dolphin attack
This commit is contained in:
@ -20,7 +20,7 @@ https://zhuanlan.zhihu.com/p/29306026
|
||||
|
||||
关键字:语音可控系统,语音识别,MEMS麦克风,安全分析,防御
|
||||
|
||||
## 0x01 Introduction
|
||||
## 1 Introduction
|
||||
|
||||
语音识别(SR)技术允许机器或程序识别口语单词并将其转换为机器可读格式。 由于它的可访问性,效率以及最近在识别精度方面的进步,它已成为越来越流行的人机交互机制。 结果,语音识别系统已将各种各样的系统变成语音可控系统(VCS):Apple Siri [5]和Google Now [21]允许用户通过语音发起电话呼叫; Alexa [4]已使用户能够指示Amazon Echo订购外卖,安排Uber骑行等。随着研究人员将大量精力投入到改善SR系统的性能上,人们对语音识别和语音的了解程度却鲜为人知。 可控系统在故意和偷偷摸摸的攻击下表现良好。
|
||||
先前的工作[10、61]已经表明,SR系统可以理解人类难以理解的混淆语音命令,因此可以控制系统而不会被检测到。 这些语音命令虽然是“隐藏的”,但仍然可以听见并且仍然很明显。 本文旨在研究难以检测到的攻击的可行性,并且本文受到以下关键问题的驱动:语音命令是否可以被人听不见,而仍然可以被设备听见,并且可以被语音识别系统理解? 注入一系列听不见的语音命令是否会导致语音可控系统出现未注意到的安全漏洞? 为了回答这些问题,我们设计了DolphinAttack,这是一种通过利用超声通道(即f> 20 kHz)和基础音频硬件的漏洞在VCS处注入听不见的语音命令的方法。
|
||||
@ -41,7 +41,7 @@ https://zhuanlan.zhihu.com/p/29306026
|
||||
•我们证明了对手可以注入一系列听不见的语音命令来激活始终在线的系统并实现各种恶意攻击。 经过测试的攻击包括在iPhone上启动Facetime,在Amazon Echo上播放音乐以及操纵奥迪汽车中的导航系统。
|
||||
•我们建议同时使用基于硬件和基于软件的防御策略来减轻攻击,并提供增强语音可控系统安全性的建议。
|
||||
|
||||
## 0x02 背景和威胁模型
|
||||
## 2 背景和威胁模型
|
||||
|
||||
在本节中,我们介绍流行的语音可控系统,并以MEMS麦克风为重点讨论它们的体系结构。
|
||||

|
||||
@ -59,7 +59,7 @@ https://zhuanlan.zhihu.com/p/29306026
|
||||

|
||||
语音捕获子系统中的麦克风,低通滤波器(LPF)和ADC旨在捕获可听声音,所有这些功能都旨在抑制超出可听声音频率范围(即20 Hz至20 kHz)的信号。 根据数据表,麦克风的灵敏度频谱在20 Hz至20 kHz之间,理想情况下,应过滤任何其他频率范围内的信号。 即使麦克风记录了高于20 kHz的信号,LPF也应将其删除。 最后,ADC的采样率通常为44.1 kHz,根据奈奎斯特采样定理,数字化信号的频率被限制在22 kHz以下。
|
||||
|
||||
### 2.3威胁模型
|
||||
### 2.3 威胁模型
|
||||
|
||||
攻击者的目标是在用户不知情的情况下将语音命令注入到语音可控系统中,并执行未经身份验证的操作。我们假设对手无法直接访问目标设备,拥有自己的传输声音信号的设备,并且无法要求所有者执行任何任务。
|
||||
|
||||
@ -68,7 +68,7 @@ https://zhuanlan.zhihu.com/p/29306026
|
||||
* 听不见。由于对手的目标是在不被检测到的情况下注入语音命令,因此她将使用人类听不到的声音,即超声波(f> 20 kHz)。请注意,我们没有使用高频声音(18 kHz <f <20 kHz),因为它们仍然可以被孩子听到。
|
||||
* 攻击装备。我们假设对手既可以获取用于发射超声波的扬声器,也可以获取用于播放声音的商品设备。攻击者在目标设备附近。例如,她可能会在受害人的桌子或家附近秘密地留下一个可远程控制的扬声器。或者,她可能在受害者走动时携带便携式扬声器。
|
||||
|
||||
## 0x03 可行性分析
|
||||
## 3 可行性分析
|
||||
|
||||
DolphinAttack的基本思想是(a)在空中传输之前在超声载波上调制低频语音信号(即基带),以及(b)在接收器处用语音捕获硬件对调制后的语音信号进行解调。由于我们无法控制语音捕获硬件,因此我们必须以一种可以使用语音捕获硬件将其解调为基带信号的方式来调制信号。假设麦克风模块始终利用LPF抑制不想要的高频信号,则解调应在LPF之前完成。
|
||||
由于语音捕获硬件的信号路径从麦克风,一个或多个放大器LPF到ADC开始,因此解调的潜在组件是麦克风和放大器。我们研究了完成DolphinAttack的原理。尽管诸如放大器之类的电子组件被设计为线性的,但实际上它们表现出非线性。利用这种非线性特性,电子元件能够创建新的频率[25]。尽管已经报道并利用了放大器模块的非线性,但包括ECM麦克风和MEMS麦克风在内的麦克风是否具有这种特性仍是未知的。
|
||||
@ -91,11 +91,11 @@ DolphinAttack的基本思想是(a)在空中传输之前在超声载波上调
|
||||
|
||||
考虑到麦克风模块非线性效应的理论计算及其对调制后输入信号的影响,在本节中,我们将验证对真实麦克风的非线性效应。我们测试两种类型的麦克风:ECM和MEMS麦克风。
|
||||
|
||||
3.2.1 实验设置
|
||||
#### 3.2.1 实验设置
|
||||
实验设置如图5所示。我们使用iPhone SE智能手机生成2 kHz语音控制信号,即基带信号。然后将基带信号输入到矢量信号发生器[57],该信号发生器将基带信号调制到载波上。经功率放大器放大后,调制信号由高质量的全频带超声扬声器Vifa传输[9]。请注意,我们选择的载波范围为9 kHz至20 kHz,因为信号发生器无法生成低于9 kHz频率的信号。
|
||||
在接收器端,我们测试了从耳机中提取的ECM麦克风和ADMP401 MEMS麦克风[16]。如图5所示,ADMP401麦克风模块包含一个前置放大器。为了了解麦克风的特性,我们测量了麦克风而不是前置放大器输出的信号。
|
||||
|
||||
3.2.2 结果
|
||||
#### 3.2.2 结果
|
||||
我们使用两种信号来研究非线性:单音和多音语音。
|
||||
单音: 图4显示了当我们使用20 kHz载波时的结果,这证实了麦克风的非线性有助于解调基带信号。前两个图显示了来自扬声器的原始信号的时域和频域,从而很好地显示了载波频率(20 kHz)和上边带以及下边带(20±2 kHz)。第二行中的两个图显示了来自MEMS麦克风的输出信号,下面两个图显示了来自ECM麦克风的输出信号。即使信号被衰减,尤其是对于ECM麦克风,两个麦克风在频域中的基带(2 kHz)仍能证实解调成功。请注意,频域图包含多个高频谐波,这些谐波将被LPF过滤,并且不会影响语音识别。
|
||||
|
||||
@ -108,11 +108,11 @@ DolphinAttack的基本思想是(a)在空中传输之前在超声载波上调
|
||||
|
||||
DolphinAttack利用听不见的语音注入来静默控制VCS。由于攻击者几乎无法控制VCS,因此成功进行攻击的关键是在攻击发送方生成听不见的语音命令。特别是,DolphinAttack必须为VCS的激活和识别阶段生成语音命令的基带信号,对基带信号进行调制,以便可以在VCS上对其进行有效解调,并设计一种可以在任何地方启动DolphinAttack的便携式发射机。 DolphinAttack的基本构建模块如图7所示,我们将在以下小节中讨论这些细节。在不失一般性的前提下,我们通过使用Siri作为案例研究来讨论设计细节,并且该技术可以轻松地应用于其他SR系统(例如Google Now,HiVoice)。
|
||||
|
||||
### 4.1语音命令生成
|
||||
### 4.1 语音命令生成
|
||||
|
||||
Siri的工作分为两个阶段:激活和识别。它在接受语音命令之前需要激活,因此我们生成两种类型的语音命令:激活命令和常规控制命令。为了控制VCS,DolphinAttack必须在注入常规控制命令之前生成激活命令。
|
||||
|
||||
4.1.1 激活命令生成。
|
||||
#### 4.1.1 激活命令生成
|
||||
成功的激活命令必须满足两个要求:(a)包含唤醒词“ Hey Siri”,以及(b)调成接受Siri训练的用户的特定语音。创建具有这两个要求的激活命令具有挑战性,除非攻击者在附近并设法创建清晰的记录时用户碰巧说“ Hey Siri”。实际上,攻击者最多可以偶然记录任意单词。如果可能的话,使用现有的语音合成技术[38]和从录音中提取的特征来生成特定语音的“嘿Siri”是极其不同的,因为目前尚不清楚Siri使用哪些特征集进行语音识别。因此,我们设计了两种方法来分别针对两种情况生成激活命令:(a)攻击者找不到Siri的所有者(例如,攻击者获得了被盗的智能手机),以及(b)攻击者可以获得一些录音主人的声音。
|
||||
(1)基于TTS的蛮力。 TTS技术的最新进展使将文本转换为语音变得容易。 因此,即使攻击者没有机会从用户那里获得任何语音记录,攻击者也可以通过TTS(文本到语音)系统生成一组包含唤醒词的激活命令。 观察到的启发是,具有相似声调的两个用户可以激活另一个人的Siri。 因此,只要集合中的激活命令之一具有与所有者足够接近的声音,就足以激活Siri。 在DolphinAttack中,我们借助现有的TTS系统(如表1所示)准备了一组具有各种音调和音色的激活命令,其中包括Selvy Speech,Baidu,Google等。总共,我们获得了90种类型的TTS 声音。 我们选择Google TTS语音来训练Siri,其余的用于攻击
|
||||
|
||||
@ -121,10 +121,10 @@ Siri的工作分为两个阶段:激活和识别。它在接受语音命令之
|
||||
|
||||

|
||||
|
||||
4.1.2 通用控制命令生成。
|
||||
#### 4.1.2 通用控制命令生成
|
||||
常规控制命令可以是启动应用程序(例如,“拨打911”,“打开www.google.com”)或配置设备(例如,“开启飞行模式”)的任何命令。与激活命令不同,SR系统不会验证控制命令的身份。因此,攻击者可以选择任何控制命令的文本,并利用TTS系统生成命令。
|
||||
|
||||
4.1.3 评估。
|
||||
#### 4.1.3 评估
|
||||
我们测试激活和控制命令。在不失一般性的前提下,我们通过利用Tab中总结的TTS系统生成激活和控制命令。 1.特别是,我们从这些TTS系统的网站上下载了两个语音命令:“ Hey Siri”和“ call 1234567890”。对于激活,我们使用Google TTS系统中的“ Hey Siri”来训练Siri,其余的用于测试。我们通过iPhone 6 Plus和台式设备播放语音命令(如图5所示),并在iPhone 4S上进行测试。选项卡中汇总了这两个命令的激活和识别结果。结果表明,SR系统可以识别来自任何TTS系统的控制命令。在89种类型的激活命令中,有35种可以激活Siri,成功率为39%。
|
||||
|
||||
|
||||
@ -132,7 +132,7 @@ Siri的工作分为两个阶段:激活和识别。它在接受语音命令之
|
||||
|
||||
生成语音命令的基带信号后,我们需要在超声载波上对其进行调制,以使它们听不到。 为了利用麦克风的非线性,DolphinAttack必须利用幅度调制(AM)。
|
||||
|
||||
4.2.1 AM调制参数。
|
||||
#### 4.2.1 AM调制参数
|
||||
在AM中,载波的幅度与基带信号成比例地变化,并且幅度调制产生一个信号,其功率集中在载波频率和两个相邻的边带上,如图9所示。 描述如何在DolphinAttack中选择AM参数。
|
||||
(1)深度:调制深度m定义为m = M / A,其中A是载波幅度,M是调制幅度,即,M是幅度从其未调制值起的峰值变化。 例如,如果m = 0.5,则载波幅度在其未调制电平之上(或之下)变化50%。 调制深度与麦克风非线性效应的利用直接相关,我们的实验表明,调制深度与硬件有关(在第5节中有详细介绍)。
|
||||
(2)载波频率。载波频率的选择取决于几个因素:超声波的频率范围,基带信号的带宽,低通滤波器的截止频率以及VCS上麦克风的频率响应以及频率攻击者的回应。调制信号的最低频率应大于20 kHz,以确保听不见。假设语音命令的频率范围为w,则载波频率fc必须满足fc-w> 20 kHz的条件。例如,假设基带的带宽为6 kHz,则载波频率必须大于26 kHz,以确保最低频率大于20 kHz。人们可能会考虑使用20 kHz以下的载波,因为这些频率对于大多数人来说是听不到的,除了小孩。但是,这样的载波(例如,<20kHz)将无效。这是因为,当载波频率和下边带低于低通滤波器的截止频率时,它们将不会被滤波。因此,恢复的语音不同于原始信号,并且语音识别系统将无法识别命令。 类似于许多电子设备,麦克风是频率选择性的,例如,各种频率下的增益会变化。为了提高效率,载波频率应是扬声器和VCS麦克风上增益最高的乘积。为了发现最佳载波频率,我们测量扬声器和麦克风的频率响应,即,在相同的激励下,我们测量各种频率下的输出幅度。图10显示了Samsung Galaxy S6 Edge 3上的ADMP 401 MEMS麦克风和扬声器的频率响应。麦克风和扬声器的增益不一定随频率的增加而降低,因此有效载波频率可能不会单调。
|
||||
@ -146,10 +146,10 @@ Siri的工作分为两个阶段:激活和识别。它在接受语音命令之
|
||||
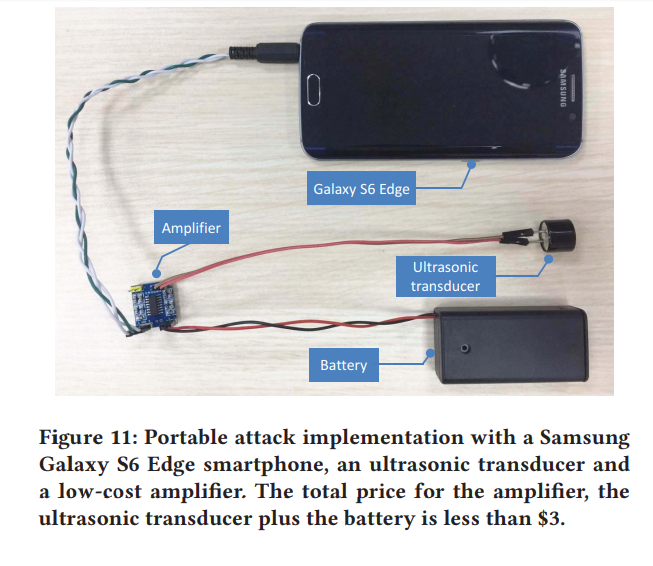
我们设计了两个发射器:(a)由专用信号发生器驱动的强大发射器(如图5所示),以及(b)由智能手机驱动的便携式发射器(如图11所示)。 我们利用第一个来验证和量化DolphinAttack可以完成各种听不见的语音命令的程度,而我们使用第二个来验证步行攻击的可行性。 这两个发射机均由三个组件组成:信号源,调制器和扬声器。 信号源产生原始语音命令的基带信号,并输出到调制器,该调制器以幅度调制(AM)的形式将语音信号调制到频率为fc的载波上。 最后,扬声器将调制后的信号转换成声波,并请注意扬声器的采样率必须大于2(fc + w),以避免信号混叠。
|
||||
|
||||
|
||||
4.3.1 具有信号发生器的强大变送器
|
||||
#### 4.3.1 具有信号发生器的强大变送器
|
||||
我们将智能手机用作信号源,并将图5中描述的矢量信号发生器用作调制器。请注意,信号发生器的采样范围为300 MHz,远大于超声频率,并且可以使用预定义的参数调制信号。功能强大的发射器的扬声器是名为Vifa [9]的宽带动态超声扬声器。
|
||||
|
||||
4.3.2 带有智能手机的便携式变送器
|
||||
#### 4.3.2 带有智能手机的便携式变送器
|
||||
便携式发射器利用智能手机来发射调制信号。因为我们发现许多设备的最佳载波频率都大于24 kHz,如表3所示。 大多数智能手机无法完成任务。大多数智能手机最多支持48 kHz采样率,并且只能发送载波频率最高为24 kHz的调制窄带信号。为了构建适用于各种VCS的便携式发射器,我们购买了三星Galaxy S6 Edge,它支持高达192 kHz的采样率。不幸的是,三星Galaxy S6的车载扬声器会衰减频率大于20 kHz的信号。为了减轻这个问题,我们使用窄带超声换能器[56]作为扬声器,并在超声换能器之前添加了一个放大器,如图11所示。这样,有效的攻击范围得以扩展。
|
||||

|
||||
|
||||
@ -194,7 +194,8 @@ Tab. 3总结实验结果。 从Tab. 3所示,我们可以得出结论,Dolphin
|
||||
**命令很重要:** 语音命令的长度和内容会影响成功率和最大攻击距离。 在实验中,我们严格要求要求正确识别命令中的每个单词,尽管某些命令可能不需要这样做。 例如,“呼叫/ FaceTime 1234567890”和“打开dolphinattack.com”比“打开飞机模式”或“今天的天气如何”更难被识别。 在前一种情况下,必须正确识别执行字“ call”,“ open”和内容(数字,url)。 但是,对于后一种情况,仅识别诸如“飞机”和“天气”之类的关键字就足以执行原始命令。 如果攻击命令简短且对于SR系统通用,则可以提高攻击性能。
|
||||
**载波频率:** fc是影响攻击成功率的主要因素,并且在各个设备之间也显示出很大的差异。对于某些设备,成功进行识别攻击的fc范围可以宽至20-42 kHz(例如iPhone 4s),也可以窄至几个单个频率点(例如iPhone 5s)。我们将这种多样性归因于这些麦克风的频率响应和频率选择性的差异以及音频处理电路的非线性。例如,Nexus 7的fc范围是从24到39 kHz,这可以从两个方面进行解释。 fc不高于39 kHz,因为Vifa扬声器在39 kHz以上的频率响应较低,而Nexus 7麦克风之一也较低。因此,结合起来,高于39 kHz的载波不再足够有效以注入听不见的语音命令。由于麦克风频率响应的非线性,fc不能小于24 kHz。我们观察到,当基带谐波的幅度大于基带之一时,无法听到的语音命令对于SR系统变得不可接受。例如,在给定400 Hz音调的基带的情况下,我们测量Nexus 7上的解调信号(即400 Hz基带),并观察800 Hz(2次谐波),1200 Hz(3次谐波)甚至更高的谐波,这可能是由于音频处理电路的非线性所致。如图12所示,当fc小于23 kHz时,第二和第三谐波要强于第一谐波,这会使基带信号失真并使SR系统难以识别。导致最佳攻击性能的Prime fc是既显示高基带信号又显示低谐波的频率。在Nexus 7上,Prime fc为24.1 kHz
|
||||

|
||||
**调制深度:** 调制深度会影响解调后的基带信号的幅度及其谐波,如图13所示。随着调制深度从0%逐渐增加到100%,解调后的信号会变得更强,进而提高SNR和攻击成功率, 除少数例外(例如,当谐波使基带信号失真的程度大于AM深度较低的情况时)。 我们在Tab 3 中报告了对每台设备成功进行识别攻击的最小深度。
|
||||

|
||||
**调制深度:** 调制深度会影响解调后的基带信号的幅度及其谐波,如图13所示。随着调制深度从0%逐渐增加到100%,解调后的信号会变得更强,进而提高SNR和攻击成功率, 除少数例外(例如,当谐波使基带信号失真的程度大于AM深度较低的情况时)。 我们在Tab 3 中报告了对每台设备成功进行识别攻击的最小深度。
|
||||
攻击距离: 攻击距离从2厘米到最大175厘米不等,并且跨设备差异很大。 值得注意的是,我们在Amazon Echo上两次攻击都可以达到的最大距离为165厘米。 我们认为,可以使用可以产生更高压力水平的声音并表现出更好的声音指向性的设备来增加距离,或者使用更短和更易于识别的命令来增加距离。
|
||||
**努力与挑战:**在进行上述实验时,我们面临挑战。 除了获取设备以外,由于缺少音频测量反馈界面,因此测量每个参数非常耗时且费力。 例如,为测量Prime fc,我们使用不同平台上的音频频谱分析软件在各种设备上分析解调结果:iOS [30],macOS [34],Android [41]和Windows [35]。 对于不支持安装频谱软件的设备(例如Apple Watch和Amazon Echo),我们利用呼叫和命令日志回放功能,并在另一台中继设备上测量音频。
|
||||
|
||||
@ -254,7 +255,7 @@ Tab. 3总结实验结果。 从Tab. 3所示,我们可以得出结论,Dolphin
|
||||
* 配备传感器的设备的安全性。配备有各种传感器的商业设备(例如,智能手机,可穿戴设备和平板电脑)正在逐渐普及。随着无处不在的移动设备的增长趋势,安全性成为人们关注的焦点。许多研究人员[14、15、46、60]专注于研究对智能设备上的传感器的可能攻击。其中,传感器欺骗(即,将恶意信号注入受害者传感器)引起了广泛关注,并被认为是对配备传感器的设备的最严重威胁之一。 Shin等。将传感器欺骗攻击[46]分为三类:常规信道攻击(重放攻击)[19、26、66],传输信道攻击和侧信道攻击[11、14、15、47、49]。 Dean等。 [14,15]证明,当声频分量接近陀螺仪传感质量的共振频率时,MEMS陀螺仪容易受到大功率高频声噪声的影响。利用机载传感器,Gu等。 [24]设计了一种使用振动马达和加速度计的加密密钥生成机制。我们的工作重点是麦克风,可以将其视为一种传感器。
|
||||
* 通过传感器泄露隐私。 Michalevsky等。 [36]利用MEMS陀螺仪来测量声学信号,从而揭示扬声器信息。 Schlegel等。 [44]设计了一种木马程序,可以从智能手机的音频传感器中提取高价值数据。 Owusu等。 [40]利用加速度计的读数作为副通道,在智能手机触摸屏键盘上提取输入文本的整个序列,而无需特殊的特权。 Aviv等。 [6]证明了加速度传感器可以揭示用户的点击和基于手势的输入。 Dey等。 [17]研究了如何利用车载加速度计的缺陷对智能手机进行指纹识别,并且指纹可以用作识别智能手机所有者的标识符。西蒙等。 [48]利用摄像机和麦克风来推断在智能手机的仅数字软键盘上输入的PIN。 Li等。文献[33]可以根据照片中的阴影和相机的传感器读数,通过估计太阳位置来验证照片的捕获时间和位置。 Sun等。 [55]提出了一个视频辅助按键推论框架,以从平板电脑动作的秘密视频记录中推断出平板电脑用户的输入。 Backes等。 [7]显示,可以根据打印机的声音恢复处理英语的点阵打印机正在打印的内容。同样,我们研究了如何利用麦克风漏洞来破坏安全和隐私。罗伊等。 [42]提出了BackDoor,它在超声频带上的两个扬声器和麦克风之间建立了一个声音(但听不见)通信通道。特别是,BackDoor利用两个超声波扬声器传输两个频率。通过麦克风的非线性振膜和功率放大器后,这两个信号在可听频率范围内产生一个“阴影”,可以携带数据。但是,“阴影”是单一音调,而不是由丰富音调集组成的语音命令。相比之下,我们表明可以使用一个扬声器向SR系统注入听不见的命令,从而引起各种安全和隐私问题。
|
||||
|
||||
## 海豚攻击”的局限性分析
|
||||
## 9 海豚攻击”的局限性分析
|
||||
|
||||
上面谈到了“海豚攻击”实现的基本原理。但是经过我们的分析,这种“漏洞”虽然理论上存在风险,但是实现代价较大,且整体可行性较低,大家不必过于恐惧。下面我们再来分析一下它能实现的效果的局限性:
|
||||
|
||||
@ -271,6 +272,6 @@ Tab. 3总结实验结果。 从Tab. 3所示,我们可以得出结论,Dolphin
|
||||
|
||||
|
||||
|
||||
## 9 结论
|
||||
## 10 结论
|
||||
|
||||
在本文中,我们提出了DolphinAttack,这是对SR系统的听不见的攻击。 DolphinAttack利用AM(振幅调制)技术来调制超声载波上的可听语音命令,从而使人无法感知命令信号。攻击者可以使用DolphinAttack攻击主要的SR系统,包括Siri,Google Now,Alexa等。为避免实际滥用DolphinAttack,我们从硬件和软件两个方面提出了两种防御解决方案。
|
||||
|
||||
Reference in New Issue
Block a user