coredump.cx/afl/technical_details.txt) - 技术白皮书 > **适用环境** 该工具已确认适用于32位和64位的x86 Linux,OpenBSD,FreeBSD和NetBSD。 它也适用于MacOS X和Solaris,但有一些限制。 它支持用C,C ++或Objective C编写的程序,使用gcc或clang编译。 在Linux上,可选的QEMU模式也允许对黑盒二进制文件进行模糊测试。 AFL的变体和衍生物允许您模糊Python,Go,Rust,OCaml,GCJ Java,内核系统调用,甚至整个虚拟机。 还有一个密切启发的进程模糊器,它在LLVM中运行,并且是一个在Windows上运行的分支。 最后,AFL是[OSS-Fuzz](https://github.com/google/oss-fuzz/)背后的模糊引擎之一。 哦 - 如果你安装了gnuplot,你可以使用afl-plot来获得漂亮的进度图。 ------------------------------ # 0x03 [AFL特点](http://lcamtuf.coredump.cx/afl/) 1. **非常复杂**。它是一种插桩器(instrumentation)引导的遗传模糊器,能够在各种非平凡的目标中[合成复杂的文件语义](http://lcamtuf.blogspot.com/2014/11/pulling-jpegs-out-of-thin-air.html),减少了对专用的语法识别工具的需求。它还带有一个独特的[崩溃浏览器](http://lcamtuf.blogspot.com/2014/11/afl-fuzz-crash-exploration-mode.html),一个[测试用例最小化器](https://groups.google.com/d/msg/afl-users/eWb2PgjLnUo/8AKqadYzSBoJ),一个[故障触发分配器](https://groups.google.com/forum/#!topic/afl-users/RW4RF6x9aBc)和一个[语法分析器](https://lcamtuf.blogspot.com/2016/02/say-hello-to-afl-analyze.html) - 使评估崩溃错误的影响变得简单。 2. **智能**。它围绕一系列经过[精心研究](http://lcamtuf.blogspot.com/2014/08/binary-fuzzing-strategies-what-works.html),高增益的测试用例预处理和模糊测试策略而构建,在其他模糊测试框架中很少采用与之相当的严格性。结果,它发现了真正的[漏洞](http://lcamtuf.coredump.cx/afl/#bugs)。 3. **它很快**。由于其低级编译时间或仅二进制检测和[其他优化](http://lcamtuf.blogspot.com/2014/10/fuzzing-binaries-without-execve.html),该工具提供了针对常见现实世界目标的近原生或优于原生的模糊测试速度。新增的[持久模式](http://lcamtuf.blogspot.com/2015/06/new-in-afl-persistent-mode.html)允许在最少的代码修改的帮助下,对许多程序进行异常快速的模糊测试。 4. **可以链接到其他工具**。模糊器可以生成优质,紧凑的测试语料库,可以作为更专业,更慢或劳动密集型流程和测试框架的种子。它还能够与任何其他软件进行即时语料库同步。 ------------------------------------ # 0x04 [AFL README](http://lcamtuf.coredump.cx/afl/README.txt) > Written and maintained by Michal Zalewski <lcamtuf@google.com> > > Copyright 2013, 2014, 2015, 2016 Google Inc. All rights reserved. > Released under terms and conditions of Apache License, Version 2.0. > > For new versions and additional information, check out: > http://lcamtuf.coredump.cx/afl/ > > To compare notes with other users or get notified about major new features, > send a mail to <afl-users+subscribe@googlegroups.com>. > > **See QuickStartGuide.txt if you don't have time to read this file.** ## 1)具有导向性的模糊测试的挑战 Fuzzing是用于识别真实软件中的安全问题的最强大且经过验证的策略之一;它负责安全关键软件中迄今为止发现的绝大多数远程代码执行和权限提升漏洞。 不幸的是,模糊测试也不够有力。盲目的、随机的变异使得它不太可能在测试代码中达到某些代码路径,从而使一些漏洞超出了这种技术的范围。 已经有许多尝试来解决这个问题。早期方法之一 - 由Tavis Ormandy开创 - 是一种 **语义库蒸馏(corpus distillation)** 。网上找到的一些大型语料库中往往包含大量的文件,这时就需要对其精简,该方法依赖于覆盖信号从大量高质量的候选文件语料库中选择有趣种子的子集,然后通过传统方式对其进行模糊处理。该方法非常有效,但需要这样的语料库随时可用。正因为如此,**代码覆盖率** 也只是衡量程序执行状态的一个简单化的度量,这种方式并不适合后续引导fuzzing测试的。 其他更复杂的研究集中在诸如 **程序流分析(“concoic execution”),符号执行或静态分析** 等技术上。所有这些方法在实验环境中都非常有前景,但在实际应用中往往会遇到可靠性和性能问题 - 部分高价值的程序都有非常复杂的内部状态和执行路径,在这一方面符号执行和concolic技术往往会显得不够健壮(如路径爆炸问题),所以仍然稍逊于传统的fuzzing技术。 ## 2)afl-fuzz方法 American Fuzzy Lop是一种暴力模糊测试,配有极其简单但坚如磐石的 **引导遗传算法** 。它使用修改后的边覆盖率,轻松地获取程序控制流程的细微局部变化。 简化一下,整体算法可以概括为: * 1)将用户提供的初始测试用例加载到队列中, * 2)从队列中获取下一个输入文件, * 3)尝试将测试用例修剪到不会改变程序测量行为的最小尺寸, * 4)使用平衡且经过充分研究的各种传统模糊测试策略反复改变文件, * 5)如果任何生成的编译导致由instrumentation记录的新状态转换,则将变异输出添加为队列中的新条目。 * 6)转到2。 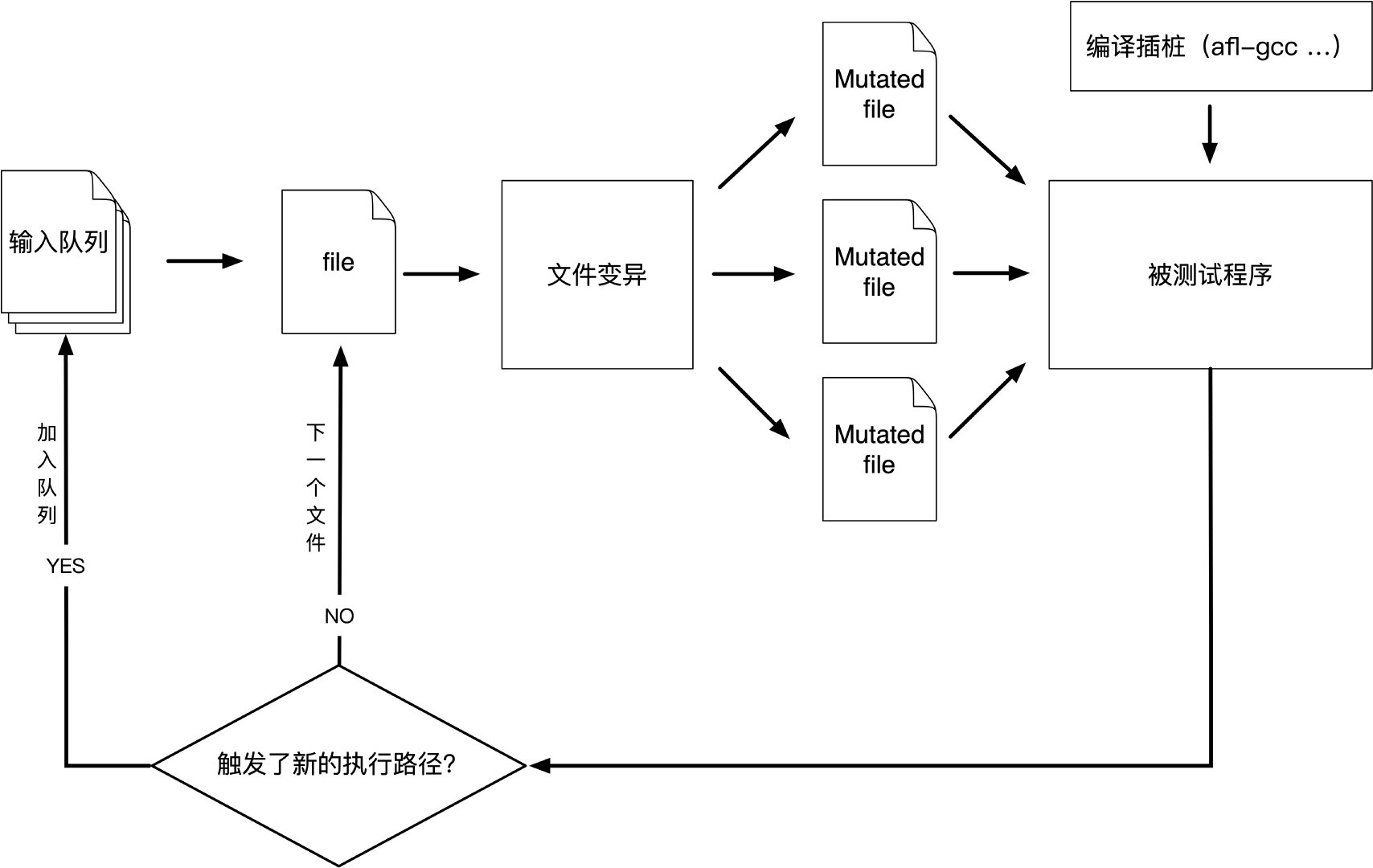 发现的测试用例也会定期被淘汰,以消除那些被更新,更高覆盖率的发现所淘汰的测试用例。并经历其他几个插桩驱动(instrumentation-driven)的努力最小化步骤。 作为模糊测试过程的一个副作用,该工具创建了一个小型,独立的有趣测试用例集。这些对于播种其他劳动力或资源密集型测试方案非常有用 - 例如,用于压力测试浏览器,办公应用程序,图形套件或闭源工具。 该模糊器经过全面测试,可提供远远优于盲目模糊或仅覆盖工具的开箱即用性能。 ## 3)用于AFL的插桩(instrumentation)程序 当源代码可用时,可以通过配套工具 **注入instrumentation** ,该工具可作为第三方代码的任何标准构建过程中gcc或clang的替代品。 instrumentation具有相当适度的性能影响;与afl-fuzz实现的其他优化相结合,大多数程序可以像传统工具一样快速或甚至更快地进行模糊测试。 **重新编译目标程序** 的正确方法可能会有所不同,具体取决于构建过程的具体情况,但几乎通用的方法是:
+$ CC = /path/to/afl/afl-gcc ./configure1 2 3 clang组件(afl-clang和afl-clang ++)可以以相同的方式使用; clang用户也可以选择利用更高性能的检测模式,如llvm_mode / README.llvm中所述。 在测试库时,您需要查找或编写一个简单的程序,该程序从stdin或文件中读取数据并将其传递给测试的库。在这种情况下,必须 **将此可执行文件与已检测库的静态版本相链接** ,或者确保在运行时加载正确的.so文件(通常通过设置LD_LIBRARY_PATH)。最简单的选项是 **静态构建** ,通常可以通过以下方式实现:
+$ CC = /path/to/afl/afl-gcc ./configure –disable-shared1 2 3 4 5 6 调用`make`时设置AFL_HARDEN = 1将导致CC组件自动启用代码强化选项,以便更容易检测到简单的内存错误。 Libdislocator,AFL附带的帮助程序库(请参阅libdislocator / README.dislocator)也可以帮助发现堆损坏问题。 PS。建议ASAN用户查看notes_for_asan.txt文件以获取重要警告。 ## 4)检测仅二进制应用程序 当源代码为不可得时,afl为黑盒二进制文件的快速、即时检测提供实验支持。 这是通过在较不为人知的“用户空间仿真”模式下运行的QEMU版本来实现的。 QEMU是一个独立于AFL的项目,但您可以通过以下方式方便地构建该功能:
+$ cd qemu_mode1 2 3 4 5 6 7 8 9 10 11 12 13 14 有关其他说明和注意事项,请参阅qemu_mode / README.qemu。 该模式比编译时插桩(instrumentation)慢约2-5倍,对并行化的兼容较差,并且可能有一些其他的不同。 ## 5)选择初始测试用例 为了正确操作,模糊器需要一个或多个起始文件,其中包含目标应用程序通常所需的输入数据的良好示例。 有两个基本规则: > 测试用例足够小。 1 kB以下是理想的,尽管不是绝对必要的。 有关大小重要性的讨论,请参阅perf_tips.txt。 > > 只有在功能上彼此不同时才使用多个测试用例。 使用五十张不同的度假照片来模糊图像库是没有意义的。 您可以在此工具附带的`testcases/子目录`中找到许多启动文件的好例子。 PS。 如果有大量数据可用于筛选,您可能希望使用`afl-cmin`实用程序来识别在目标二进制文件中使用不同代码路径的功能不同的文件的子集。 ## 6)模糊测试二进制文件 测试过程本身由afl-fuzz实用程序执行。该程序需要一个带有初始测试用例的只读目录,一个存储其输出结果的独立位置,以及要测试的二进制文件的路径。 对于直接从 **stdin** 接受输入的目标二进制文件,通常的语法是:
+$ ./afl-fuzz -i testcase_dir -o findings_dir /path/to/program [… params …]1 对于从 **文件** 中获取输入的程序,使用“@@”标记目标命令行中应放置输入文件名的位置。模糊器将替换为您:
+$ ./afl-fuzz -i testcase_dir -o findings_dir /path/to/program @@1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 您还可以使用-f选项将变异数据写入特定文件。如果程序需要特定的文件扩展名,那么这很有用。 非插桩二进制文件可以在QEMU模式下(在命令行中添加-Q)或在传统的盲目模糊模式(指定-n)中进行模糊测试。 您可以使用-t和-m覆盖已执行进程的默认超时和内存限制; perf_tips.txt中讨论了优化模糊测试性能的技巧。 请注意,afl-fuzz首先执行一系列确定性模糊测试步骤,这可能需要几天时间,但往往会产生整齐的测试用例。如果你想要快速结果 - 类似于zzuf和其他传统的模糊器 - 在命令行中添加-d选项。 ## 7)解释输出 有关如何解释显示的统计信息以及监视进程运行状况的信息,请参阅`status_screen.txt`文件。请务必查阅此文件,尤其是如果任何UI元素以红色突出显示。 模糊过程将持续到按`Ctrl-C`为止。至少,您希望允许模糊器完成一个队列周期,这可能需要几个小时到一周左右的时间。 在输出目录中创建了三个子目录并实时更新: - 队列queue/ - 测试每个独特执行路径的案例,以及用户提供的所有起始文件。这是第2节中提到的合成语料库。在将此语料库用于任何其他目的之前,您可以使用afl-cmin工具将其缩小到较小的大小。该工具将找到一个较小的文件子集,提供相同的边缘覆盖。 - 崩溃crash/ - 导致被测程序接收致命信号的独特测试用例(例如,SIGSEGV,SIGILL,SIGABRT)。条目按接收信号分组。 - 挂起hang/ - 导致测试程序超时的独特测试用例。将某些内容归类为挂起之前的默认时间限制是1秒内的较大值和-t参数的值。可以通过设置AFL_HANG_TMOUT来微调该值,但这很少是必需的。崩溃和挂起被视为“唯一” “如果相关的执行路径涉及在先前记录的故障中未见的任何状态转换。如果可以通过多种方式达到单个错误,那么在此过程中会有一些计数通货膨胀,但这应该会迅速逐渐减少。 崩溃和挂起的文件名与父、非错误的队列条目相关联。这应该有助于调试。 如果无法重现 **afl-fuzz** 发现的崩溃,最可能的原因是您没有设置与工具使用的内存限制相同的内存限制。尝试:
+$ LIMIT_MB = 501 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 更改LIMIT_MB以匹配传递给afl-fuzz的-m参数。在OpenBSD上,也将-Sv更改为-Sd。任何现有的输出目录也可用于恢复中止的作业; 尝试:`$ ./afl-fuzz -i-o_ existing_output_dir [...etc...]` 如果安装了gnuplot,您还可以使用afl-plot为任何活动的模糊测试任务生成一些漂亮的图形。有关如何显示的示例,请参阅 http://lcamtuf.coredump.cx/afl/plot/ 。 ## 8)并行模糊测试 每个afl-fuzz的实例大约占用一个核。 这意味着在多核系统上,并行化是充分利用硬件所必需的。 有关如何在多个核心或多个联网计算机上模糊常见目标的提示,请参阅`parallel_fuzzing.txt`。 ***并行模糊测试模式*** 还提供了一种简单的方法,用于将AFL连接到其他模糊器,动态符号执行(concrete and symbolic, concolic execution)引擎等等; 再次,请参阅 `parallel_fuzzing.txt`的最后一节以获取提示。 ## 9)Fuzzer词典 默认情况下,afl-fuzz变异引擎针对紧凑数据格式进行了优化 - 例如,图像,多媒体,压缩数据,正则表达式语法或shell脚本。它有点不太适合具有特别冗长和冗余的语言的语言 - 特别是包括HTML,SQL或JavaScript。 为了避免构建语法感知工具的麻烦,afl-fuzz提供了一种方法,使用与目标数据类型相关联的其他特殊标记的语言关键字,魔术头或可选字典为模糊测试过程设定种子,并使用它来重建底层随时随地的语法:http://lcamtuf.blogspot.com/2015/01/afl-fuzz-making-up-grammar-with.html 要使用此功能,首先需要使用`dictionaries/README.dictionaries`中讨论的两种格式之一创建字典;然后通过命令行中的-x选项将模糊器指向它。(该子目录中也已提供了几个常用字典。) 没有办法提供基础语法的更多结构化描述,但模糊器可能会根据instrumentation反馈单独找出一些。这实际上在实践中有效,比如说: http://lcamtuf.blogspot.com/2015/04/finding-bugs-in-sqlite-easy-way.html PS。即使没有给出明确的字典,afl-fuzz也会尝试通过在确定性字节翻转期间非常接近地观察instrumentation来提取输入语料库中的现有语法标记。这适用于某些类型的解析器和语法,但不如-x模式好。 如果字典真的很难找到,另一个选择是让AFL运行一段时间,然后使用作为AFL伴随实用程序的令牌捕获库。为此,请参阅`libtokencap/README.tokencap`。 ## 10)崩溃分类 基于coverage的崩溃分组通常会生成一个小型数据集,可以手动或使用非常简单的GDB或Valgrind脚本快速进行分类。每次崩溃都可以追溯到队列中的父级非崩溃测试用例,从而更容易诊断故障。 话虽如此,重要的是要承认,如果没有大量的调试和代码分析工作,一些模糊的崩溃很难快速评估可利用性。为了帮助完成这项任务,afl-fuzz支持使用-C标志启用的非常独特的“崩溃探索”模式。 在此模式下,模糊器将一个或多个崩溃测试用例作为输入,并使用其反馈驱动的模糊测试策略,非常快速地枚举程序中可以达到的所有代码路径,同时使其保持在崩溃状态。 ***不会导致崩溃的变异会被拒绝;任何不影响执行路径的更改也是如此。*** 输出是一个小文件集,可以非常快速地检查以查看攻击者对错误地址的控制程度,或者是否有可能超过初始越界读取,并查看下面的内容。 哦,还有一件事:对于测试用例最小化,请尝试`afl-tmin`。该工具可以以非常简单的方式操作: `$ ./afl-tmin -i test_case -o minimize_result - /path/to/program [...]` 该工具适用于崩溃和非崩溃的测试用例。在崩溃模式下,它将很乐意接受 instrumented 和 non-instrumented 的二进制文件。在非崩溃模式下,最小化器依赖于标准AFL检测来使文件更简单而不改变执行路径。minimizer与afl-fuzz兼容的方式接受-m,-t,-f和@@语法。如果指定了参数-x,即crash mode,会把导致程序非正常退出的文件直接剔除。 AFL的另一个新成员是afl-analyze工具。需要输入文件,尝试按顺序翻转字节,并观察测试程序的行为。然后根据哪些部分看起来是关键的,哪些部分不是关键的,对输入进行颜色编码;虽然不是万能,但它通常可以提供对复杂文件格式的快速见解。有关其操作的更多信息可以在`technical_details.txt`的末尾找到。 ## 11)超越崩溃 模糊测试是一种很好的,未充分利用的技术,用于发现非崩溃的设计和实现错误。通过修改目标程序调用abort()时发现了一些有趣的错误,比如: - 当给出相同的模糊输入时,两个bignum库产生不同的输出, - 当要求连续多次解码相同的输入图像时,图像库会产生不同的输出, - 在对模糊提供的数据进行迭代序列化和反序列化时,序列化/反序列化库无法生成稳定的输出, - 当要求压缩然后解压缩特定blob时,压缩库会生成与输入文件不一致的输出。实施这些或类似的健全性检查通常只需要很少的时间;如果你是特定包的维护者,你可以使用#ifdef FUZZING_BUILD_MODE_UNSAFE_FOR_PRODUCTION(一个也与libfuzzer共享的标志)或#ifdef __AFL_COMPILER(这个只适用于AFL)来使这个代码成为条件。 ## 12)常识性风险 请记住,与许多其他计算密集型任务类似,模糊测试可能会给您的硬件和操作系统带来压力。特别是: - 你的CPU会很热,需要充分冷却。在大多数情况下,如果冷却不足或停止正常工作,CPU速度将自动受到限制。也就是说,尤其是在不太合适的硬件(笔记本电脑,智能手机等)上进行模糊测试时,某些事情并非完全不可能爆发。 - 有针对性的程序可能最终不正常地抓取千兆字节的内存或用垃圾文件填满磁盘空间。 AFL试图强制执行基本的内存限制,但不能阻止每一个可能的事故。最重要的是,您不应该对数据丢失前景不可接受的系统进行模糊测试。 - 模糊测试涉及数十亿次对文件系统的读写操作。在现代系统中,这通常会被高度缓存,导致相当适度的“物理”I/O - 但是有许多因素可能会改变这个等式。您有责任监控潜在的问题; I / O非常繁重,许多HDD和SSD的使用寿命可能会缩短。监视Linux上磁盘I/O的一种好方法是'iostat'命令:` $ iostat -d 3 -x -k [...可选磁盘ID ...]` ## **13)已知的限制和需要改进的领域** 以下是AFL的一些最重要的警告: - AFL通过检查由于信号(SIGSEGV,SIGABRT等)而导致的第一个衍生过程死亡来检测故障。为这些信号安装自定义处理程序的程序可能需要注释掉相关代码。同样,由模糊目标产生的子处理中的故障可能会逃避检测,除非您手动添加一些代码来捕获它。 - 与任何其他强力工具一样,如果使用加密,校验和,加密签名或压缩来完全包装要测试的实际数据格式,则模糊器提供有限的覆盖范围。要解决这个问题,你可以注释掉相关的检查(参见experimental / libpng_no_checksum /获取灵感);如果这是不可能的,你也可以编写一个后处理器,如experimental / post_library /中所述。 - ASAN和64位二进制文件存在一些不幸的权衡。这不是因为任何特定的模糊错误;请参阅notes_for_asan.txt以获取提示。 - 没有直接支持模糊网络服务,后台守护程序或需要UI交互才能工作的交互式应用程序。您可能需要进行简单的代码更改,以使它们以更传统的方式运行。 Preeny也可以提供一个相对简单的选项 - 请参阅:https://github.com/zardus/preeny 有关修改基于网络的服务的一些有用提示也可以在以下位置找到: https://www.fastly.com/blog/how-to-fuzz-server-american-fuzzy-lop - AFL不输出人类可读的覆盖数据。如果你想监控覆盖,请使用Michael Rash的afl-cov:https://github.com/mrash/afl-cov - 偶尔,敏感的机器会对抗他们的创造者。如果您遇到这种情况,请访问http://lcamtuf.coredump.cx/prep/。除此之外,请参阅安装以获取特定于平台的提示。 -------------------------------------- # 0x05 [afl-fuzz白皮书](http://lcamtuf.coredump.cx/afl/technical_details.txt) 本文档提供了American Fuzzy Lop的简单的概述。想了解一般的使用说明,请参见 `README` 。想了解AFL背后的动机和设计目标,请参见 [historical_notes.txt](http://lcamtuf.coredump.cx/afl/historical_notes.txt)。 ## 0)设计说明(Design statement) American Fuzzy Lop 不关注任何单一的操作规则(singular principle of operation),也不是一个针对任何特定理论的概念验证(proof of concept)。这个工具可以被认为是一系列在实践中测试过的hacks行为,我们发现这个工具惊人的有效。我们用目前最simple且最robust的方法实现了这个工具。 唯一的设计宗旨在于速度、可靠性和易用性。 ## 1)覆盖率计算(Coverage measurements) 在编译过的程序中插桩能够捕获分支(边缘)的覆盖率,并且还能检测到粗略的分支执行命中次数(branch-taken hit counts)。在分支点注入的代码大致如下:
+ cur_location = <COMPILE_TIME_RANDOM>; //用一个随机数标记当前基本块1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 cur_location 的值是随机产生的,为的是简化连接复杂对象的过程和保持XOR输出分布是均匀的。 shared_mem[] 数组是一个调用者 (caller) 传给被插桩的二进制程序的64kB的共享空间。其中的每一字节可以理解成对于插桩代码中特别的元组(branch_src, branch_dst)的一次命中(hit)。 选择这个数组大小的原因是让冲突(collisions)尽可能减少。这样通常能处理2k到10k的分支点。同时,它的大小也足以使输出图能在接受端达到毫秒级的分析。 |Branch cnt | Colliding tuples | Example targets| |------------|------------------|-----------------| | 1,000 | 0.75% | giflib, lzo | | 2,000 | 1.5% | zlib, tar, xz | | 5,000 | 3.5% | libpng, libwebp | | 10,000 | 7% | libxml | | 20,000 | 14% | sqlite | | 50,000 | 30% | - | 这种形式的覆盖率,相对于简单的基本块覆盖率来说,对程序运行路径提供了一个更好的描述(insight)。特别地,它能很好地区分以下两个执行路径: > A -> B -> C -> D -> E (tuples: AB, BC, CD, DE) > A -> B -> D -> C -> E (tuples: AB, BD, DC, CE) 这有助于发现底层代码的微小错误条件。因为 **安全漏洞通常是一些非预期(或不正确)的语句转移(一个tuple就是一个语句转移)** ,而不是没覆盖到某块代码。 上边伪代码的最后一行移位操作是为了让tuple具有定向性(没有这一行的话,A^B和B^A就没区别了,同样,A^A和B^B也没区别了)。采用右移的原因跟Intel CPU的一些特性有关。 ## 2)发现新路径(Detecting new behaviors) AFL的fuzzers使用一个**全局Map**来存储之前执行时看到的tuple。这些数据可以被用来对不同的trace进行快速对比,从而可以计算出是否新执行了一个dword指令/一个qword-wide指令/一个简单的循环。 当一个变异的输入产生了一个包含新tuple的执行路径时,对应的输入文件就被保存,然后被发送到下一过程(见第3部分)。对于那些没有产生新路径的输入,就算他们的instrumentation输出模式是不同的,也会被抛弃掉。 这种算法考虑了一个非常细粒度的、长期的对程序状态的探索,同时它还不必执行复杂的计算,不必对整个复杂的执行流进行对比,也避免了路径爆炸的影响。 为了说明这个算法是怎么工作的,考虑下面的两个路径,第二个路径出现了新的tuples(CA, AE):
+#1: A -> B -> C -> D -> E
+#2: A -> B -> C -> A -> E1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 因为#2的原因,以下的路径就不认为是不同的路径了,尽管看起来非常不同: `#3: A -> B -> C -> A -> B -> C -> A -> B -> C -> D -> E` 除了检测新的tuple之外,AFL的fuzzer也会粗略地记录tuple的**命中数(hit counts)**。这些被分割成几个buckets:1, 2, 3, 4-7, 8-15, 16-31, 32-127, 128+ 从某种意义来说,buckets里边的数目是有实际意义的:它是一个8-bit counter和一个8-position bitmap的映射。8-bit counter是由桩生成的,8-position bitmap则依赖于每个fuzzer记录的已执行的tuple的命中数。 单个bucket的改变会被忽略掉: 在程序控制流中,bucket的转换会被标记成一个interesting change,传入evolutionary(见第三部分)进行处理。 通过命中次数(hit count),我们能够分辨控制流是否发生变化。例如一个代码块被执行了两次,但只命中了一次。并且这种方法对循环的次数不敏感(循环47次和48次没区别)。 这种算法通过限制内存和运行时间来保证效率。 另外,算法通过设置执行超时,来避免效率过低的fuzz。从而进一步发现效率比较高的fuzz方式。 ## 3)输入队列的进化(Evolving the input queue) 经变异的测试用例,会使程序产生 ***新的状态转移*** 。这些测试用例稍后被添加到 input 队列中,用作下一个 fuzz 循环。它们补充但不替换现有的发现。 这种算法允许工具可以持续探索不同的代码路径,即使底层的数据格式可能是完全不同的。如下图:  这里有一些这种算法在实际情况下例子: [pulling-jpegs-out-of-thin-air](https://lcamtuf.blogspot.com/2014/11/pulling-jpegs-out-of-thin-air.html) [afl-fuzz-nobody-expects-cdata-sections](http://lcamtuf.blogspot.com/2014/11/afl-fuzz-nobody-expects-cdata-sections.html) 这种过程下产生的语料库基本上是这些输入文件的集合:它们都能触发一些新的执行路径。产生的语料库,可以被用来作为其他测试的种子。 使用这种方法,大多数目标程序的队列会增加到大概1k到10k个entry。大约有10-30%归功于对新tupe的发现,剩下的和hit counts改变有关。 下表比较了不同 fuzzing 方法在发现文件句法(file syntax)和探索程序执行路径的能力。插桩的目标程序是 `GNU patch 2.7.3 compiled with -O3 and seeded with a dummy text file:` |Fuzzer guidance strategy used | Blocks reached | Edges reached | Edge hit cnt var| Highest-coverage test case generated| |--------------|--------|---------|----------|----------------------| | (Initial file) | 156 | 163 | 1.00 | (none)| | Blind fuzzing S | 182 | 205 | 2.23 | First 2 B of RCS diff| | Blind fuzzing L | 228 | 265 | 2.23 | First 4 B of -c mode diff | Block coverage | 855 | 1,130 | 1.57 | Almost-valid RCS diff| | Edge coverage | 1,452 | 2,070 | 2.18 | One-chunk -c mode diff| | AFL model | 1,765 | 2,597 | 4.99 | Four-chunk -c mode diff| 第一行的blind fuzzing (“S”)代表仅仅执行了一个回合的测试。 第二行的Blind fuzzing L表示在一个循环中执行了几个回合的测试,但是没有进行改进。和插桩运行相比,需要更多时间全面处理增长队列。 在另一个独立的实验中也取得了大致相似的结果。在新实验中,fuzzer被修改成所有随机fuzzing 策略,只留下一系列基本、连续的操作,例如位反转(bit flips)。因为这种模式(mode)将不能改变输入文件的的大小,会话使用一个合法的合并格式(unified diff)作为种子。 | Queue extension strategy used | Blocks reached | Edges reached| Edge hit cnt var | Number of unique crashes found| |------------------|---------|---------|----------|------------------| | (Initial file) | 624 | 717 | 1.00 | -| | Blind fuzzing | 1,101 | 1,409 | 1.60 | 0| | Block coverage | 1,255 | 1,649 | 1.48 | 0| | Edge coverage | 1,259 | 1,734 | 1.72 | 0| | AFL model | 1,452 | 2,040 | 3.16 | 1| 在之前提到的基于遗传算法的fuzzing,是通过一个test case的进化(这里指的是用遗传算法进行变异)来实现最大覆盖。在上述实验看来,这种“贪婪”的方法似乎没有为盲目的模糊策略带来实质性的好处。 ## 4)语料筛选(Culling the corpus) 上文提到的渐进式语句探索路径的方法意味着:假设A和B是测试用例(test cases),且B是由A变异产生的。那么测试用例B达到的边缘覆盖率(edge coverage)是测试用例A达到的边缘覆盖率的严格超集(superset)。 为了优化fuzzing,AFL会用一个快速算法**周期性的重新评估**(re-evaluates)队列,这种算法会选择队列的一个更小的子集,并且这个子集仍能覆盖所有的tuple。算法的这个特性对这个工具特别有利(favorable)。 算法通过指定每一个队列入口(queue entry),根据执行时延(execution latency)和文件大小分配一个分值比例(score proportional)。然后为每一个tuple选择**最低分值的entry**。 这些tuples按下述流程进行处理:
+ 1) Find next tuple not yet in the temporary working set,
+ 2) Locate the winning queue entry for this tuple,
+ 3) Register all tuples present in that entry’s trace in the working set,
+ 4) Go to #1 if there are any missing tuples in the set.1 "favored" entries 产生的语料,会比初始的数据集小5到10倍。没有被选择的也没有被扔掉,而是在遇到下列对队列时,以一定概率略过:
-1)将用户提供的初始测试用例加载到队列中,
-2)从队列中获取下一个输入文件,
-3)尝试将测试用例修剪到不会改变程序测量行为的最小尺寸,
-4)使用平衡且经过充分研究的各种传统模糊测试策略反复改变文件,
-5)如果任何生成的编译导致由instrumentation记录的新状态转换,则将变异输出添加为队列中的新条目。
-6)转到2。
+If there are new, yet-to-be-fuzzed favorites present in the queue,
+If there are no new favorites:
+If the current non-favored entry was fuzzed before, it will be skipped 95% of the time.
+If it hasn’t gone through any fuzzing rounds yet, the odds of skipping drop down to 75%.
+1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 基于以往的实验经验,这种方法能够在队列周期速度(queue cycling speed)和测试用例多样性(test case diversity)之间达到一个合理的平衡。 使用**afl-cmin工具**能够对输入或输出的语料库进行稍微复杂但慢得多的的处理。这一工具将永久丢弃冗余entries,产生适用于afl-fuzz或者外部工具的更小的语料库。 ## 5)输入文件修剪(Trimming input files) 文件的大小对fuzzing的性能有着重大影响(dramatic impact)。因为大文件会让目标二进制文件运行变慢;大文件还会减少变异触及重要格式控制结构(format control structures)的可能性(**我们希望的是变异要触及冗余代码块(redundant data blocks)**)。这个问题将在[perf_tips.txt](https://github.com/mirrorer/afl/blob/master/docs/perf_tips.txt)细说。 用户可能提供低质量初始语料(starting corpus),某些类型的变异会迭代地增加生成文件的大小。所以要抑制这种趋势(counter this trend)。 幸运的是,**插桩反馈(instrumentation feedback)**提供了一种简单的方式自动削减(trim down)输入文件,并确保这些改变能使得文件对执行路径没有影响。 afl-fuzz内置的修剪器(trimmer)使用变化的长度和步距(variable length and stepover)来连续地(sequentially)删除数据块;任何不影响trace map的校验和(checksum)的删除块将被提交到disk。 这个修剪器的设计并不算特别地周密(thorough),相反地,它试着在精确度(precision)和进程调用execve()的次数之间选取一个平衡,找到一个合适的block size和stepover。平均每个文件将增大约5-20%。 独立的**afl-tmin工具**使用更完整(exhaustive)、迭代次数更多(iteractive)的算法,并尝试对被修剪的文件采用字母标准化的方式处理。 ## 6) 模糊测试策略(Fuzzing strategies) 插桩提供的反馈(feedback)使得我们更容易理解各种不同fuzzing策略的价值,从而优化(optimize)他们的参数。使得他们对不同的文件类型都能同等地进行工作。afl-fuzz用的策略通常是与格式无关(format-agnostic),详细说明在下边的连接中: [binary-fuzzing-strategies-what-works](http://lcamtuf.blogspot.com/2014/08/binary-fuzzing-strategies-what-works.html) 值得注意的一点是,afl-fuzz大部分的(尤其是前期的)工作都是高度确定的(highly deterministic),随机性修改和测试用例拼接(random stacked modifications和test case splicing)只在后期的部分进行。 **确定性的策略** 包括:
Sequential bit flips with varying lengths and stepovers,使用变化的长度和步距来连续进行位反转
+Sequential addition and subtraction of small integers,对小的整型数来连续进行加法和减法
+Sequential insertion of known interesting integers (0, 1, INT_MAX, etc),对已知的感兴趣的整型数连续地插入
+1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 使用这些确定步骤的目的在于,生成紧凑的(compact)测试用例,以及在产生non-crashing的输入和产生crashing的输入之间,有很小的差异(small diffs)。 **非确定性(non-deterministic)策略** 的步骤包括:stacked bit flips、插入(insertions)、删除(deletions)、算数(arithmetics)和不同测试用例之间的拼接(splicing)。 由于在[historical_notes.txt](http://lcamtuf.coredump.cx/afl/historical_notes.txt) 中提到的原因(性能、简易性、可靠性),AFL通常不试图去推断某个特定的变异(specific mutations)和程序状态(program states)的关系。 fuzzing的步骤名义上来说是盲目的(nominally blind),只被输入队列的进化方式的设计所影响(<strong>见第三部分</strong>)。 这意味着,这条规则有一个例外: 当一个新的队列条目,经过初始的确定性fuzzing步骤集合时,并且文件的部分区域被观测到对执行路径的校验和没有影响,这些队列条目在接下来的确定性fuzzing阶段可能会被排除。 尤其是对那些冗长的数据格式,这可以在保持覆盖率不变的情况下,减少10-40%的执行次数。在一些极端情况下,比如一些block-aligned的tar文件,这个数字可以达到90%。 ## 7) 字典(Dictionaries) 插桩提供的反馈能够让它自动地识别出一些输入文件中的语法(syntax)符号(tokens),并且能够为测试器(tested parser)检测到一些组合,这些组合是由预定义(predefined)的或自动检测到的(auto-detected)字典项(dictionary terms)构成的合法语法(valid grammar)。 关于这些特点在afl-fuzz是如何实现的,可以看一下这个链接: [afl-fuzz-making-up-grammar-with](http://lcamtuf.blogspot.com/2015/01/afl-fuzz-making-up-grammar-with.html) 大体上,当基本的(basic, typically easily-obtained)句法(syntax)符号(tokens)以纯粹随机的方式组合在一起时,**插桩**和**队列进化**这两种方法共同提供了一种反馈机制,这种反馈机制能够区分无意义的变异和在插桩代码中触发新行为的变异。这样能增量地构建更复杂的句法(syntax)。 这样构建的字典能够让fuzzer快速地重构非常详细(highly verbose)且复杂的(complex)语法,比如JavaScript, SQL,XML。一些生成SQL语句的例子已经在之前提到的博客中给出了。 有趣的是,AFL的插桩也允许fuzzer自动地隔离(isolate)已经在输入文件中出现过的句法(syntax)符号(tokens)。 ## 8) 崩溃去重(De-duping crashes) 崩溃去重是fuzzing工具里很重要的问题之一。很多naive的解决方式都会有这样的问题:如果这个错误发生在一个普通的库函数中(如say, strcmp, strcpy),只关注出错地址(faulting address)的话,那么可能导致一些完全不相关的问题被分在一类(clustered together)。如果错误发生在一些不同的、可能递归的代码路径中,那么校验和(checksumming)调用栈回溯(call stack backtraces)时可能导致crash count inflation(通胀)。 afl-fuzz的解决方案认为满足一下两个条件,那么这个crash就是唯一的(unique):
The crash trace includes a tuple not seen in any of the previous crashes,这个crash的路径包括一个之前crash从未见到过的tuple。
+The crash trace is missing a tuple that was always present in earlier faults.这个crash的路径不包含一个总在之前crash中出现的tuple。
+1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 这种方式一开始容易受到count inflation的影响,但实验表明其有很强的自我限制效果。和执行路径分析一样,这种 **崩溃去重** 的方式是afl-fuzz的基石(cornerstone)。 ## 9) 崩溃调查(Investigating crashes) 不同的crash的可用性(exploitability)是不同的。afl-fuzz提供一个crash的探索模式(exploration mode)来解决这个问题。 对一个已知的出错测试用例,它被fuzz的方式和正常fuzz的操作没什么不同,但是有一个限制能让任何non-crashing 的变异(mutations)会被丢弃(thrown away)。 这种方法的意义在以下链接中会进一步讨论: [afl-fuzz-crash-exploration-mode](http://lcamtuf.blogspot.com/2014/11/afl-fuzz-crash-exploration-mode.html) 这种方法利用**instrumentation的反馈**,探索crash程序的状态,从而进一步通过歧义性的失败条件,找到了最新发现的input。 对于crashes来说,值得注意的是和正常的队列条目对比,导致crash的input没有被去掉,为了和它们的父条目(队列中没有导致crash的条目)对比,它们被保存下来, 这就是说afl-tmin可以被用来随意缩减它们。 ## 10) The fork server 为了提升性能,afl-fuzz使用了一个"fork server",fuzz的进程只进行一次execve(), 连接(linking), 库初始化(libc initialization)。fuzz进程通过copy-on-write(写时拷贝技术)从已停止的fuzz进程中clone下来。实现细节在以下链接中: [fuzzing-binaries-without-execve](http://lcamtuf.blogspot.com/2014/10/fuzzing-binaries-without-execve.html) fork server被集成在了instrumentation的程序下,在第一个instrument函数执行时,fork server就停止并等待afl-fuzz的命令。 对于需要快速发包的测试,fork server可以提升1.5到2倍的性能。 ## 11) 并行机制 实现并行的机制是,定期检查不同cpu core或不同机器产生的队列,然后有选择性的把队列中的条目放到test cases中。 详见: parallel_fuzzing.txt. ## 12)二进制instrumentation AFL-Fuzz对二进制黑盒目标程序的instrumentation是通过**QEMU**的“user emulation”模式实现的。 这样我们就可以允许跨架构的运行,比如ARM binaries运行在X86的架构上。 QEMU使用basic blocks作为翻译单元,利用QEMU做instrumentation,再使用一个和编译期instrumentation类似的**guided fuzz**的模型。
if (block_address > elf_text_start && block_address < elf_text_end) {
+cur_location = (block_address >> 4) ^ (block_address << 8);
+}`
+
-3)用于AFL的插桩(instrumentation)程序 当源代码可用时,可以通过配套工具注入instrumentation,该工具可作为第三方代码的任何标准构建过程中gcc或clang的替代品。
-重新编译目标程序的正确方法可能会有所不同,具体取决于构建过程的具体情况,但几乎通用的方法是:1 2 3 $ CC = / path / to / afl / afl-gcc ./configure $ make clean all 对于C ++程序,您还需要将CXX = / path /设置为/ afl / afl g ++。
-clang组件(afl-clang和afl-clang ++)可以以相同的方式使用; clang用户也可以选择利用更高性能的检测模式,如llvm_mode / README.llvm中所述。
-在测试库时,您需要查找或编写一个简单的程序,该程序从stdin或文件中读取数据并将其传递给测试的库。在这种情况下,必须将此可执行文件与已检测库的静态版本相链接,或者确保在运行时加载正确的.so文件(通常通过设置LD_LIBRARY_PATH)。最简单的选项是静态构建,通常可以通过以下方式实现:1 $ CC = / path / to / afl / afl-gcc ./configure --disable-shared
-调用’make’时设置AFL_HARDEN = 1将导致CC组件自动启用代码强化选项,以便更容易检测到简单的内存错误。 Libdislocator,AFL附带的帮助程序库(请参阅libdislocator / README.dislocator)也可以帮助发现堆损坏问题。
-4)检测仅二进制应用程序 当源代码为不可得时,afl为黑盒二进制文件的快速、即时检测提供实验支持。 这是通过在较不为人知的“用户空间仿真”模式下运行的QEMU版本来实现的。
-QEMU是一个独立于AFL的项目,但您可以通过以下方式方便地构建该功能:
-1 2 $ cd qemu_mode $ ./build_qemu_support.sh
有关其他说明和注意事项,请参阅qemu_mode / README.qemu。
-该模式比编译时插桩(instrumentation)慢约2-5倍,对并行化的兼容较差,并且可能有一些其他的不同。
-5)选择初始测试用例 为了正确操作,模糊器需要一个或多个起始文件,其中包含目标应用程序通常所需的输入数据的良好示例。 有两个基本规则:
-
-测试用例足够小。 1 kB以下是理想的,尽管不是绝对必要的。 有关大小重要性的讨论,请参阅perf_tips.txt。
-只有在功能上彼此不同时才使用多个测试用例。 使用五十张不同的度假照片来模糊图像库是没有意义的。afl-cmin实用程序来识别在目标二进制文件中使用不同代码路径的功能不同的文件的子集。
-
-6)模糊测试二进制文件 测试过程本身由afl-fuzz实用程序执行。该程序需要一个带有初始测试用例的只读目录,一个存储其发现的独立位置,以及要测试的二进制文件的路径。1 $ ./afl-fuzz -i testcase_dir -o findings_dir / path / to / program [... params ...]
-对于从文件中获取输入的程序,使用“@@”标记目标命令行中应放置输入文件名的位置。模糊器将替换为您:1 $ ./afl-fuzz -i testcase_dir -o findings_dir / path / to / program @@
-您还可以使用-f选项将变异数据写入特定文件。如果程序需要特定的文件扩展名,那么这很有用。
-请注意,afl-fuzz首先执行一系列确定性模糊测试步骤,这可能需要几天时间,但往往会产生整齐的测试用例。如果你想要快速结果 - 类似于zzuf和其他传统的模糊器 - 在命令行中添加-d选项。
-7)解释输出 有关如何解释显示的统计信息以及监视进程运行状况的信息,请参阅status_screen.txt文件。请务必查阅此文件,尤其是如果任何UI元素以红色突出显示。
-
-队列/ - 测试每个独特执行路径的案例,以及用户提供的所有起始文件。这是第2节中提到的合成语料库。在将此语料库用于任何其他目的之前,您可以使用afl-cmin工具将其缩小到较小的大小。该工具将找到一个较小的文件子集,提供相同的边缘覆盖。
-崩溃/ - 导致被测程序接收致命信号的独特测试用例(例如,SIGSEGV,SIGILL,SIGABRT)。条目按接收信号分组。
-挂起/ - 导致测试程序超时的独特测试用例。将某些内容归类为挂起之前的默认时间限制是1秒内的较大值和-t参数的值。可以通过设置AFL_HANG_TMOUT来微调该值,但这很少是必需的。崩溃和挂起被视为“唯一” “如果相关的执行路径涉及在先前记录的故障中未见的任何状态转换。如果可以通过多种方式达到单个错误,那么在此过程中会有一些计数通货膨胀,但这应该会迅速逐渐减少。
-
-崩溃和挂起的文件名与父、非错误的队列条目相关联。这应该有助于调试。1 2 $ LIMIT_MB = 50 $(ulimit -Sv $ [LIMIT_MB << 10]; / path / to / tested_binary ...)
-更改LIMIT_MB以匹配传递给afl-fuzz的-m参数。在OpenBSD上,也将-Sv更改为-Sd。任何现有的输出目录也可用于恢复中止的作业;尝试:$ ./afl-fuzz -i-o_ existing_output_dir [...等...]http://lcamtuf.coredump.cx/afl/plot/ 。
-8)并行模糊测试 每个afl-fuzz的实例大约占用一个核。 这意味着在多核系统上,并行化是充分利用硬件所必需的。
-9)Fuzzer词典 默认情况下,afl-fuzz变异引擎针对紧凑数据格式进行了优化 - 例如,图像,多媒体,压缩数据,正则表达式语法或shell脚本。它有点不太适合具有特别冗长和冗余的语言的语言 - 特别是包括HTML,SQL或JavaScript。http://lcamtuf.blogspot.com/2015/01/afl-fuzz-making-up-grammar-with.html http://lcamtuf.blogspot.com/2015/04/finding-bugs-in-sqlite-easy-way.html
-10)崩溃分类 基于coverage的崩溃分组通常会生成一个小型数据集,可以手动或使用非常简单的GDB或Valgrind脚本快速进行分类。每次崩溃都可以追溯到队列中的父级非崩溃测试用例,从而更容易诊断故障。
-哦,还有一件事:对于测试用例最小化,请尝试afl-tmin。该工具可以以非常简单的方式操作:$ ./afl-tmin -i test_case -o minimize_result - / path / to / program [...]
-该工具适用于崩溃和非崩溃的测试用例。在崩溃模式下,它将很乐意接受 instrumented 和 non-instrumented 的二进制文件。在非崩溃模式下,最小化器依赖于标准AFL检测来使文件更简单而不改变执行路径。minimizer与afl-fuzz兼容的方式接受-m,-t,-f和@@语法。
-AFL的另一个新成员是afl-analyze工具。需要输入文件,尝试按顺序翻转字节,并观察测试程序的行为。然后根据哪些部分看起来是关键的,哪些部分不是关键的,对输入进行颜色编码;虽然不是万能,但它通常可以提供对复杂文件格式的快速见解。有关其操作的更多信息可以在technical_details.txt的末尾找到。
-11)超越崩溃 模糊测试是一种很好的,未充分利用的技术,用于发现非崩溃的设计和实现错误。通过修改目标程序调用abort()时发现了一些有趣的错误,比如:
-
-当给出相同的模糊输入时,两个bignum库产生不同的输出,
-当要求连续多次解码相同的输入图像时,图像库会产生不同的输出,
-在对模糊提供的数据进行迭代序列化和反序列化时,序列化/反序列化库无法生成稳定的输出,
-当要求压缩然后解压缩特定blob时,压缩库会生成与输入文件不一致的输出。实施这些或类似的健全性检查通常只需要很少的时间;如果你是特定包的维护者,你可以使用#ifdef FUZZING_BUILD_MODE_UNSAFE_FOR_PRODUCTION(一个也与libfuzzer共享的标志)或#ifdef __AFL_COMPILER(这个只适用于AFL)来使这个代码成为条件。
-
-12)常识性风险 请记住,与许多其他计算密集型任务类似,模糊测试可能会给您的硬件和操作系统带来压力。特别是:
-
-你的CPU会很热,需要充分冷却。在大多数情况下,如果冷却不足或停止正常工作,CPU速度将自动受到限制。也就是说,尤其是在不太合适的硬件(笔记本电脑,智能手机等)上进行模糊测试时,某些事情并非完全不可能爆发。
-有针对性的程序可能最终不正常地抓取千兆字节的内存或用垃圾文件填满磁盘空间。 AFL试图强制执行基本的内存限制,但不能阻止每一个可能的事故。最重要的是,您不应该对数据丢失前景不可接受的系统进行模糊测试。
-模糊测试涉及数十亿次对文件系统的读写操作。在现代系统中,这通常会被高度缓存,导致相当适度的“物理”I/O - 但是有许多因素可能会改变这个等式。您有责任监控潜在的问题; I / O非常繁重,许多HDD和SSD的使用寿命可能会缩短。监视Linux上磁盘I/O的一种好方法是’iostat’命令:$ iostat -d 3 -x -k [...可选磁盘ID ...]
-
-13)已知的限制和需要改进的领域 以下是AFL的一些最重要的警告:
-
-本文档提供了American Fuzzy Lop的简单的概述。想了解一般的使用说明,请参见README 。想了解AFL背后的动机和设计目标,请参见historical_notes.txt 。
-0)设计说明(Design statement) American Fuzzy Lop 不关注任何单一的操作规则(singular principle of
-1)覆盖率计算(Coverage measurements) 在编译过的程序中插桩能够捕获分支(边缘)的覆盖率,并且还能检测到粗略的分支执行命中次数(branch-taken hit counts)。在分支点注入的代码大致如下:
-1 2 3 cur_location = <COMPILE_TIME_RANDOM>; //用一个随机数标记当前基本块 shared_mem[cur_location ^ prev_location]++; //将当前块和前一块异或保存到shared_mem[] prev_location = cur_location >> 1; //cur_location右移1位区分从当前块到当前块的转跳
cur_location的值是随机产生的,为的是简化连接复杂对象的过程和保持XOR输出分布是均匀的。
-
-
-
-Branch cnt
-Colliding tuples
-Example targets
-
-
-
-
-1,000
-0.75%
-giflib, lzo
-
-
-2,000
-1.5%
-zlib, tar, xz
-
-
-5,000
-3.5%
-libpng, libwebp
-
-
-10,000
-7%
-libxml
-
-
-20,000
-14%
-sqlite
-
-
-50,000
-30%
--
-
-
-
-这种形式的覆盖率,相对于简单的基本块覆盖率来说,对程序运行路径提供了一个更好的描述(insight)。特别地,它能很好地区分以下两个执行路径:
-
- A -> B -> C -> D -> E (tuples: AB, BC, CD, DE)
-这有助于发现底层代码的微小错误条件。因为安全漏洞通常是一些非预期(或不正确)的语句转移(一个tuple就是一个语句转移),而不是没覆盖到某块代码。
-
-2)发现新路径(Detecting new behaviors) AFL的fuzzers使用一个全局Map 来存储之前执行时看到的tuple。这些数据可以被用来对不同的trace进行快速对比,从而可以计算出是否新执行了一个dword指令/一个qword-wide指令/一个简单的循环。1 2 #1: A -> B -> C -> D -> E #2: A -> B -> C -> A -> E
-因为#2的原因,以下的路径就不认为是不同的路径了,尽管看起来非常不同:#3: A -> B -> C -> A -> B -> C -> A -> B -> C -> D -> E
-除了检测新的tuple之外,AFL的fuzzer也会粗略地记录tuple的命中数(hit counts) 。这些被分割成几个buckets:
-从某种意义来说,buckets里边的数目是有实际意义的:它是一个8-bit counter和一个8-position bitmap的映射。8-bit counter是由桩生成的,8-position bitmap则依赖于每个fuzzer记录的已执行的tuple的命中数。
-另外,算法通过设置执行超时,来避免效率过低的fuzz。从而进一步发现效率比较高的fuzz方式。
-经变异的测试用例,会使程序产生新的状态转移。这些测试用例稍后被添加到input队列中,用作下一个fuzz循环。它们补充但不替换现有的发现。
-这里有一些这种算法在实际情况下例子:
-pulling-jpegs-out-of-thin-air
-afl-fuzz-nobody-expects-cdata-sections
-这种过程下产生的语料库基本上是这些输入文件的集合:它们都能触发一些新的执行路径。产生的语料库,可以被用来作为其他测试的种子。GNU patch 2.7.3 compiled with -O3 and seeded with a dummy text file:
-
-
-
-Fuzzer guidance strategy used
-Blocks reached
-Edges reached
-Edge hit cnt var
-Highest-coverage test case generated
-
-
-
-
-(Initial file)
-156
-163
-1.00
-(none)
-
-
-Blind fuzzing S
-182
-205
-2.23
-First 2 B of RCS diff
-
-
-Blind fuzzing L
-228
-265
-2.23
-First 4 B of -c mode diff
-
-
-Block coverage
-855
-1,130
-1.57
-Almost-valid RCS diff
-
-
-Edge coverage
-1,452
-2,070
-2.18
-One-chunk -c mode diff
-
-
-AFL model
-1,765
-2,597
-4.99
-Four-chunk -c mode diff
-
-
-
-第一行的blind fuzzing (“S”)代表仅仅执行了一个回合的测试。
-在另一个独立的实验中也取得了大致相似的结果。在新实验中,fuzzer被修改成所有随机fuzzing 策略,只留下一系列基本、连续的操作,例如位反转(bit flips)。因为这种模式(mode)将不能改变输入文件的的大小,会话使用一个合法的合并格式(unified diff)作为种子。
-
-
-
-Queue extension strategy used
-Blocks reached
-Edges reached
-Edge hit cnt var
-Number of unique crashes found
-
-
-
-
-(Initial file)
-624
-717
-1.00
--
-
-
-Blind fuzzing
-1,101
-1,409
-1.60
-0
-
-
-Block coverage
-1,255
-1,649
-1.48
-0
-
-
-Edge coverage
-1,259
-1,734
-1.72
-0
-
-
-AFL model
-1,452
-2,040
-3.16
-1
-
-
-
-在之前提到的基于遗传算法的fuzzing,是通过一个test case的进化(这里指的是用遗传算法进行变异)来实现最大覆盖。在上述实验看来,这种“贪婪”的方法似乎没有为盲目的模糊策略带来实质性的好处。
-4)语料筛选(Culling the corpus) 上文提到的渐进式语句探索路径的方法意味着:假设A和B是测试用例(test cases),且B是由A变异产生的。那么测试用例B达到的边缘覆盖率(edge coverage)是测试用例A达到的边缘覆盖率的严格超集(superset)。周期性的重新评估 (re-evaluates)队列,这种算法会选择队列的一个更小的子集,并且这个子集仍能覆盖所有的tuple。算法的这个特性对这个工具特别有利(favorable)。最低分值的entry 。
-1 2 3 4 5 6 7 1) Find next tuple not yet in the temporary working set, 2) Locate the winning queue entry for this tuple, 3) Register *all* tuples present in that entry's trace in the working set, 4) Go to #1 if there are any missing tuples in the set.
“favored” entries产生的语料,会比初始的数据集小5到10倍。没有被选择的也没有被扔掉,而是在遇到下列对队列时,以一定概率略过:1 2 3 4 5 6 7 8 - If there are new, yet-to-be-fuzzed favorites present in the queue, 99% of non-favored entries will be skipped to get to the favored ones. - If there are no new favorites: - If the current non-favored entry was fuzzed before, it will be skipped 95% of the time. - If it hasn't gone through any fuzzing rounds yet, the odds of skipping drop down to 75%.
-基于以往的实验经验,这种方法能够在队列周期速度(queue cycling speed)和测试用例多样性(test case diversity)之间达到一个合理的平衡。afl-cmin工具 能够对输入或输出的语料库进行稍微复杂但慢得多的的处理。这一工具将永久丢弃冗余entries,产生适用于afl-fuzz或者外部工具的更小的语料库。
-文件的大小对fuzzing的性能有着重大影响(dramatic impact)。因为大文件会让目标二进制文件运行变慢;大文件还会减少变异触及重要格式控制结构(format control structures)的可能性(我们希望的是变异要触及冗余代码块(redundant data blocks) )。这个问题将在perf_tips.txt 细说。插桩反馈(instrumentation feedback) 提供了一种简单的方式自动削减(trim down)输入文件,并确保这些改变能使得文件对执行路径没有影响。afl-tmin工具 使用更完整(exhaustive)、迭代次数更多(iteractive)的算法,并尝试对被修剪的文件采用字母标准化的方式处理。
-6) 模糊测试策略(Fuzzing strategies) 插桩提供的反馈(feedback)使得我们更容易理解各种不同fuzzing策略的价值,从而优化(optimize)他们的参数。使得他们对不同的文件类型都能同等地进行工作。afl-fuzz用的策略通常是与格式无关(format-agnostic),详细说明在下边的连接中:binary-fuzzing-strategies-what-works 1 2 3 4 5 - Sequential bit flips with varying lengths and stepovers,使用变化的长度和步距来连续进行位反转 - Sequential addition and subtraction of small integers,对小的整型数来连续进行加法和减法 - Sequential insertion of known interesting integers (0, 1, INT_MAX, etc),对已知的感兴趣的整型数连续地插入
-使用这些确定步骤的目的在于,生成紧凑的(compact)测试用例,以及在产生non-crashing的输入和产生crashing的输入之间,有很小的差异(small diffs)。
-由于在historical_notes.txt 中提到的原因(性能、简易性、可靠性),AFL通常不试图去推断某个特定的变异(specific mutations)和程序状态(program states)的关系。
-fuzzing的步骤名义上来说是盲目的(nominally blind),只被输入队列的进化方式的设计所影响(见第三部分 )。
-这意味着,这条规则有一个例外:
-7) 字典(Dictionaries) 插桩提供的反馈能够让它自动地识别出一些输入文件中的语法(syntax)符号(tokens),并且能够为测试器(tested parser)检测到一些组合,这些组合是由预定义(predefined)的或自动检测到的(auto-detected)字典项(dictionary terms)构成的合法语法(valid grammar)。afl-fuzz-making-up-grammar-with 插桩 和队列进化 这两种方法共同提供了一种反馈机制,这种反馈机制能够区分无意义的变异和在插桩代码中触发新行为的变异。这样能增量地构建更复杂的句法(syntax)。
-8) 崩溃去重(De-duping crashes) 崩溃去重是fuzzing工具里很重要的问题之一。很多naive的解决方式都会有这样的问题:如果这个错误发生在一个普通的库函数中(如say, strcmp, strcpy),只关注出错地址(faulting address)的话,那么可能导致一些完全不相关的问题被分在一类(clustered together)。如果错误发生在一些不同的、可能递归的代码路径中,那么校验和(checksumming)调用栈回溯(call stack backtraces)时可能导致crash count inflation(通胀)。
-afl-fuzz的解决方案认为满足一下两个条件,那么这个crash就是唯一的(unique):1 2 - The crash trace includes a tuple not seen in any of the previous crashes,这个crash的路径包括一个之前crash从未见到过的tuple。 - The crash trace is missing a tuple that was always present in earlier faults.这个crash的路径不包含一个总在之前crash中出现的tuple。
-这种方式一开始容易受到count inflation的影响,但实验表明其有很强的自我限制效果。和执行路径分析一样,这种崩溃去重的方式是afl-fuzz的基石(cornerstone)。
-9) 崩溃调查(Investigating crashes) 不同的crash的可用性(exploitability)是不同的。afl-fuzz提供一个crash的探索模式(exploration mode)来解决这个问题。afl-fuzz-crash-exploration-mode instrumentation的反馈 ,探索crash程序的状态,从而进一步通过歧义性的失败条件,找到了最新发现的input。
-10) The fork server 为了提升性能,afl-fuzz使用了一个”fork server”,fuzz的进程只进行一次execve(), 连接(linking), 库初始化(libc initialization)。fuzz进程通过copy-on-write(写时拷贝技术)从已停止的fuzz进程中clone下来。实现细节在以下链接中:afl-fuzz-crash-exploration-mode
-11) 并行机制 实现并行的机制是,定期检查不同cpu core或不同机器产生的队列,然后有选择性的把队列中的条目放到test cases中。
-12)二进制instrumentation AFL-Fuzz对二进制黑盒目标程序的instrumentation是通过QEMU 的“user emulation”模式实现的。guided fuzz 的模型。1 2 3 4 5 6 7 if (block_address > elf_text_start && block_address < elf_text_end) { cur_location = (block_address >> 4) ^ (block_address << 8); shared_mem[cur_location ^ prev_location]++; prev_location = cur_location >> 1; }
-像QEMU, DynamoRIO, and PIN这样的二进制翻译器,启动是很慢的。QEMU mode同样使用了一个fork server,和编译期一样,通过把一个已经初始化好的进程镜像,直接拷贝到新的进程中。
13)afl-analyze工具 文件格式分析器是最小化算法的简单扩展
@@ -826,8 +588,8 @@
@@ -991,7 +753,7 @@
-
+
@@ -1023,7 +785,7 @@
48k
+ 48.3k
diff --git a/2019/07/09/afl-first-try/index.html b/2019/07/09/afl-first-try/index.html
index 27781eff..1d797ad9 100644
--- a/2019/07/09/afl-first-try/index.html
+++ b/2019/07/09/afl-first-try/index.html
@@ -82,15 +82,15 @@
AFL初次实践 | 混元霹雳手
+ AFL-爱之初体验 | 混元霹雳手
@@ -324,7 +324,7 @@
- AFL初次实践
+ AFL-爱之初体验
@@ -386,7 +386,7 @@
-
+
|
1 2 3 4 5 6 7 8 > $ CPU_TARGET=x86_64 ./build_qemu_support.sh > [+] Build process successful! > [*] Copying binary... > -rwxr-xr-x 1 han han 10972920 7月 9 10:43 ../afl-qemu-trace > [+] Successfully created '../afl-qemu-trace'. > [!] Note: can't test instrumentation when CPU_TARGET set. > [+] All set, you can now (hopefully) use the -Q mode in afl-fuzz! >
白盒测试 目标程序编译
+0x01白盒测试 目标程序编译
源代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 #undef _FORTIFY_SOURCE #include <stdio.h> #include <stdlib.h> #include <unistd.h> void vulnerable_function() { char buf[128]; read(STDIN_FILENO, buf, 256); } int main(int argc, char** argv) { vulnerable_function(); write(STDOUT_FILENO, "Hello, World\n", 13); }
gcc编译(不插桩)
--ftest-coverage 1 2 3 4 $ gcc v1.c -o v1 $ ./v1 what Hello, World
1 2 3 4 $ gcc v1.c -o v1 $ ./v1 what Hello, World
生成v1的目的一是为了和afl-gcc的编译做对比,二是为黑盒测试做铺垫。
@@ -509,11 +509,11 @@
plot_data:用于afl-plot绘图。
崩溃类型和可利用性
-triage_crashes
-
+triage_crashes
1 2 $ experimental/crash_triage/triage_crashes.sh ../vuln/out/ ../vuln/v1-afl 2>&1 | grep SIGNAL +++ ID 000000, SIGNAL 11 +++
-crashwalk1 2 3 4 5 6 7 8 $ apt-get install gdb golang $ mkdir tools $ cd tools $ git clone https://github.com/jfoote/exploitable.git $ mkdir go $ export GOPATH=~/tools/go $ export CW_EXPLOITABLE=~/tools/exploitable/exploitable/exploitable.py $ go get -u github.com/bnagy/crashwalk/cmd/...
+crashwalk
+1 2 3 4 5 6 7 8 $ apt-get install gdb golang $ mkdir tools $ cd tools $ git clone https://github.com/jfoote/exploitable.git $ mkdir go $ export GOPATH=~/tools/go $ export CW_EXPLOITABLE=~/tools/exploitable/exploitable/exploitable.py $ go get -u github.com/bnagy/crashwalk/cmd/...
代码覆盖率及其相关概念
+0x02代码覆盖率及其相关概念
代码覆盖率是模糊测试中一个极其重要的概念,使用代码覆盖率可以评估和改进测试过程,执行到的代码越多,找到bug的可能性就越大,毕竟,在覆盖的代码中并不能100%发现bug,在未覆盖的代码中却是100%找不到任何bug的。
计算代码覆盖率 GCOV :插桩生成覆盖率 LCOV :图形展示覆盖率 afl-cov :调用前两个工具计算afl测试用例的覆盖率
-gcc插桩
+gcc插桩-fprofile-arcs -ftest-coverage
1 $ gcc -fprofile-arcs -ftest-coverage ./v1.c -o v1-cov
afl-cov计算之前fuzzer的过程(结束后)
@@ -540,7 +540,7 @@
黑盒测试(使用qemu 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 $ ./afl-fuzz -i ../vuln/testcase/ -o ../vuln/outQemu -Q ../vuln/v1 american fuzzy lop 2.52b (v1) ┌─ process timing ─────────────────────────────────────┬─ overall results ─────┐ │ run time : 0 days, 0 hrs, 0 min, 41 sec │ cycles done : 232 │ │ last new path : none yet (odd, check syntax!) │ total paths : 2 │ │ last uniq crash : 0 days, 0 hrs, 0 min, 41 sec │ uniq crashes : 1 │ │ last uniq hang : none seen yet │ uniq hangs : 0 │ ├─ cycle progress ────────────────────┬─ map coverage ─┴───────────────────────┤ │ now processing : 0* (0.00%) │ map density : 0.04% / 0.04% │ │ paths timed out : 0 (0.00%) │ count coverage : 1.00 bits/tuple │ ├─ stage progress ────────────────────┼─ findings in depth ────────────────────┤ │ now trying : havoc │ favored paths : 1 (50.00%) │ │ stage execs : 255/256 (99.61%) │ new edges on : 1 (50.00%) │ │ total execs : 121k │ total crashes : 33 (1 unique) │ │ exec speed : 2860/sec │ total tmouts : 0 (0 unique) │ ├─ fuzzing strategy yields ───────────┴───────────────┬─ path geometry ────────┤ │ bit flips : 0/56, 0/54, 0/50 │ levels : 1 │ │ byte flips : 0/7, 0/5, 0/1 │ pending : 0 │ │ arithmetics : 0/392, 0/25, 0/0 │ pend fav : 0 │ │ known ints : 0/36, 0/138, 0/44 │ own finds : 0 │ │ dictionary : 0/0, 0/0, 0/0 │ imported : n/a │ │ havoc : 1/120k, 0/0 │ stability : 100.00% │ │ trim : 82.61%/5, 0.00% ├────────────────────────┘ ^C────────────────────────────────────────────────────┘ [cpu000:102%]
0x03黑盒测试(使用qemu 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 $ ./afl-fuzz -i ../vuln/testcase/ -o ../vuln/outQemu -Q ../vuln/v1 american fuzzy lop 2.52b (v1) ┌─ process timing ─────────────────────────────────────┬─ overall results ─────┐ │ run time : 0 days, 0 hrs, 0 min, 41 sec │ cycles done : 232 │ │ last new path : none yet (odd, check syntax!) │ total paths : 2 │ │ last uniq crash : 0 days, 0 hrs, 0 min, 41 sec │ uniq crashes : 1 │ │ last uniq hang : none seen yet │ uniq hangs : 0 │ ├─ cycle progress ────────────────────┬─ map coverage ─┴───────────────────────┤ │ now processing : 0* (0.00%) │ map density : 0.04% / 0.04% │ │ paths timed out : 0 (0.00%) │ count coverage : 1.00 bits/tuple │ ├─ stage progress ────────────────────┼─ findings in depth ────────────────────┤ │ now trying : havoc │ favored paths : 1 (50.00%) │ │ stage execs : 255/256 (99.61%) │ new edges on : 1 (50.00%) │ │ total execs : 121k │ total crashes : 33 (1 unique) │ │ exec speed : 2860/sec │ total tmouts : 0 (0 unique) │ ├─ fuzzing strategy yields ───────────┴───────────────┬─ path geometry ────────┤ │ bit flips : 0/56, 0/54, 0/50 │ levels : 1 │ │ byte flips : 0/7, 0/5, 0/1 │ pending : 0 │ │ arithmetics : 0/392, 0/25, 0/0 │ pend fav : 0 │ │ known ints : 0/36, 0/138, 0/44 │ own finds : 0 │ │ dictionary : 0/0, 0/0, 0/0 │ imported : n/a │ │ havoc : 1/120k, 0/0 │ stability : 100.00% │ │ trim : 82.61%/5, 0.00% ├────────────────────────┘ ^C────────────────────────────────────────────────────┘ [cpu000:102%]
48k
+ 48.3k
diff --git a/about/index.html b/about/index.html
index c548864c..2f4ececc 100644
--- a/about/index.html
+++ b/about/index.html
@@ -460,7 +460,7 @@
48k
+ 48.3k
diff --git a/archives/2000/01/index.html b/archives/2000/01/index.html
index 7f75c15d..3b1d4ce6 100644
--- a/archives/2000/01/index.html
+++ b/archives/2000/01/index.html
@@ -490,7 +490,7 @@
48k
+ 48.3k
diff --git a/archives/2000/index.html b/archives/2000/index.html
index 602d1138..f39b7c71 100644
--- a/archives/2000/index.html
+++ b/archives/2000/index.html
@@ -490,7 +490,7 @@
48k
+ 48.3k
diff --git a/archives/2018/11/index.html b/archives/2018/11/index.html
index 5e1aba15..7fa79a1e 100644
--- a/archives/2018/11/index.html
+++ b/archives/2018/11/index.html
@@ -490,7 +490,7 @@
48k
+ 48.3k
diff --git a/archives/2018/12/index.html b/archives/2018/12/index.html
index 205e441b..130b0f05 100644
--- a/archives/2018/12/index.html
+++ b/archives/2018/12/index.html
@@ -560,7 +560,7 @@
48k
+ 48.3k
diff --git a/archives/2018/index.html b/archives/2018/index.html
index 50d68026..d382db54 100644
--- a/archives/2018/index.html
+++ b/archives/2018/index.html
@@ -595,7 +595,7 @@
48k
+ 48.3k
diff --git a/archives/2019/01/index.html b/archives/2019/01/index.html
index cde1a3cb..657f16f8 100644
--- a/archives/2019/01/index.html
+++ b/archives/2019/01/index.html
@@ -490,7 +490,7 @@
48k
+ 48.3k
diff --git a/archives/2019/02/index.html b/archives/2019/02/index.html
index df7ab6aa..1155c452 100644
--- a/archives/2019/02/index.html
+++ b/archives/2019/02/index.html
@@ -490,7 +490,7 @@
48k
+ 48.3k
diff --git a/archives/2019/03/index.html b/archives/2019/03/index.html
index aa445787..2c863807 100644
--- a/archives/2019/03/index.html
+++ b/archives/2019/03/index.html
@@ -595,7 +595,7 @@
48k
+ 48.3k
diff --git a/archives/2019/04/index.html b/archives/2019/04/index.html
index 16910418..f6d2a7ea 100644
--- a/archives/2019/04/index.html
+++ b/archives/2019/04/index.html
@@ -525,7 +525,7 @@
48k
+ 48.3k
diff --git a/archives/2019/05/index.html b/archives/2019/05/index.html
index a97e1a0e..528001d6 100644
--- a/archives/2019/05/index.html
+++ b/archives/2019/05/index.html
@@ -525,7 +525,7 @@
48k
+ 48.3k
diff --git a/archives/2019/07/index.html b/archives/2019/07/index.html
index c9ece070..d888f5d3 100644
--- a/archives/2019/07/index.html
+++ b/archives/2019/07/index.html
@@ -325,7 +325,7 @@
- AFL初次实践
+ AFL-爱之初体验
@@ -525,7 +525,7 @@
48k
+ 48.3k
diff --git a/archives/2019/index.html b/archives/2019/index.html
index 2374192f..eca0e994 100644
--- a/archives/2019/index.html
+++ b/archives/2019/index.html
@@ -325,7 +325,7 @@
- AFL初次实践
+ AFL-爱之初体验
@@ -809,7 +809,7 @@
48k
+ 48.3k
diff --git a/archives/2019/page/2/index.html b/archives/2019/page/2/index.html
index 3ab3cb41..9107c967 100644
--- a/archives/2019/page/2/index.html
+++ b/archives/2019/page/2/index.html
@@ -529,7 +529,7 @@
48k
+ 48.3k
diff --git a/archives/index.html b/archives/index.html
index 64749a4d..385037dc 100644
--- a/archives/index.html
+++ b/archives/index.html
@@ -325,7 +325,7 @@
- AFL初次实践
+ AFL-爱之初体验
@@ -809,7 +809,7 @@
48k
+ 48.3k
diff --git a/archives/page/2/index.html b/archives/page/2/index.html
index ddbaf79b..3dc15aaf 100644
--- a/archives/page/2/index.html
+++ b/archives/page/2/index.html
@@ -714,7 +714,7 @@
48k
+ 48.3k
diff --git a/baidusitemap.xml b/baidusitemap.xml
index 47f96e51..142dd1d1 100644
--- a/baidusitemap.xml
+++ b/baidusitemap.xml
@@ -5,7 +5,7 @@
2019-07-09
https://cool-y.github.io/2019/07/01/AFL-first-learn/
- 2019-07-08
+ 2019-07-09
https://cool-y.github.io/2019/05/14/pack-and-unpack/
2019-07-01
diff --git a/bookmarks/index.html b/bookmarks/index.html
index fa20275c..f04d331f 100644
--- a/bookmarks/index.html
+++ b/bookmarks/index.html
@@ -512,7 +512,7 @@
48k
+ 48.3k
diff --git a/categories/IOT/index.html b/categories/IOT/index.html
index 2588cd63..2f8ba3e1 100644
--- a/categories/IOT/index.html
+++ b/categories/IOT/index.html
@@ -549,7 +549,7 @@
48k
+ 48.3k
diff --git a/categories/index.html b/categories/index.html
index 383490c5..a4612495 100644
--- a/categories/index.html
+++ b/categories/index.html
@@ -462,7 +462,7 @@
48k
+ 48.3k
diff --git a/categories/二进制/index.html b/categories/二进制/index.html
index 1e643557..5c5dc036 100644
--- a/categories/二进制/index.html
+++ b/categories/二进制/index.html
@@ -307,7 +307,7 @@
- AFL初次实践
+ AFL-爱之初体验
@@ -575,7 +575,7 @@
48k
+ 48.3k
diff --git a/categories/加密解密/index.html b/categories/加密解密/index.html
index b1c075a5..67069858 100644
--- a/categories/加密解密/index.html
+++ b/categories/加密解密/index.html
@@ -471,7 +471,7 @@
48k
+ 48.3k
diff --git a/categories/杂七杂八/index.html b/categories/杂七杂八/index.html
index e2072895..18700b46 100644
--- a/categories/杂七杂八/index.html
+++ b/categories/杂七杂八/index.html
@@ -471,7 +471,7 @@
48k
+ 48.3k
diff --git a/categories/理论学习/index.html b/categories/理论学习/index.html
index 0c334d24..52f75fa1 100644
--- a/categories/理论学习/index.html
+++ b/categories/理论学习/index.html
@@ -471,7 +471,7 @@
48k
+ 48.3k
diff --git a/categories/顶会论文/index.html b/categories/顶会论文/index.html
index 653133d4..988cad74 100644
--- a/categories/顶会论文/index.html
+++ b/categories/顶会论文/index.html
@@ -523,7 +523,7 @@
48k
+ 48.3k
diff --git a/index.html b/index.html
index 909ac8e5..7f992dd2 100644
--- a/index.html
+++ b/index.html
@@ -320,7 +320,7 @@
+ AFL-爱之初体验
@@ -372,7 +372,7 @@
-
+
|
- 11.4k 字
+ 11.7k 字
@@ -598,7 +598,7 @@
- 42 分钟
+ 44 分钟
@@ -2321,7 +2321,7 @@ WinDbg
48k
+ 48.3k
diff --git a/page/2/index.html b/page/2/index.html
index 6f253f48..92068481 100644
--- a/page/2/index.html
+++ b/page/2/index.html
@@ -1730,7 +1730,7 @@ ettercap嗅探智能设备和网关之间的流量sudo ettercap -i ens33 -T -q
48k
+ 48.3k
diff --git a/search.xml b/search.xml
index 5e809085..0d8c8579 100644
--- a/search.xml
+++ b/search.xml
@@ -1,9 +1,9 @@
- <![CDATA[AFL初次实践]]>
+ <![CDATA[AFL-爱之初体验]]>
%2F2019%2F07%2F09%2Fafl-first-try%2F
-
二进制
@@ -15,7 +15,7 @@
<![CDATA[AFL初探]]>
%2F2019%2F07%2F01%2FAFL-first-learn%2F
-
二进制
diff --git a/sitemap.xml b/sitemap.xml
index 385ed63e..84ec15a7 100644
--- a/sitemap.xml
+++ b/sitemap.xml
@@ -4,14 +4,14 @@
https://cool-y.github.io/2019/07/09/afl-first-try/
- 2019-07-09T06:47:08.044Z
+ 2019-07-09T08:57:59.215Z
https://cool-y.github.io/2019/07/01/AFL-first-learn/
- 2019-07-08T06:09:11.627Z
+ 2019-07-09T08:54:33.951Z
diff --git a/tags/AFL/index.html b/tags/AFL/index.html
index 3819555d..32936a39 100644
--- a/tags/AFL/index.html
+++ b/tags/AFL/index.html
@@ -307,7 +307,7 @@
- AFL初次实践
+ AFL-爱之初体验
@@ -496,7 +496,7 @@
48k
+ 48.3k
diff --git a/tags/CVE/index.html b/tags/CVE/index.html
index d1e2b12c..0b371dfd 100644
--- a/tags/CVE/index.html
+++ b/tags/CVE/index.html
@@ -470,7 +470,7 @@
48k
+ 48.3k
diff --git a/tags/MiniUPnP/index.html b/tags/MiniUPnP/index.html
index fa74901d..84db6615 100644
--- a/tags/MiniUPnP/index.html
+++ b/tags/MiniUPnP/index.html
@@ -470,7 +470,7 @@
48k
+ 48.3k
diff --git a/tags/PE/index.html b/tags/PE/index.html
index 6955bdf5..873441b3 100644
--- a/tags/PE/index.html
+++ b/tags/PE/index.html
@@ -470,7 +470,7 @@
48k
+ 48.3k
diff --git a/tags/QQ/index.html b/tags/QQ/index.html
index 083a3489..e7d18909 100644
--- a/tags/QQ/index.html
+++ b/tags/QQ/index.html
@@ -470,7 +470,7 @@
48k
+ 48.3k
diff --git a/tags/SSH/index.html b/tags/SSH/index.html
index 399343e1..429c3eda 100644
--- a/tags/SSH/index.html
+++ b/tags/SSH/index.html
@@ -470,7 +470,7 @@
48k
+ 48.3k
diff --git a/tags/Samba/index.html b/tags/Samba/index.html
index 39280f94..dd04543a 100644
--- a/tags/Samba/index.html
+++ b/tags/Samba/index.html
@@ -470,7 +470,7 @@
48k
+ 48.3k
diff --git a/tags/TCPDUMP/index.html b/tags/TCPDUMP/index.html
index 704ac561..673b9da3 100644
--- a/tags/TCPDUMP/index.html
+++ b/tags/TCPDUMP/index.html
@@ -470,7 +470,7 @@
48k
+ 48.3k
diff --git a/tags/USENIX/index.html b/tags/USENIX/index.html
index 086d08d7..dbdadf80 100644
--- a/tags/USENIX/index.html
+++ b/tags/USENIX/index.html
@@ -470,7 +470,7 @@
48k
+ 48.3k
diff --git a/tags/index.html b/tags/index.html
index 007256a9..204eb6c8 100644
--- a/tags/index.html
+++ b/tags/index.html
@@ -462,7 +462,7 @@
48k
+ 48.3k
diff --git a/tags/itchat/index.html b/tags/itchat/index.html
index 3e7a083d..75271650 100644
--- a/tags/itchat/index.html
+++ b/tags/itchat/index.html
@@ -470,7 +470,7 @@
48k
+ 48.3k
diff --git a/tags/miio/index.html b/tags/miio/index.html
index b8fa3cfb..ba6b8239 100644
--- a/tags/miio/index.html
+++ b/tags/miio/index.html
@@ -470,7 +470,7 @@
48k
+ 48.3k
diff --git a/tags/python/index.html b/tags/python/index.html
index 7ea68e6a..10e434fa 100644
--- a/tags/python/index.html
+++ b/tags/python/index.html
@@ -470,7 +470,7 @@
48k
+ 48.3k
diff --git a/tags/wifi/index.html b/tags/wifi/index.html
index 1947faa5..8bb07b13 100644
--- a/tags/wifi/index.html
+++ b/tags/wifi/index.html
@@ -470,7 +470,7 @@
48k
+ 48.3k
diff --git a/tags/中间人/index.html b/tags/中间人/index.html
index e26cbae9..2d316735 100644
--- a/tags/中间人/index.html
+++ b/tags/中间人/index.html
@@ -470,7 +470,7 @@
48k
+ 48.3k
diff --git a/tags/侧信道攻击/index.html b/tags/侧信道攻击/index.html
index 1d1a85ea..91df5a9b 100644
--- a/tags/侧信道攻击/index.html
+++ b/tags/侧信道攻击/index.html
@@ -470,7 +470,7 @@
48k
+ 48.3k
diff --git a/tags/取证/index.html b/tags/取证/index.html
index 4e28a930..0969ef43 100644
--- a/tags/取证/index.html
+++ b/tags/取证/index.html
@@ -470,7 +470,7 @@
48k
+ 48.3k
diff --git a/tags/复原文件/index.html b/tags/复原文件/index.html
index a35c8a21..85f2bedb 100644
--- a/tags/复原文件/index.html
+++ b/tags/复原文件/index.html
@@ -470,7 +470,7 @@
48k
+ 48.3k
diff --git a/tags/密码/index.html b/tags/密码/index.html
index e1f0b10a..c419656f 100644
--- a/tags/密码/index.html
+++ b/tags/密码/index.html
@@ -470,7 +470,7 @@
48k
+ 48.3k
diff --git a/tags/小米/index.html b/tags/小米/index.html
index 847fe4a1..03160696 100644
--- a/tags/小米/index.html
+++ b/tags/小米/index.html
@@ -522,7 +522,7 @@
48k
+ 48.3k
diff --git a/tags/微信/index.html b/tags/微信/index.html
index cfdbbb4b..6cda3c2c 100644
--- a/tags/微信/index.html
+++ b/tags/微信/index.html
@@ -470,7 +470,7 @@
48k
+ 48.3k
diff --git a/tags/拒绝服务攻击/index.html b/tags/拒绝服务攻击/index.html
index 6e42156f..19f4318f 100644
--- a/tags/拒绝服务攻击/index.html
+++ b/tags/拒绝服务攻击/index.html
@@ -470,7 +470,7 @@
48k
+ 48.3k
diff --git a/tags/数据库/index.html b/tags/数据库/index.html
index a2c46913..420405a8 100644
--- a/tags/数据库/index.html
+++ b/tags/数据库/index.html
@@ -496,7 +496,7 @@
48k
+ 48.3k
diff --git a/tags/数据挖掘/index.html b/tags/数据挖掘/index.html
index 3b537751..888dc4e2 100644
--- a/tags/数据挖掘/index.html
+++ b/tags/数据挖掘/index.html
@@ -470,7 +470,7 @@
48k
+ 48.3k
diff --git a/tags/文件格式/index.html b/tags/文件格式/index.html
index 573a52b5..5bf1fd74 100644
--- a/tags/文件格式/index.html
+++ b/tags/文件格式/index.html
@@ -496,7 +496,7 @@
48k
+ 48.3k
diff --git a/tags/模型实现/index.html b/tags/模型实现/index.html
index bc057329..e3dcdc93 100644
--- a/tags/模型实现/index.html
+++ b/tags/模型实现/index.html
@@ -470,7 +470,7 @@
48k
+ 48.3k
diff --git a/tags/模糊测试/index.html b/tags/模糊测试/index.html
index 030b3e73..39057400 100644
--- a/tags/模糊测试/index.html
+++ b/tags/模糊测试/index.html
@@ -307,7 +307,7 @@
- AFL初次实践
+ AFL-爱之初体验
@@ -496,7 +496,7 @@
48k
+ 48.3k
diff --git a/tags/破解/index.html b/tags/破解/index.html
index 6dbb50b3..d8c96e02 100644
--- a/tags/破解/index.html
+++ b/tags/破解/index.html
@@ -470,7 +470,7 @@
48k
+ 48.3k
diff --git a/tags/自然语言处理/index.html b/tags/自然语言处理/index.html
index 2281f4fd..e102eecb 100644
--- a/tags/自然语言处理/index.html
+++ b/tags/自然语言处理/index.html
@@ -470,7 +470,7 @@
48k
+ 48.3k
diff --git a/tags/访问控制/index.html b/tags/访问控制/index.html
index 049efd31..ccd9d248 100644
--- a/tags/访问控制/index.html
+++ b/tags/访问控制/index.html
@@ -470,7 +470,7 @@
48k
+ 48.3k
diff --git a/tags/路由器/index.html b/tags/路由器/index.html
index debe9779..7f6ee5f6 100644
--- a/tags/路由器/index.html
+++ b/tags/路由器/index.html
@@ -470,7 +470,7 @@
48k
+ 48.3k
diff --git a/tags/远程执行/index.html b/tags/远程执行/index.html
index f01c5f59..8e1f613b 100644
--- a/tags/远程执行/index.html
+++ b/tags/远程执行/index.html
@@ -470,7 +470,7 @@
48k
+ 48.3k
diff --git a/tags/逆向/index.html b/tags/逆向/index.html
index 94cfd741..5a1258bf 100644
--- a/tags/逆向/index.html
+++ b/tags/逆向/index.html
@@ -470,7 +470,7 @@
48k
+ 48.3k
diff --git a/tags/重放攻击/index.html b/tags/重放攻击/index.html
index 6aca157d..8d4029a8 100644
--- a/tags/重放攻击/index.html
+++ b/tags/重放攻击/index.html
@@ -470,7 +470,7 @@
48k
+ 48.3k


